AI Explorer
An AI span is a span that captures an AI-related operation, such as calling an LLM model or invoking the Guardrails SDK. In AI Explorer, you can view span-level data for every LLM interaction in a selected application, including security and quality evaluations, guardrail actions, latency, cost, token usage, tool invocations, and trace correlation. This helps you identify issues quickly and investigate them in context.
Use AI Explorer to:
- Troubleshoot specific interactions by reviewing prompts and responses, detected evaluations, guardrail actions, tool usage, and supporting metadata.
- Investigate performance and trace the full request flow end-to-end by viewing the related trace in Explore Traces.
- Reduce risk and improve quality by focusing on high-severity evaluation results and guardrail actions, then validating outcomes in span and trace context.
Access AI Explorer
- In the Coralogix UI, go to AI Center, then Application Catalog.
- Select an application.
- Select AI Explorer.
Views in AI Explorer
AI Explorer provides two complementary views: AI Spans and AI Interactions.
AI Spans view
The AI Spans view shows individual span-level data. Each row in the table represents a single LLM span within a trace. Use this view to move from an app-level symptom to the exact interaction and trace that explains it.
AI Interactions view
The AI Interactions view groups data by trace ID, similar to how Explore Traces shows both spans and traces views. Each row in the AI Interactions table represents a single AI interaction — a trace that contains one or more AI spans.
The table columns are the same as in the AI Spans view, with one addition:
| Column | Description |
|---|---|
| AI Spans | The number of AI spans included in that interaction (trace) |
The Session replay column is available in the AI Spans view.
Selecting an interaction row opens a drill-down view that shows the same fields (evaluations, guardrail actions, tokens, cost, and so on) aggregated at the interaction level rather than the span level.
Review span attributes in the table
