Use Case: Monitoring an E-Commerce Customer Support Chatbot
Scenario
An e-commerce company uses an AI-powered chatbot to assist customers with browsing products, answering questions, processing orders, and providing customer support. The company wants to ensure that the chatbot performs optimally, delivers accurate responses, and maintains a seamless customer experience, all while safeguarding customer data and delivering the service at an optimal cost.
Challenges
- Performance issues. The chatbot may experience error and latency spikes, reducing the user experience quality (e.g., slow response times when customers are browsing products or checking order status).
- Cost overruns. Each interaction with the chatbot consumes a certain amount of tokens, which contribute to operational costs. For example, lengthy and complex queries may lead to excessive token consumption.
- Data privacy. The chatbot may inadvertently expose sensitive data, such as customer details or payment information, either in its responses or interactions with third-party services.
- Security stance. The company wants to monitor its chatbot's security posture to detect LLM calls with security issues.
Let’s see how our AI observability solution can help.
Integrate your chatbot application
Refer to the Getting Started and Setup documents for details on how to bring your chatbot app into Coralogix.
Note
Follow the Getting Started guide to try out the AI Center using code samples. This lets you experiment safely before connecting your actual production application.
Monitor the health of your chatbot app
- In the Coralogix UI, navigate to AI Center > Application Catalog.
- Scroll down to the application grid and click on the chatbot app row to display its Application Overview page.
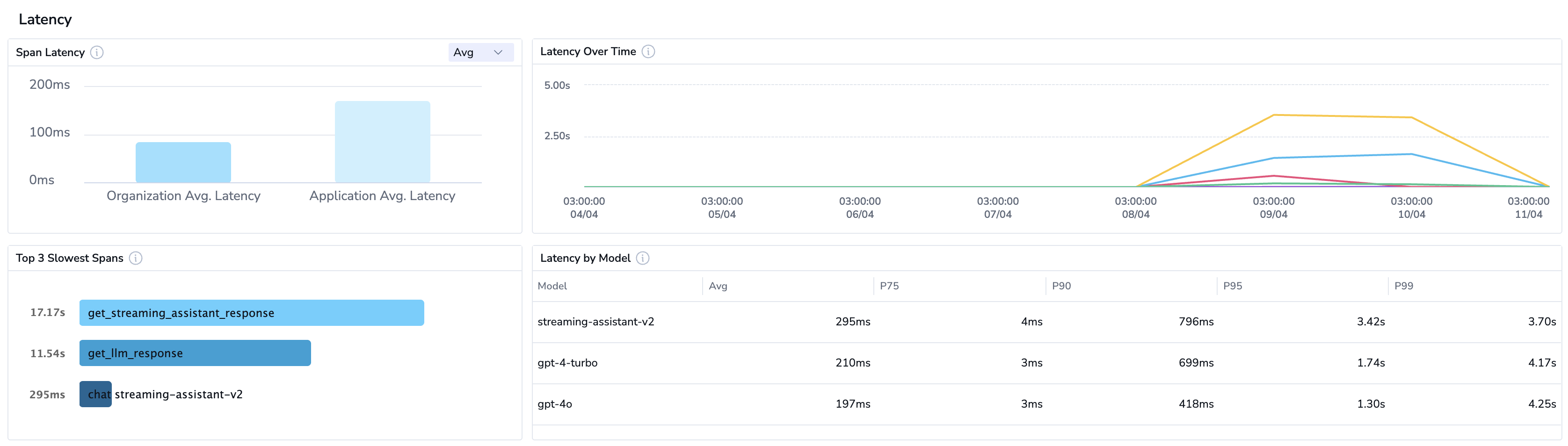
Examine the Errors metrics to verify that the error rate is low. For most professional or customer-facing AI chatbots, an error rate under 5% is often considered a good target. This means that the chatbot should be accurate and provide helpful responses in over 95% of cases.

