Forward AWS Logs via Lambda Shipper

![]()
Overview
This integration guide focuses on connecting your AWS environment to Coralogix using AWS Lambda functions. To complete this integration, you may either use the Coralogix platform UI, CloudFormation templates from AWS, AWS SAM applications, or a dedicated Terraform module from our GitHub repository.
This document details how to complete our predefined Lambda function template to simplify the integration. Your task will be to provide specific configuration parameters, based on the service that you intend to connect to. The reference list for these parameters is provided below.
As we improve coralogix-aws-shipper, we invite you to contribute, ask questions, and report issues in the repository.
Supported services
While coralogix-aws-shipper manages integrations for all listed AWS products, some parameters are specific to individual products. Please refer to the Configuration parameters for product-specific requirements.
Amazon S3, CloudTrail, VPC Flow Logs and more
This integration is based on S3. Your Amazon S3 bucket can receive log files from all kinds of services, such as CloudTrail, VPC Flow Logs, Redshift, Network Firewall or different types of load balancers (ALB/NLB/ELB). The data is then sent to Coralogix for analysis.
You can also incorporate SNS/SQS into the pipeline to trigger the integration upon notification.
Amazon SNS/SQS
A separate integration for SNS or SQS is available. You can receive messages directly from both services to your Coralogix subscription. You will need the ARN of the individual SNS/SQS topic.
Amazon CloudWatch
Coralogix can be configured to receive data directly from your CloudWatch log group.
Amazon Kinesis
Coralogix can be configured to receive data directly from your Kinesis Stream.
Amazon MSK & Kafka
Coralogix can be configured to receive data directly from your MSK or Kafka cluster.
Amazon ECR image security scan
Coralogix can be configured to receive ECR Image Scanning.
Deployment options
Important: Before you begin, make sure your AWS user has the necessary permissions to create Lambda functions and IAM roles.
Integrate using the Coralogix platform (recommended)
The fastest way to deploy your predefined Lambda function is from within the Coralogix platform. Fill out an integration form and confirm the integration from your AWS account. Product integrations can be done by navigating to Data Flow > Integrations in your Coralogix toolbar. For detailed UI instructions, please read the Integration Packages tutorial.
Quick Create a CloudFormation stack
You can always launch the CloudFormation stack by filling out a Quick Create template. This is done from within your AWS Management Console. Log into your AWS account and click the button below to deploy the CloudFormation stack.

If you are using AWS CLI, you can use a CloudFormation template from our repository.
Deploy the AWS serverless application
Alternatively, you can use the SAM deployment link. The procedure is very similar to filling out the Quick Create template.
Terraform module
If you are using Terraform to launch your infrastructure, you can access coralogix-aws-shipper it via our Terraform Module. Use the parameters defined in the repository README, as they more accurately reflect the configuration process.
Configuration parameters
This document explains the basic config options for your template. You will need these values to launch your integration. For additional optional parameters, view the Advanced configuration options.
Use the tables below as a guide to configure your deployment. The configuration variables provided apply to Serverless or CloudFormation deployments. If you plan to use Terraform, the variable requirements differ slightly. Please refer to the Terraform Module for further details.
Universal configuration
Use an existing Coralogix Send-Your-Data API key to make the connection or create one as you fill our pre-made template. Additionally, make sure your integration is Region-specific.
Always deploy the AWS Lambda function in the same AWS region as your resource, such as the S3 bucket.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| Application name | This will also be the name of the CloudFormation stack that creates your integration. It can include letters (A–Z and a–z), numbers (0–9) and dashes (-). | ✅ | |
| IntegrationType | Choose the AWS service that you wish to integrate with Coralogix. Can be one of: S3, CloudTrail, VpcFlow, CloudWatch, S3Csv, SNS, SQS, CloudFront, Kinesis, Kafka, MSK, EcrScan. | S3 | ✅ |
| CoralogixRegion | Your data source should be in the same region as the integration stack. You may choose from one of the default Coralogix regions: [Custom, EU1, EU2, AP1, AP2, AP3, US1, US2]. If this value is set to Custom, you must specify the Custom Domain to use via the CustomDomain parameter. | Custom | ✅ |
| CustomDomain | If you choose a custom domain name for your private cluster, Coralogix will send telemetry from the specified address (e.g. custom.coralogix.com). | ||
| ApplicationName | The name of the application for which the integration is configured. Advanced configuration specifies dynamic value retrieval options. | ✅ | |
| SubsystemName | Specify the name of your subsystem. For a dynamic value, refer to the Advanced configuration section. For CloudWatch, leave this field empty to use the log group name. | ✅ | |
| ApiKey | The Send-Your-Data API key validates your authenticity. This value can be a direct Coralogix API key or an AWS Secret Manager ARN containing the API Key. Note that the parameter expects the API key in plain text or stored in a secret manager. | ✅ | |
| StoreAPIKeyInSecretsManager | Enable this to store your API key securely. Otherwise, it will remain exposed in plain text as an environment variable in the Lambda function console. | True | ✅ |
| ReservedConcurrentExecutions | The number of concurrent executions that are reserved for the function, leave empty so the Lambda will use unreserved account. concurrency. | n/a | |
| LambdaAssumeRoleARN | A role that the Lambda will assume, leave empty to use the default permissions. Note that if this parameter is used, all S3 and ECR API calls from the Lambda will be made with the permissions of the assumed role. | ||
| ExecutionRoleARN | The ARN of a user defined role that will be used as the execution role for the Lambda function. |
EcrScan doesn't require any additional configuration.