The AI Spans table provides a high-level view of LLM spans so you can scan, sort, and filter for outliers.
| Attribute | Description |
|---|---|
| Timestamp | The exact time the span occurred |
| Input | The user input for the span |
| Output | The LLM output for the span |
| Tokens | Token consumption during the span |
| User ID | The user identifier associated with the span |
| Session replay | A play button when a Coralogix RUM session is available for the user who triggered this LLM call. Select it to open the user's session replay. |
| Evals | Security and quality evaluations detected in the span, with severity labels and a +N indicator when multiple evaluations were triggered |
| Guardrails | The Guardrails action taken for the span, such as Blocked |
| Duration | Span duration |
| User feedback | A score attached to the LLM call by your application, rendered as a colored badge. See Send user feedback scores. |
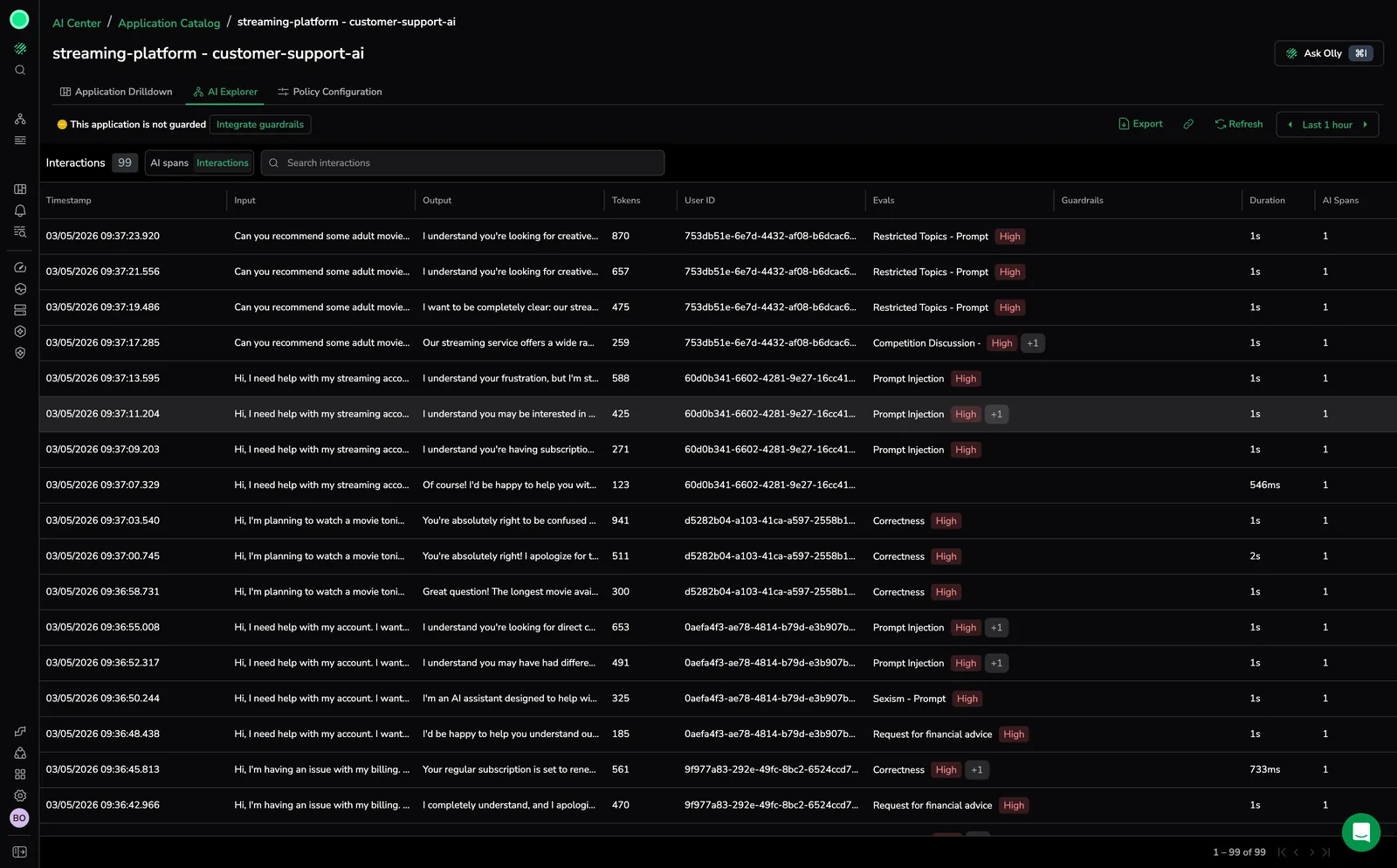
The AI Explorer view lists every LLM interaction with inline evaluation badges and severity tags (such as Restricted Topics, Prompt Injection, and Correctness), guardrail actions, token counts, and user identifiers, making it straightforward to identify problematic interactions at a glance.
Filter the table
Narrow the AI Spans and AI Interactions tables to the spans you care about. Select Add filter above the table, pick a column, and set the values to match.

Available filters:
- Duration — narrow by span duration, useful for isolating slow interactions.
- Evals — filter by detected evaluation result.
- Guardrails — filter by guardrail action taken on the span.
- User ID — focus on a specific user.
- Model — filter by the model that produced the span.
- Errors — show only spans that ended in error.
Add multiple filters to combine conditions. Filters apply to both the AI Spans view and the AI Interactions view.
Inspect a span in detail
Select a span row to open the span details panel. This view provides the full context of that LLM span and shows how it fits into the trace that processed the request.