Check the average span latency to assess the delays between a user's request initiation and the LLM's response. The goal is to keep latency under 1 second. This ensures the chatbot responds quickly enough that users feel the conversation is nearly instantaneous.
Optimize the chatbot cost
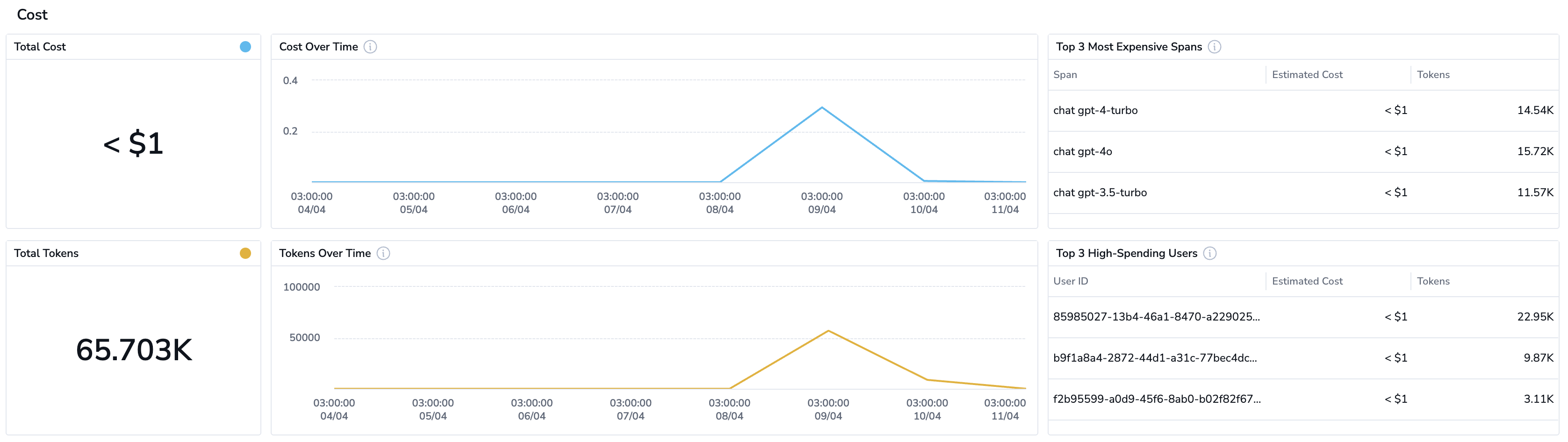
On the Application Overview page, monitor the Cost dashboard to identify high-cost interactions. For instance, if certain queries are consuming excessive tokens, optimize these responses or explore more efficient models.
Prevent PII leakage
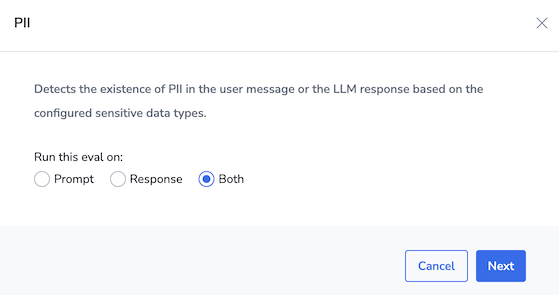
Ensure that no Personally Identifiable Information (PII) is exposed through chatbot interactions by using our pre-built PII eval to detect and prevent sensitive data leakage.
In the Eval Catalog (AI Center > Eval Catalog), locate the PII eval, configure it to run on user prompts and LLM responses, and add it to your chatbot app.
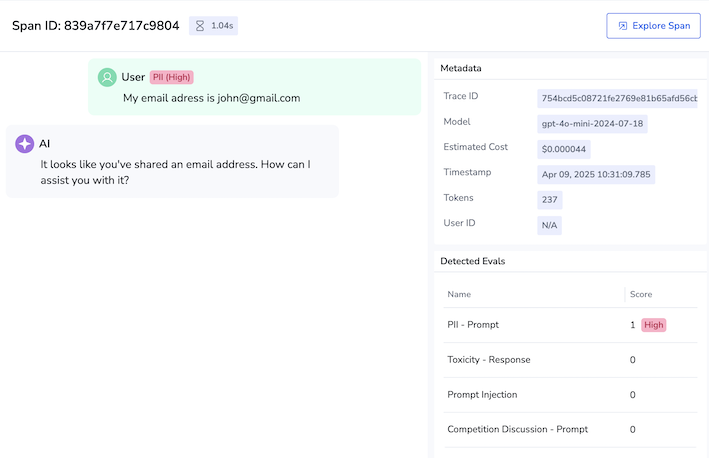
If sensitive data is detected in chatbot interactions, you’ll see a spike in the Issues over Time chart on the Application Overview page.

In addition, the corresponding entry will be displayed on the LLM Calls page (AI Center > Application Catalog > Your chatbot app > LLM Calls). The entry is flagged as having high-security risk score.

Click the span row to display its details.
- Review the complete user-to-LLM interaction to pinpoint the offending segment.
Outcome
With AI observability in place, you can proactively maintain chatbot performance, reduce operational costs, and ensure a safe, helpful support experience for your customers.