Working with roles
In some cases, specialized or more refined IAM permissions are required. The AWS Shipper supports granular IAM control through two parameters:
-
LambdaAssumeRoleARN: Specifies a role ARN, enabling the Lambda function to assume the role. The assumed role will only affect S3 and ECR API calls, as these are the only services invoked by the Lambda function at the code level.
-
ExecutionRoleARN: Specifies the execution role for the AWS Shipper Lambda. The provided role must have basic Lambda execution permissions. Any additional permissions required for the Lambda’s operation will be automatically added during deployment.
Basic Lambda execution role permission:
Statement:
- Effect: "Allow"
Principal:
Service: "lambda.amazonaws.com"
Action: "sts:AssumeRole"
S3, CloudTrail, VpcFlow, S3Csv, CloudFront configuration
This is the most flexible type of integration, as it is based on receiving log files to Amazon S3. First, your bucket can receive log files from all kinds of other services, such as CloudTrail, VPC Flow Logs, Redshift, Network Firewall or different types of load balancers (ALB/NLB/ELB). Once the data is in the bucket, a pre-made Lambda function will then transmit it to your Coralogix account.
The S3 integration supports generic data. You can ingest any generic text, JSON, and CSV data stored in your S3 bucket.
Maintain S3 notifications via SNS or SQS
If you don’t want to send data directly as it enters S3, you can also use SNS/SQS to maintain notifications before any data is sent from your bucket to Coralogix. For this, you need to set the SNSTopicArn or SQSTopicArn parameters.
All resources, such as S3 or SNS/SQS, should be provisioned already. If you are using an S3 bucket as a resource, please make sure it is clear of any Lambda triggers located in the same AWS region as your new function. All resources, such as S3 or SNS/SQS, should be provisioned already. If you are using an S3 bucket as a resource, please make sure it is clear of any Lambda triggers located in the same AWS region as your new function.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| S3BucketName | Comma-separated list of names for the AWS S3 buckets that you want to monitor. | ✅ | |
| S3BucketKMSKeyARN | The ARN of the KMS key used to encrypt/decrypt objects in the specified S3 bucket. If provided, the Lambda policy will include permissions to decrypt using this key. | ||
| S3KeyPrefix | Specify the prefix of the log path within your S3 bucket. This value is ignored if you use the SNSTopicArn/SQSTopicArn parameter. | CloudTrail/VpcFlow 'AWSLogs/' | |
| S3KeySuffix | Filter for the suffix of the file path in your S3 bucket. This value is ignored if you use the SNSTopicArn/SQSTopicArn parameter. | CloudTrail '.json.gz', VpcFlow '.log.gz' | |
| NewlinePattern | Enter a regular expression to detect a new log line for multiline logs. For example, \n(?=\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3}). | ||
| SNSTopicArn | The ARN for the SNS topic that contains the SNS subscription responsible for retrieving logs from Amazon S3. | ||
| SQSTopicArn | The ARN for the SQS queue that contains the SQS subscription responsible for retrieving logs from Amazon S3. | ||
| CSVDelimiter | Specify a single character to be used as a delimiter when ingesting a CSV file with a header line. This value is applicable when the S3Csv integration type is selected, such as, "," or " ". | , |
CloudWatch configuration
Coralogix can be configured to receive data directly from your CloudWatch log group. CloudWatch logs are streamed directly to Coralogix via Lambda. This option does not use S3. You must provide the log group name as a parameter during setup.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| CloudWatchLogGroupName | Provide a comma-separated list of CloudWatch log group names to monitor. For example, (log-group1, log-group2, log-group3). | ✅ | |
| CloudWatchLogGroupPrefix | This parameter expects a string of comma-separated list, of log group prefixes. The code will use these prefixes to create permissions for the Lambda instead of creating for each log group permission it will use the prefix with a wild card to give the Lambda access for all of the log groups that start with these prefix. This parameter doesn't replace the CloudWatchLogGroupName parameter. For more information, refer to the Note below. | ||
| EnableLogGroupTags | Enable fetching and including CloudWatch log group tags in log metadata. When enabled, tags are automatically fetched and stored as cw.tags metadata. Tags are cached with a configurable TTL to optimize API calls. | false | |
| LogGroupTagsCacheTTLSeconds | Time-to-live (in seconds) for the log group tags cache. Tags are cached to reduce API calls. Set to 0 to disable caching. Transient errors are not cached, allowing immediate retry on the next invocation. | 300 |
If your log group name is longer than 70, the Lambda function you will see the permission for that log group as: allow-trigger-from-<the log group first 65 characters and the last 5 characters>. This is because of length limit in AWS for permission name.
The CloudWatchLogGroupName parameter will get a list of log groups and then add them to the Lambda as triggers, each log group will also add permission to the Lambda, in some cases when there are a lot of log groups this will cause an error because the code
tries to create too many permissions for the Lambda (AWS have a limitation for the number of permission that you can have for a Lambda), and this is why we have the CloudWatchLogGroupPrefix parameter, this parameter will add only permission to the Lambda
using a wildcard( * ).for example, in case I have the log groups: log1,log2,log3 instead that the code will create for each of the log group permission to trigger the shipper Lambda then you can set CloudWatchLogGroupPrefix = log, and then it will create
only 1 permission for all of the log groups to trigger the shipper Lambda, but you will still need to set CloudWatchLogGroupName = log1,log2,log3. When using this parameter, you will not be able to see the log groups as triggers for the Lambda.
If you need to add multiple log groups to the Lambda function using regex, refer to our Lambda manager.