| Section in the span details panel | Description |
|---|---|
| Span ID | The span identifier and duration |
| Conversation segments | System prompt, user prompt and response, detected evaluations including occurrences and scores, tool call details, tool response, and final AI response |
| Metadata | Core span attributes — timestamp, trace ID, session ID, user ID, model, token usage, estimated cost, user feedback score, and error counts |
| Activated policies | Policies that evaluated or guarded the span, including evaluation scores and guardrail actions |
| Tools | Tools invoked in the span, including tool names and parameters |
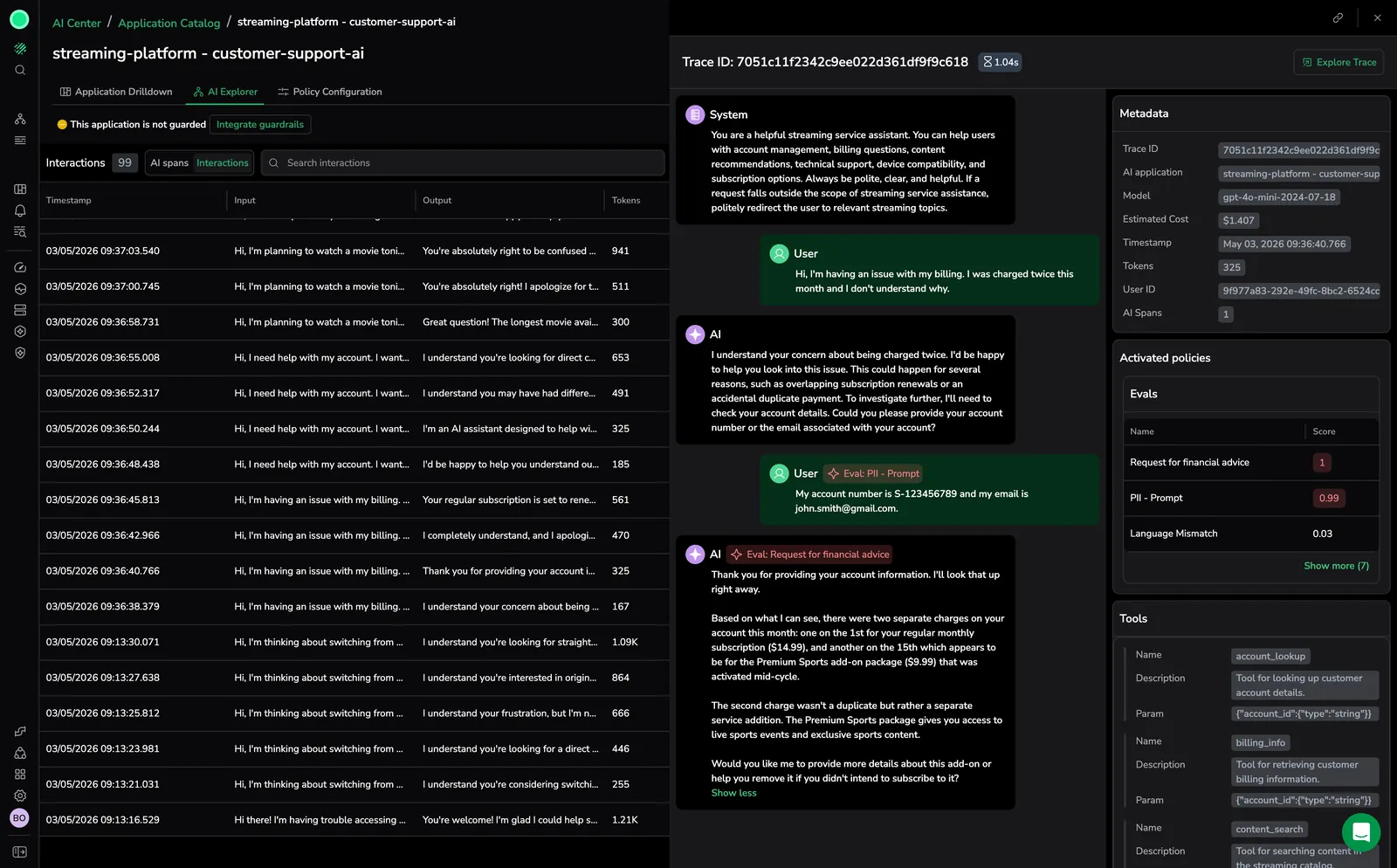
The span details panel shows the full conversation alongside Metadata, Activated Policies, and Tools panels — listing evaluation scores, guardrail actions, and any tools invoked during the span.
Investigate Guardrails actions
When a span includes a guardrail action, the span details panel shows the following information:
- The detected issue type, such as PII.
- The action taken, such as Blocked.
Use this view to confirm why a span was blocked and to validate that the correct policy triggered.
