Alerting Techniques for an Observable Platform
Observable and secure platforms use three connected data sets: logs, metrics, and traces. Platforms can link these data to alerting systems to notify system administrators when…

Stateful, commonly monolithic, and absolutely fundamental to system design, the quality of your database administration and operation is a key determinant of your overall success. Databases are the cornerstone of modern architecture, requiring constant effort, investigation, and iteration to get the most out of a database. This makes it all the more terrifying when an outage occurs.
When a database outage occurs, it typically comes with a few serious risks:
These additional complications can cloud the initial database outage and make it difficult to understand the chain of events that have led up to the present situation. Databases require constant changes to ensure they are performing, and herein lies our challenge.
How do we constantly change something that carries the highest risk of breaking, and often leads to the most complex outages?
The big problem with database changes is that, often, the impact on the database isn’t the first indicator that something is wrong. For example, if we migrate the scheme of a SQL database, the database itself may report that everything is fine, but the downstream applications may report an issue.
Likewise, if a migration fails, an engineer may perform a rollback and assume all is well, and only later on will a downstream application fail. This means that the relationship between cause and effect isn’t clear, and relying only on siloed alerting isn’t enough.
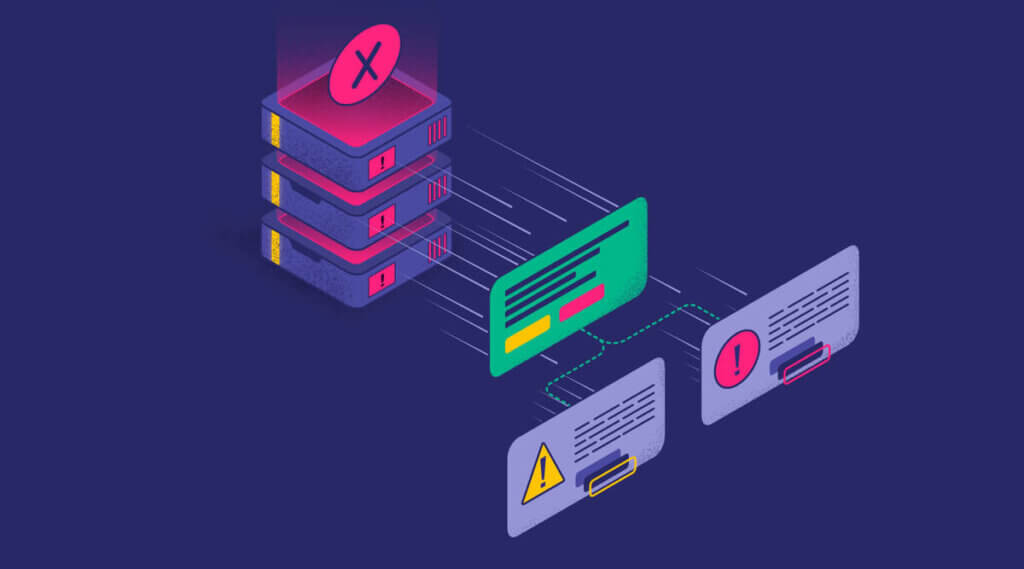
A siloed alert is an alert that can only focus on one metric attached to one single part of a system, for example, the CPU on a database. These alerts are a necessary part of your observability, but they aren’t the end of it. They are building bricks, but like real bricks, they need to be assembled and joined together to become something more.
We need a solution that ties the siloed events into a single, continuous alert that can span across multiple data types, such as logs, metrics, traces or security data, and components, such as databases and applications.
This is where Flow Alerts come in. With Flow Alerts, you can link your individual alerts into a single, coherent story that captures the full context of an event through your system, breaking the data silo in your observability platform.
Flow alerts allow you to link disparate events in many applications over multiple data sources. For example, the following flow alert detects error logs from a database migration. Then, it looks for any one of the following to happen within 1 hour:

This means that when the alert triggers, it won’t be a series of disparate alarms, indicating that multiple applications that have nothing directly to do with one another are broken. Instead, there will be a clear message – the database is broken, and here are the downstream impacts.
Flow alerts are a unique feature of the Coralogix platform that allows you to reach across all of your observability data and define alerts around any metric you want. This allows you to accurately describe the conditions of an outage, whether it’s a single event or a complex chain of logically dependent variables.

Observable and secure platforms use three connected data sets: logs, metrics, and traces. Platforms can link these data to alerting systems to notify system administrators when…

This article was last updated on June 28, 2023. If you’ve been investigating log monitoring lately, you’ve probably heard of logging agents like Logstash or Fluent…
Coralogix is not just another monitoring or observability platform. We’re using our unique Streama technology to analyze data without needing to index it so teams can…