SNS configuration
To receive SNS messages directly to Coralogix, use the SNSIntegrationTopicARN parameter. This differs from the previous use of SNSTopicArn, which triggers notifications based on S3 events.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| SNSIntegrationTopicArn | Provide the ARN of the SNS topic to which you want to subscribe for retrieving messages. | ✅ |
SQS configuration
To receive SQS messages directly to Coralogix, use the SQSIntegrationTopicARN parameter. This differs from the previous use of SQSTopicArn, which triggers notifications based on S3 events.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| SQSIntegrationTopicArn | Provide the ARN of the SQS queue to which you want to subscribe for retrieving messages. | ✅ |
Kinesis configuration
We can receive direct Kinesis stream data from your AWS account to Coralogix. Your Kinesis stream ARN is a required parameter in this case.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| KinesisStreamArn | Provide the ARN of the Kinesis stream to which you want to subscribe for retrieving messages. | ✅ |
Kafka configuration
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| KafkaBrokers | Comma-delimited list of Kafka brokers to establish a connection with. | ✅ | |
| KafkaTopic | Subscribe to this Kafka topic for data consumption. | ✅ | |
| KafkaBatchSize | Specify the size of data batches to be read from Kafka during each retrieval. | 100 | |
| KafkaSecurityGroups | Comma-delimited list of Kafka security groups for secure connection setup. | ✅ | |
| KafkaSubnets | Comma-delimited list of Kafka subnets to use when connecting to Kafka. | ✅ |
MSK configuration
Your Lambda function must be in a VPC that has access to the MSK cluster. You can configure your VPC via the provided VPC configuration parameters.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| MSKBrokers | Comma-delimited list of MSK brokers to connect to. | ✅ | |
| KafkaTopic | Comma separated list of Kafka topics to Subscribe to. | ✅ |
Generic configuration (optional)
These parameters are optional and allow you to receive notification emails, exclude specific logs, or control the message sending rate
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| NotificationEmail | A failure notification will be sent to this email. address. | ||
| BlockingPattern | Enter a regular expression to identify lines excluded from being sent to Coralogix. For example, use MainActivity.java:\d{3} to match log lines with MainActivity followed by exactly three digits. | ||
| LogStreamFilter | Regular expression to filter CloudWatch log events by log stream name. Only events from matching streams are shipped to Coralogix. Example: ^develop/ to ship only develop branch logs from Amplify. | ||
| SamplingRate | Send messages at a specific rate, such as 1 out of every N logs. For example, if your value is 10, a message will be sent for every 10th log. | 1 | ✅ |
| AddMetadata | Add AWS event metadata to the log message. Comma-separated values are expected. Options for S3 are bucket_name,key_name. For CloudWatch, use stream_name, loggroup_name . For Kafka/MSK, use topic_name | ||
| CustomMetadata | Add custom metadata to the log message. Comma-separated values are expected. Options are key1=value1,key2=value2 |
Log Stream Filtering Example
AWS Amplify Hosting (SSR/WEB_COMPUTE) writes all branch logs to a single CloudWatch log group (/aws/amplify/<app-id>), with each branch writing to its own log stream using the naming pattern <branch-name>/<instance-id>.
To ship develop branch logs to your Stage Coralogix environment and main branch logs to your Prod environment, deploy two shipper stacks pointing to the same log group but with different filters:
| Stack | LogStreamFilter | Coralogix Environment |
|---|---|---|
| Stage | ^develop/ | Stage |
| Prod | ^main/ | Prod |
This avoids duplicated ingestion - each shipper only processes events from matching streams before sending to Coralogix.
Lambda configuration (optional)
These are the default presets for Lambda. Read Troubleshooting for more information on changing these defaults.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| FunctionMemorySize | Specify the memory size for the Lambda function in megabytes. | 1024 | ✅ |
| FunctionTimeout | Set a timeout for the Lambda function in seconds. | 300 | ✅ |
| LogLevel | Specify the log level for the Lambda function, choosing from the following options: INFO, WARN, ERROR, DEBUG. | WARN | ✅ |
| LambdaLogRetention | Set the CloudWatch log retention period (in days) for logs generated by the Lambda function. | 5 | ✅ |
| FunctionRunTime | Select the runtime type for the Lambda. Allowed values are provided.al2023 or provided.al2. | provided.al2023 | ✅ |
| FunctionArchitectures | Define the Lambda function architectures. Allowed values are arm64 or x86_64. | arm64 | ✅ |
VPC configuration (optional)
Use the following options if you need to configure a private link with Coralogix.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| LambdaSubnetID | Specify the ID of the subnet where the integration is to be deployed. | ✅ | |
| LambdaSecurityGroupID | Specify the ID of the Security Group where the integration is to be deployed. | ✅ | |
| UsePrivateLink | Set this to true to use AWS PrivateLink. | false | ✅ |
Metadata
The metadata features decribed below are only available in coralogix-aws-shipper v1.1.0 and later.
The AddMetadata parameter allows you to add metadata to the log message. The metadata is added to the log message as a JSON object. The metadata is specific to the integration type. For example, for S3, the metadata is s3.object.key and s3.bucket. For CloudWatch, the metadata is cw.log.group and cw.log.stream. See table below for full list.
| Integration Type | Metadata Key | Description |
|---|---|---|
| S3 | s3.bucket | The name of the S3 bucket |
| S3 | s3.object.key | The key/path of the S3 object |
| CloudWatch | cw.log.group | The name of the CloudWatch log group |
| CloudWatch | cw.log.stream | The name of the CloudWatch log stream |
| Cloudwatch | cw.owner | The owner of the log group |
| Kafka | kafka.topic | The name of the Kafka topic |
| MSK | kafka.topic | The name of the Kafka topic |
| Kinesis | kinesis.event.id | The Kinesis event ID |
| Kinesis | kinesis.event.name | The Kinesis event name |
| kinesis | kinesis.event.source | The Kinesis event source |
| kinesis | kinesis.event.source_arn | The Kinesis event source ARN |
| Sqs | sqs.event.source | The SQS event source/queue |
| Sqs | sqs.event.id | The SQS event ID |
| Ecr | ecr.scan.id | The ECR scan ID |
| Ecr | ecr.scan.source | The ECR scan source |
Metadata is not added by default. You must specify the metadata keys you want in the AddMetadata parameter. For example, if you want to add the bucket name and key name to the log message, set the AddMetadata parameter to s3.object.key,s3.bucket.