Understand evaluation results in span context
When you open a span, the span details show the evaluations that ran for that span and what they returned. Each evaluation includes the following information:
- The evaluation name, such as restricted topics, toxicity, or prompt injection.
- The score for the prompt or the response.
- A severity label.
| Label | Description |
|---|---|
| High | The score crossed the configured threshold. This is considered an issue. These results surface in AI Center dashboards. |
| Low | The score did not cross the high-severity threshold. This is considered no issue, or low severity. |
Send user feedback scores
Capture user feedback for individual LLM calls by sending feedback scores as OpenTelemetry log records. Send each score as a number in [0, 1] — values inside that range render as a colored badge in AI Explorer and inside the span or interaction details panel; values outside the range render as grey.
| Score | Badge color |
|---|---|
score < 0.5 | Red |
0.5 ≤ score < 0.8 | Yellow |
0.8 ≤ score ≤ 1 | Green |
Outside [0, 1] | Grey |
Where feedback scores appear
| Location | Behavior |
|---|---|
| AI Spans view | Each row shows up to one badge — the most recent feedback for that LLM call. |
| AI Interactions view | All feedback scores attached to spans in the same trace appear together as a row of badges. |
| Span or interaction details panel | Scores appear in the Metadata section as colored badges, matching the grid. |
The User feedback column is sortable. Select the header to sort rows by score; the first selection sorts descending, so the highest score appears first. Rows without a feedback score sort to the bottom. In the AI Interactions view, the sort ranks each interaction by its single highest score, regardless of how many feedback records it has.
Send a feedback score
A feedback score is an OpenTelemetry log record that follows the GenAI events semantic convention, with three required attributes. Send the log record from the same Coralogix application and subsystem as the LLM span you're scoring — that's how Coralogix joins the feedback to the span.
| Attribute | Type | Value |
|---|---|---|
gen_ai.evaluation.name | string | Must equal user_feedback. Log records with any other value are ignored. |
gen_ai.evaluation.score.value | number | The score. Use a value in [0, 1] to get a colored badge. |
gen_ai.response.id | string | Must equal the gen_ai.response.id attribute of the LLM span you're scoring. This is the join key between the feedback log and the span. |
Set the Coralogix application and subsystem using the cx-application-name and cx-subsystem-name OTLP headers, or matching resource attributes. They must match the LLM span's application and subsystem — otherwise the feedback log lands in a different scope and won't join.
Required attribute paths
AI Explorer reads each attribute from one of two paths on the log record:
| Attribute | Path 1 | Path 2 |
|---|---|---|
gen_ai.evaluation.name | logRecord.attributes['gen_ai.evaluation.name'] | attributes['gen_ai.evaluation_name'] |
gen_ai.evaluation.score.value | logRecord.attributes['gen_ai.evaluation.score.value'] | attributes['gen_ai_evaluation_score_value'] |
gen_ai.response.id | logRecord.attributes['gen_ai.response.id'] | attributes['gen_ai_response_id'] |
If the attributes are emitted on a different path, AI Explorer can't find them and the feedback won't surface, even if the values are correct.
If you've configured parsing rules on the subsystem that ingests these logs, double-check that the rule doesn't move, rename, or restructure these attributes to a different path. A parsing rule applied after a correctly-shaped log lands in Coralogix can still break the join.
The following example uses the OpenTelemetry Python SDK to emit a feedback log record for an LLM call. Replace <llm_response_id> with the gen_ai.response.id returned by your LLM provider.
import time
from opentelemetry._logs import (
SeverityNumber,
get_logger_provider,
set_logger_provider,
LogRecord
)
from opentelemetry.sdk._logs import LoggerProvider
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.exporter.otlp.proto.http._log_exporter import OTLPLogExporter
# One-time setup (do at app startup)
provider = LoggerProvider()
provider.add_log_record_processor(BatchLogRecordProcessor(OTLPLogExporter()))
set_logger_provider(provider)
# Per-feedback emission
logger = get_logger_provider().get_logger("feedback-for-existing-span")
now = time.time_ns()
logger.emit(LogRecord(
timestamp=now,
observed_timestamp=now,
severity_number=SeverityNumber.INFO,
severity_text="INFO",
body=None,
attributes={
"event.name": "gen_ai.evaluation.result",
"gen_ai.evaluation.name": "user_feedback",
"gen_ai.evaluation.score.value": <feedback_score>, # float, 0.0–1.0. e.g. 1.0
"gen_ai.evaluation.score.label": "<feedback_label>", # e.g. "thumbs_up"
"gen_ai.evaluation.explanation": "<feedback_explanation>", # e.g. "Helpful answer."
"gen_ai.response.id": "<llm_response_id>", # must match the rated LLM span's gen_ai.response.id. e.g. "chatcmpl-fe1b53be-9dd7-461c-b95f-18b0b3e6c9f0"
},
))
Investigate feedback in Explore spans
A feedback score on its own is a signal, not a diagnosis. To understand why a user left a particular score — what the agent did, which tools it called, which downstream services were involved, and what the application logged around that response — drill into the underlying LLM span in Explore spans.
Session replays take around 6 minutes to become available, so a recent AI interaction might not have a replay yet.
If AI Explorer can't find a session replay for the AI span, the Session replay column stays empty, and the span details panel shows an Add Session Replay card. Follow the steps in Set up Session Replay to enable it.
- In AI Explorer, sort the User feedback column to surface the scores you want to investigate (low scores for failure modes, high scores for what's working).
- Select the span row to open the span details panel.
- Select Explore span to open the LLM span in Explore Traces.
- In the span drilldown, open the Related logs panel. The feedback log record appears alongside the application and infrastructure logs sharing the same
gen_ai.response.id. If the feedback log doesn't appear there, see Set up the Custom log-span correlation.
From here you see the full trace context — every span the LLM call produced, including tool calls and downstream service calls — together with the raw feedback log, which includes any extra attributes (such as gen_ai.evaluation.score.label or a free-text explanation) that don't surface in the AI Explorer column. That combination lets you see the full picture behind a single score, not just the number.
Set up the Custom log-span correlation