Some metadata keys will overlap as some integrations share the same metadata. For example, both Kafka and MSK have the same metadata key kafka.topic or both Kinesis and CloudWatch metadata will be included when a CloudWatch log stream is ingested from a Kinesis stream.
Dynamic subsystem or application name
As of v1.1.0, you can use dynamic values for the application and subsystem name parameters based on the internal metadata defined above.
To do this, use the following syntax:
{{ metadata.key | r'regex' }}
For example, if you want to use the bucket name as the subsystem name, set the SubsystemName parameter to:
{{ s3.bucket }}
If you want to use the log group name as the application name, set the ApplicationName parameter to:
{{ cw.log.group }}
To extract only a specific portion of the metadata value, you can utilize a regular expression. For example, if there is s3.object.key value in the AWSLogs/112322232/ELB1/elb.log and we want to extract the last part as the subsystem name, we would set the SubsystemName parameter to:
{{ s3.object.key | r'AWSLogs\/.+\/(.*)$' }}
This would result in a SubsystemName value of elb.log as this is the part of the regex that is captured by the group (.*).
If you want to use a json key value as the application name, you would set the ApplicationName parameter to:
{{ $.eventSource }}
Assume the log is a CloudTrail log and the eventSource is s3.amazonaws.com then the application name will be s3.amazonaws.com.
The regex must be a valid regex pattern.
The regex must define a capture group for part of the string that you want to use as the value.
The metadata key must exist in the list defined above and be a part of the integration type that is deployed.
Dynamic values are only supported for the ApplicationName and SubsystemName parameters, the CustomMetadata parameter is not supported.
Fallback Behavior
The dynamic metadata system follows predictable fallback rules:
Template Values (e.g., {{ cw.log.group | r'...' }}):
- If the metadata key exists and regex matches → uses the captured group
- If the metadata key exists but regex fails → uses the raw metadata value
- If the metadata key doesn't exist → uses defaults (
unknown-application/unknown-subsystem)
Non-Template Values (e.g., "MyStaticApp"):
- Always uses the exact configured value, regardless of available metadata
Advanced configuration
AWS PrivateLink
If you want to bypass using the public internet, you can use AWS PrivateLink to facilitate secure connections between your VPCs and AWS. This option is available under the VPC Configuration tab. To turn it on, either unselect the Use Private Link checkbox in the Coralogix UI or set the parameter to true. For additional instructions on AWS PrivateLink, please follow our dedicated tutorial.
Dynamic values
The following method for using dynamic values will change to the method defined above in coralogix-aws-shipper v1.1.0 and later. This approach will no longer be supported. Please check the new method in the Metadata section.
If you wish to use dynamic values for the Application and Subsystem Name parameters, consider the following:
-
JSON support. To reference dynamic values from the log, use
$.my_log.field. For the CloudTrail source, use$.eventSource. -
S3 folder. Use the following tag:
{{s3_key.value}}where the value is the folder level. For example, if the file path that triggers the event isAWSLogs/112322232/ELB1/elb.logorAWSLogs/112322232/ELB2/elb.logand you want ELB1 and ELB2 to be the subsystem, yoursubsystemNameshould be{{s3_key.3}}. -
S3Csv Custom Headers. Add Environment Variable
CUSTOM_CSV_HEADERwith the key names. This must be with the same delimiter as the CSV archive. For example, if the CSV file delimiter is ";", then your environment varialble should beCUSTOM_CSV_HEADER = name;country;age.
DLQ
A Dead Letter Queue (DLQ) is a queue where messages are sent if they cannot be processed by the Lambda function. This is useful for debugging and monitoring.
The DLQ workflow for the Coralogix AWS Shipper is as follows:
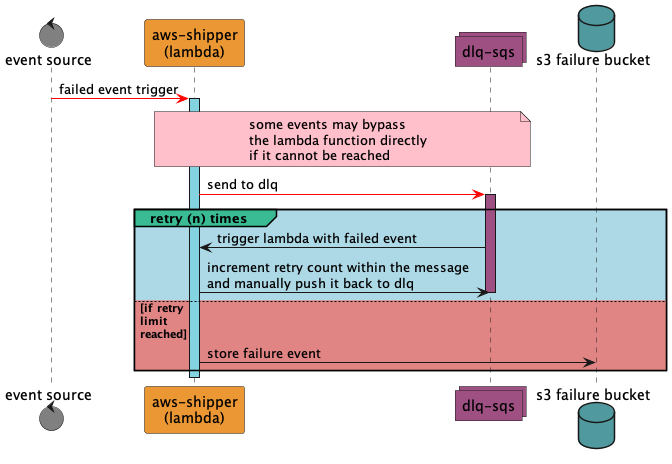
To enable the DLQ, provide the following parameters.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| EnableDLQ | Enable the Dead Letter Queue for the Lambda function. | false | ✅ |
| DLQS3Bucket | An S3 bucket used to store all failure events that have exhausted retries. | ✅ | |
| DLQRetryLimit | The number of times a failed event should be retried before being saved in S3. | 3 | ✅ |
| DLQRetryDelay | The delay in seconds between retries of failed events. | 900 | ✅ |
In the template we use arn:aws:s3:::* for the S3 integration because of CF limitation. It is not an option to loop through the s3 bucket and specify permissions to each one. After the Lambda is created you can manually change the permissions to only allow
access to your S3 buckets.