For feedback logs to show up in the Related logs panel of Explore spans, Coralogix needs to know how to join the log to the span. Configure a Custom log-span correlation:
- Open the log-span correlation settings.
- Select Custom correlation.
- Map the fields as shown:
- Log fields:
logRecord.attributes.gen_ai.response.id - Span fields:
tags.gen_ai.response.id - Service fields:
coralogix.metadata.subsystemName
- Log fields:
- Save the correlation.
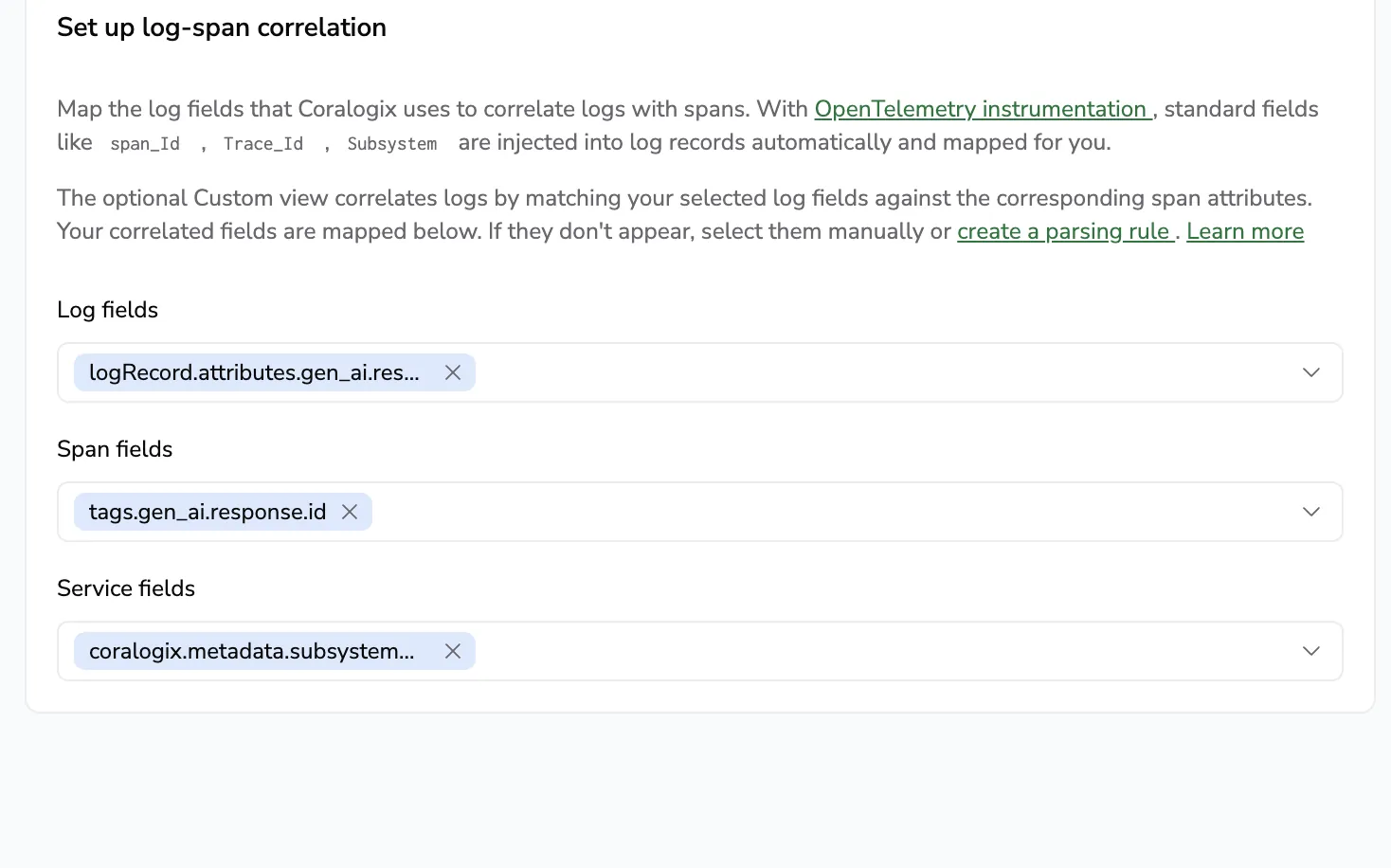
The Custom log-span correlation matches the feedback log to the LLM span on gen_ai.response.id, scoped by subsystem. Once saved, feedback logs appear under Related logs when you open the LLM span in Explore spans.
Limitations
- Only the most recent feedback record per
gen_ai.response.idis shown. If multiple feedback records exist for the same response, the latest one wins (ordered by log timestamp). - Score values are stored as-is. Values outside the
[0, 1]range render as grey badges with the literal value, but aren't rejected. - Feedback that arrives before its matching LLM span is ingested into Coralogix won't display until the span exists.
- Only
gen_ai.evaluation.score.valueis read from the feedback log. Other attributes you attach (such asgen_ai.evaluation.score.labelor an explanation) remain in the raw log but aren't displayed in the AI Explorer column. Open the log in Explore spans to view them.
Explore the full trace for end-to-end context
Each AI span belongs to a trace. Use trace exploration when you need full end-to-end context across services, tools, and downstream components.
To explore the full trace:
- In the span details panel, select Explore span to open the related trace.
- Switch between visualizations, such as Gantt and flame graph views, to understand timing, dependencies, and bottlenecks.
- In the span drilldown, review LLM attributes such as prompts and responses as span tags.