Log Transformation (Starlark)
The Coralogix AWS Shipper supports custom log transformation using Starlark scripts. Starlark is a Python-like configuration language that allows you to:
- Unnest JSON arrays into individual log entries
- Filter logs based on custom conditions
- Transform log structure before sending to Coralogix
- Enrich logs with additional fields
Starlark Language Reference
Starlark is a Python-like configuration language. For the complete language specification including all data types, operators, built-in functions, and methods, see the official documentation:
Quick reference for log transformation scripts:
- Data types:
None,bool,int,float,string,list,dict,tuple - String methods:
split(),strip(),lower(),upper(),replace(),startswith(),endswith(),find(),format() - List methods:
append(),extend(),insert(),pop(),remove(),clear() - Dict methods:
get(),keys(),values(),items(),pop(),update(),clear() - Built-in functions:
len(),str(),int(),float(),bool(),list(),dict(),type(),range(),enumerate(),zip(),sorted(),reversed(),min(),max(),any(),all(),hasattr(),getattr()
Configuration
The StarlarkScript parameter automatically detects the source type based on the value provided:
| Value Format | Detection | Example |
|---|---|---|
Starts with s3:// | S3 bucket path | s3://my-bucket/scripts/transform.star |
Starts with http:// or https:// | HTTP/HTTPS URL | https://raw.githubusercontent.com/user/repo/transform.star |
| Single line, base64 characters | Base64-encoded script | ZGVmIHRyYW5zZm9ybShldmVudCk6CiAgICByZXR1cm4gW2V2ZW50XQ== |
| Multi-line with code keywords | Raw Starlark script | def transform(event):\n return [event] |
The system automatically detects which type you're using, so you only need to set the StarlarkScript parameter.
Writing a Transform Script
Your script must define a transform(event) function that:
- Takes a single
eventargument (a parsed JSON object or string) - Returns a list of events (can be empty, single, or multiple)
Understanding the Event Format
The event passed to transform(event) is the raw log content — there is no wrapper or envelope added by the shipper. If the log string is valid JSON, event is a Starlark dict (object); otherwise it is a plain string.
The transform runs before any metadata (e.g., s3.object.key, cw.log.group) is attached. Your script only sees the raw log content, not shipper metadata.
The structure of event depends on the source that triggered the Lambda:
| Source | What event Contains | Typical Type |
|---|---|---|
| CloudWatch Logs | The message field from each log event | String or dict (depends on what your application logged) |
| Kinesis (CloudWatch subscription) | Same as CloudWatch — the message field per log event | String or dict |
| Kinesis (raw) | The decoded (and decompressed, if gzip) payload | String or dict |
| S3 (default) | Each line of the file, split by the NewlinePattern | String or dict |
| S3 (CloudTrail) | Each individual record from the CloudTrail Records array | Dict (CloudTrail event object) |
| S3 (VPC Flow Logs) | Each flow log row, parsed into JSON using the flow log header as keys | Dict (e.g., {"srcaddr": "10.0.0.1", "dstaddr": "10.0.0.2", "action": "ACCEPT", ...}) |
| S3 (CSV / CloudFront) | Each CSV row, parsed into JSON using the header row (or CUSTOM_CSV_HEADER) as keys | Dict |
| SQS | The raw SQS message body | String or dict |
| SNS | The raw SNS message body | String or dict |
| Kafka | The message value (base64-decoded if needed) | String or dict |
If your logs are JSON, event is a dict and you can access fields directly:
def transform(event):
# event is {"level": "INFO", "msg": "hello"}
if event["level"] == "DEBUG":
return []
return [event]
If your logs are plain text (e.g., syslog, unstructured output), event is a string:
def transform(event):
# event is "Feb 11 12:00:00 myhost sshd[1234]: Accepted publickey"
if "sshd" in event:
return [{"original": event, "service": "sshd"}]
return [event]
If your logs contain embedded JSON inside a string field, use parse_json:
def transform(event):
# event is {"message": "{\"user\": \"alice\", \"action\": \"login\"}"}
inner = parse_json(event["message"])
return [inner]
To inspect the exact shape of your events, use print(event) in your script and set the LogLevel parameter to DEBUG. The event will appear in CloudWatch Logs for the Lambda function.
Example: Simple passthrough
def transform(event):
return [event]
Example: Unnest a JSON array
If your logs arrive as batched JSON with a nested array:
{"logs": [{"msg": "log1"}, {"msg": "log2"}, {"msg": "log3"}]}
Use this script to unnest them into individual log entries:
def transform(event):
if "logs" in event and type(event["logs"]) == "list":
return event["logs"]
return [event]
Example: Filter out debug logs
def transform(event):
if event.get("level") == "DEBUG":
return [] # Filter out debug logs
return [event]
Example: Enrich logs with metadata
def transform(event):
event["processed"] = True
event["source"] = "aws-shipper"
return [event]
Built-in Functions
The following helper functions are available in your Starlark scripts:
| Function | Description |
|---|---|
parse_json(str) | Parse a JSON string into a Starlark value |
to_json(value) | Convert a Starlark value to a JSON string |
re_match(pattern, str) | Return True if str matches the regex pattern |
re_sub(pattern, replacement, str) | Replace all matches of pattern in str with replacement |
re_match and re_sub use the Rust regex crate (not PCRE). Lookahead, lookbehind, and backreferences are not supported. In re_sub, capture groups can be referenced in the replacement string with $1, $2, and so on ($$ for a literal $).
Example: Redact sensitive values with regex
def transform(event):
msg = event.get("message", "")
if re_match(r"password=\S+", msg):
event["message"] = re_sub(r"password=\S+", "password=***", msg)
return [event]
Using S3 for Script Storage
When the StarlarkScript value starts with s3://, the Lambda function automatically fetches the script from S3. The CloudFormation template automatically adds the necessary permissions when StarlarkScript is set.
StarlarkScript: s3://my-config-bucket/starlark/transform.star
Using HTTP/HTTPS URLs
You can host your script on any HTTP/HTTPS endpoint:
StarlarkScript: https://raw.githubusercontent.com/myorg/scripts/main/transform.star
Using Base64 Encoding
For complex multi-line scripts that are difficult to embed as parameters, use Base64 encoding. The system automatically detects base64-encoded strings:
## Encode your script (works on macOS and Linux)
cat transform.star | base64
## The shipper handles both wrapped and unwrapped base64 output
## Use the output as the StarlarkScript parameter
StarlarkScript: ZGVmIHRyYW5zZm9ybShldmVudCk6CiAgICByZXR1cm4gW2V2ZW50XQ==
If no Starlark script is configured, logs pass through unchanged.
Cloudwatch metrics streaming via PrivateLink (beta)
As of version v1.3.0, the Coralogix AWS Shipper supports streaming Cloudwatch metrics to Coralogix via Firehose over a PrivateLink.
This workflow is designed for scenarios where you need to stream metrics from a CloudWatch metrics stream to Coralogix via a PrivateLink endpoint.
Why to use this workflow?
AWS Firehose does not support PrivateLink endpoints as a destination because Firehose cannot be connected to a VPC, which is required to reach a PrivateLink endpoint. To overcome this limitation, the Coralogix AWS Shipper acts as a transform function. It is attached to a Firehose instance that receives metrics from the CloudWatch metrics stream and forwards them to Coralogix over a PrivateLink.
When to use this workflow
This workflow is designed to bypass the limitations of using Firehose with the Coralogix PrivateLink endpoint. If PrivateLink is not required, we recommend using the default Firehose CloudWatch metrics stream integration.
How does it work?
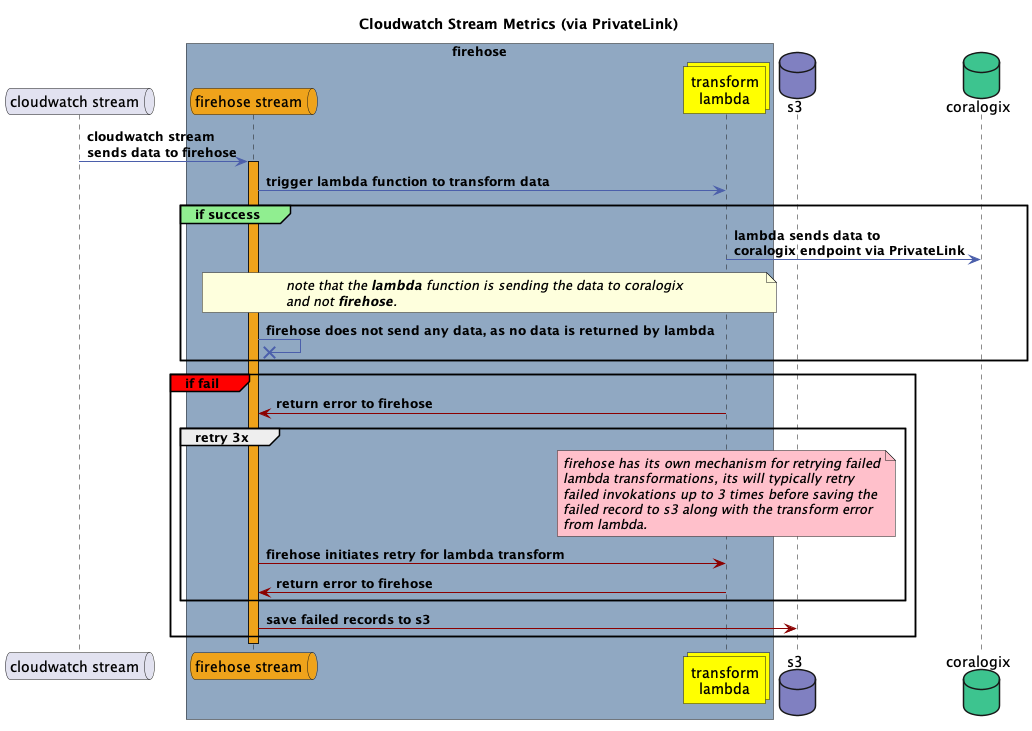
To enable CloudWatch metrics streaming via Firehose (PrivateLink), you must provide the necessary parameters listed below.