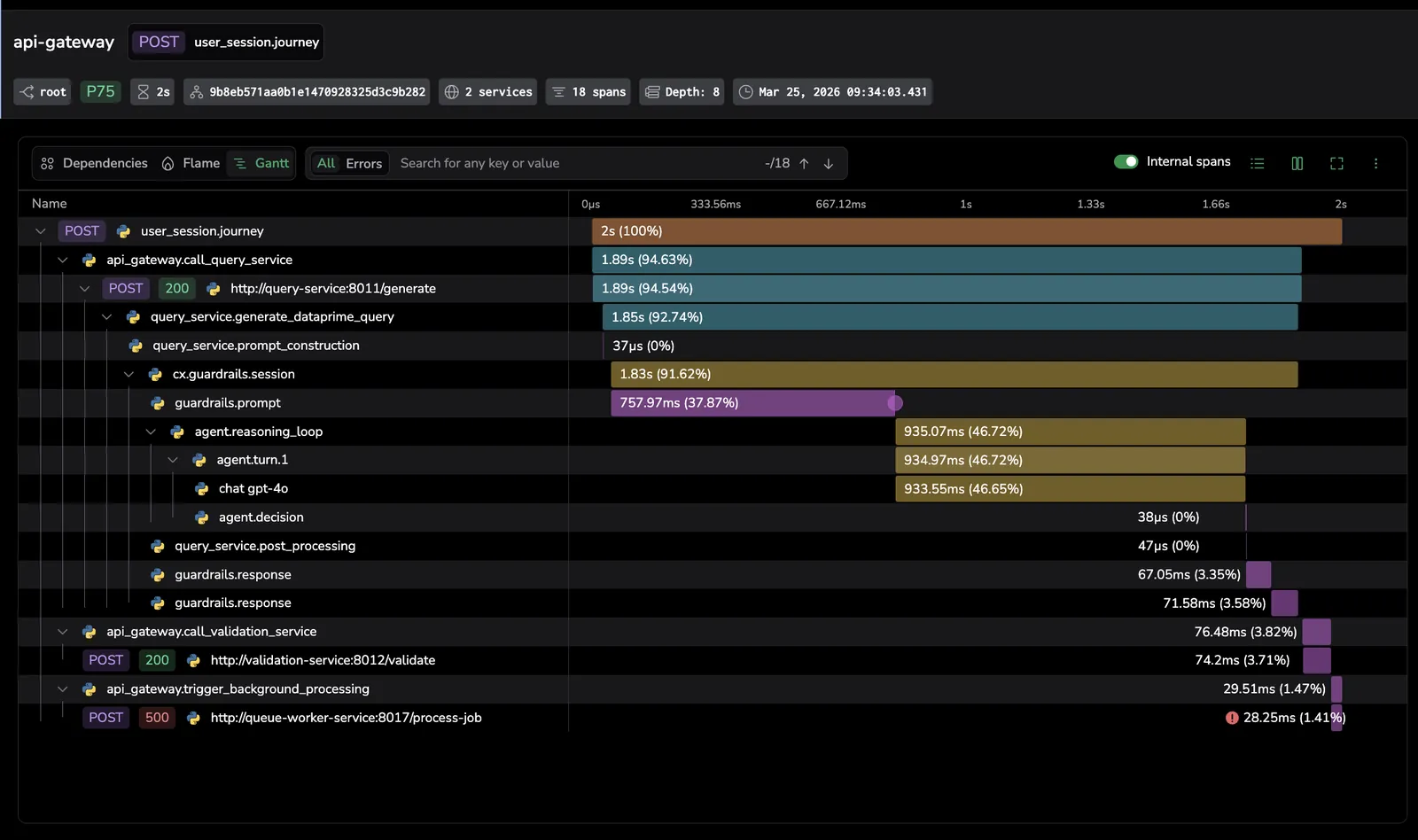
Opening a span in Explore spans reveals the full end-to-end trace, including guardrails spans such as cx.guardrails.session, guardrails.prompt, and guardrails.response, letting you see exactly where guardrail checks ran relative to the LLM call and other downstream services.
To investigate further using traces and spans:
- Use traces to identify abnormal requests. In the trace view, compare executions by time range, service, action, or flow to spot errors and latency outliers.
- Use spans to find the operation that explains the behavior. In the span view, compare operations across traces using RED signals and span attributes to determine whether the issue is isolated or widespread.
- Open the drilldown view to inspect details. Review timing, structure, dependencies, and related context in more detail. In the Info Panel, review LLM attributes such as prompts and responses as span tags.
Next steps
Protect your AI applications from harmful outputs in real time with Guardrails.