| Parameter | Description | Default Value | Required |
|---|---|---|---|
| TelemetryMode | Specify the telemetry collection modes, supported values (metrics, logs). Note that this value must be set to metrics for the Cloudwatch metric stream workflow. | logs | ✅ |
| ApiKey | The Send-Your-Data API key validates your authenticity. This value can be a direct Coralogix API Key or an AWS Secret Manager ARN containing the API key. Note that the parameter expects the API key in plain text or stored in secret manager. | ✅ | |
| ApplicationName | The name of the application for which the integration is configured. Advanced configuration specifies dynamic value retrieval options. | ✅ | |
| SubsystemName | Specify the name of your subsystem. For a dynamic value, refer to the Advanced Configuration section. For CloudWatch, leave this field empty to use the log group name. | ✅ | |
| CoralogixRegion | Your data source should be in the same region as the integration stack. You may choose from one of the default Coralogix regions: [Custom, EU1, EU2, AP1, AP2, AP3, US1, US2]. If this value is set to Custom, specify the custom domain to use via the CustomDomain parameter. | Custom | ✅ |
| S3BucketName | The S3 bucket that will be used to store records that have failed processing | ✅ | |
| LambdaSubnetID | Specify the ID of the subnet for the integration deployment. | ✅ | |
| LambdaSecurityGroupID | Specify the ID of the Security Group wfor the integration deployment. | ✅ | |
| StoreAPIKeyInSecretsManager | Enable this to store your API Key securely. Otherwise, it will remain exposed in plain text as an environment variable in the Lambda function console. | True | |
| MetricsFilter | The filter for the metrics to include in the stream that will get created, should be valid json that contains the keys Namespace and MetricNames, for example: [{"Namespace": "AWS/EC2", "MetricNames": ["CPUUtilization", "NetworkOut"]},{"Namespace": "AWS/S3", "MetricNames": ["BucketSizeBytes"]}]. Can't use this parameter with ExcludeMetricsFilters parameter. | n/a | |
| ExcludeMetricsFilters | The filter for the metrics to exclude from the stream that will get created, should be valid json that contains the keys Namespace and MetricNames, for example: [{"Namespace": "AWS/EC2", "MetricNames": ["CPUUtilization", "NetworkOut"]}]. Can't use this parameter with MetricsFilter parameter. | n/a | |
| MetricsTagEnrichmentEnabled | When TelemetryMode is metrics, resolve AWS resource tags via the Resource Groups Tagging API and attach them to streamed metric datapoints (YACE-compatible namespace map and associator). When true, the stack adds the required IAM statements. Set false to disable lookups (for example if the Lambda cannot reach the tagging API from its VPC). | true | |
| MetricsContinueOnResourceFailure | When TelemetryMode is metrics, if true, tagging or resource-discovery errors cause the function to skip AWS tags for affected namespaces and still ship metrics. If false, the invocation fails instead (no Coralogix delivery for that batch). | true | |
| MetricsFileCacheEnabled | When TelemetryMode is metrics, persist a per-namespace cache of discovered resources under MetricsFileCachePath on the Lambda filesystem between invocations to reduce GetResources traffic. | true | |
| MetricsFileCachePath | Directory used for the metrics resource cache files (typically Lambda ephemeral storage, e.g. /tmp). | /tmp | |
| MetricsFileCacheExpiration | Maximum age of cache files before they are refreshed. Human-readable duration (e.g. 1h, 30m); same style as Go ParseDuration for familiarity. | 1h | |
| BatchMetrics | When TelemetryMode is metrics, set to true to batch OpenTelemetry metric messages from a single Firehose payload into one aggregated request to Coralogix (BATCH_METRICS env). When false, behavior matches the previous per-message pattern. | false | |
| MetricsBatchMaxSize | Maximum size in MB of the aggregated encoded protobuf batch when BatchMetrics is true (maps to METRICS_BATCH_MAX_SIZE). | 4 |
Static labels on metrics: The CustomMetadata parameter applies when TelemetryMode=metrics as well as for logs: comma-separated key=value pairs are added as labels on transformed metric datapoints. Only the first = in each pair separates key from value, so values may contain =.
VPC / PrivateLink: With tag enrichment enabled, the Lambda must reach tagging.amazonaws.com (NAT gateway, interface VPC endpoint, or equivalent). See AWS PrivateLink and the firehose-metrics-private-link example.
Batching (optional)
BatchMetricsstack parameter (setsBATCH_METRICSenv): When enabled (true), the Lambda batches all OpenTelemetry metric messages contained in a single Firehose event into one aggregatedExportMetricsServiceRequestand sends a single POST request toPOST /v1/metrics. This reduces network overhead versus sending one request per message. Default: disabled.- Works only with
TELEMETRY_MODE=metrics. - Note: Larger events can produce larger single requests; ensure they fit within your network and service limits.
- Works only with
METRICS_BATCH_MAX_SIZE(fromMetricsBatchMaxSizeparameter): Maximum size in megabytes for the aggregated encoded protobuf payload before it is flushed and sent. Default:4. Applies only when batching is enabled. If a single transformed message exceeds this size, it is sent by itself.
AWS GovCloud (US)
The Coralogix AWS Shipper runs in AWS GovCloud (US) partitions (us-gov-east-1, us-gov-west-1) using the dedicated template-govcloud.yaml. GovCloud deployments enable FIPS 140-3 compliance by default: the Lambda is configured with AWS_USE_FIPS_ENDPOINT=true (routing all SDK calls to FIPS service endpoints) and ENABLE_AWS_FIPS=true (switching the AWS SDK HTTP client to the AWS-LC FIPS-validated TLS provider).
FIPS is enabled at runtime via environment variables on a single shipper binary; there is no separate GovCloud build. To opt out, remove AWS_USE_FIPS_ENDPOINT and ENABLE_AWS_FIPS from template-govcloud.yaml before deployment.
Terraform deployment (recommended)
We recommend deploying the GovCloud shipper with the Coralogix Terraform module. The same module used in commercial regions, terraform-coralogix-aws, supports GovCloud through the govcloud_deployment = true flag, which selects the GovCloud template and the matching FIPS-enabled Lambda artifact.
Manual deployment with CloudFormation/SAM
If Terraform is not an option, you can deploy template-govcloud.yaml directly. The shipper Lambda package is downloaded from Coralogix’s published artifacts and uploaded to a GovCloud S3 bucket before deployment, since the AWS Serverless Application Repository is not available in GovCloud.
Prerequisites
- AWS CLI configured for GovCloud (
aws-us-gov) with the correct region (e.g.us-gov-west-1orus-gov-east-1). - An S3 bucket in that GovCloud region for Lambda deployment packages.
- Coralogix ingress domain (
CustomDomain, e.g.cx….coralogix.com) and API key (or Secrets Manager ARN). - Integration parameters ready (e.g.
IntegrationType,S3BucketName, SNS/SQS ARNs, CloudWatch log groups) for your use case.
Step 1 — Download the shipper Lambda (bootstrap.zip)
Coralogix publishes the same package the AWS Serverless Application Repository uses. Download it over HTTPS and save it as bootstrap.zip. Pick one regional URL (the object path is identical across regions):
| Region | Base URL |
|---|---|
| Asia Pacific (Hong Kong) | https://coralogix-serverless-repo-ap-east-1.s3.ap-east-1.amazonaws.com |
| Europe (Frankfurt) | https://coralogix-serverless-repo-eu-central-1.s3.eu-central-1.amazonaws.com |
| US East (N. Virginia) | https://coralogix-serverless-repo-us-east-1.s3.us-east-1.amazonaws.com |
Example (Frankfurt):
curl -fLsS -o bootstrap.zip \
'https://coralogix-serverless-repo-eu-central-1.s3.eu-central-1.amazonaws.com/coralogix-aws-shipper.zip'
These URLs point at the current published object; there is no version in the path. Keep your own copy or checksum if you need a pinned release.
Step 2 — Package the custom resource (custom-resource.zip)
Package the GovCloud custom resource so the zip contains a single top-level index.py (handler index.lambda_handler):
cd custom-resource-govcloud
zip -j custom-resource.zip index.py
cd ..
Step 3 — Upload to GovCloud S3
GOVCLOUD_BUCKET="your-govcloud-artifacts-bucket"
GOVCLOUD_REGION="us-gov-west-1"
VERSION="1.4.8"
PREFIX="coralogix-aws-shipper"
aws s3 cp bootstrap.zip \
"s3://${GOVCLOUD_BUCKET}/${PREFIX}/${VERSION}/bootstrap.zip" \
--region "${GOVCLOUD_REGION}"
aws s3 cp custom-resource-govcloud/custom-resource.zip \
"s3://${GOVCLOUD_BUCKET}/${PREFIX}/${VERSION}/custom-resource.zip" \
--region "${GOVCLOUD_REGION}"
Step 4 — Deploy the stack
Minimal example (adjust parameters for your integration):
aws cloudformation deploy \
--template-file template-govcloud.yaml \
--stack-name coralogix-shipper \
--region "${GOVCLOUD_REGION}" \
--capabilities CAPABILITY_IAM CAPABILITY_NAMED_IAM \
--parameter-overrides \
LambdaCodeBucket="${GOVCLOUD_BUCKET}" \
LambdaCodeKey="${PREFIX}/${VERSION}/bootstrap.zip" \
CustomResourceCodeBucket="${GOVCLOUD_BUCKET}" \
CustomResourceCodeKey="${PREFIX}/${VERSION}/custom-resource.zip" \
CustomDomain="YOUR_CORALOGIX_DOMAIN" \
ApiKey="YOUR_API_KEY_OR_SECRET_ARN" \
ApplicationName="your-app" \
IntegrationType="S3" \
S3BucketName="your-log-bucket"
Change IntegrationType and add the parameters required for that integration (refer to Configuration parameters).
Step 5 — Verify
- The CloudFormation stack reaches CREATE_COMPLETE or UPDATE_COMPLETE.
- Confirm the shipper Lambda and
{stack-name}-custom-resourcereference the S3 keys you uploaded. - Confirm the shipper Lambda has
AWS_USE_FIPS_ENDPOINT=trueandENABLE_AWS_FIPS=trueset. - On cold start the Lambda log group
/aws/lambda/<stack-name>should containAWS FIPS mode enabled for SDK HTTP client. - If something fails, check the custom resource log group
/aws/lambda/<stack-name>-custom-resourceand the main shipper Lambda’s log group.
Troubleshooting
Parameter max value
If you tried to deploy the integration and received the length is greater than 4094 error, you can upload the value of the parameter to an S3 bucket as txt. Then, pass the file URL as the parameter value (this option is available for KafkaTopic and CloudWatchLogGroupName parameters).
Timeout errors
If you receive the Task timed out after message, increase the Lambda timeout value. You can do this from the AWS Lambda function settings under Configuration > General Configuration.
Not enough memory
If you receive the Task out of memory message, increase the Lambda maximum צemory value. You can do this from the AWS Lambda function settings under Configuration > General Configuration.
Verbose logs
To add more verbosity to your function logs, set the RUST_LOG parameter to DEBUG.
Trigger failed on deployment
If the deployment fails while assigning the trigger, ensure that no notifications are enabled for the S3 bucket. For CloudWatch, note that the maximum number of notifications per Log Group is 2.
Don't forget to revert it to WARN after troubleshooting.
Changing defaults
Set the MAX_ELAPSED_TIME variable for the default change (default = 250). The BATCHES_MAX_SIZE (in MB) defines the maximum batch size before sending data to Coralogix. This value is limited by the maximum payload accepted by the Coralogix endpoint (default = 4). The BATCHES_MAX_CONCURRENCY sets the maximum number of concurrent batches that can be sent.
Support
Need help?
Our world-class customer success team is available 24/7 to walk you through your setup and answer any questions that may come up.
Contact us via our in-app chat or by emailing [email protected].