Polystat Tutorial: CPU Utilization Across K8s Containers
What’s Polystat?
If you’re a DevOps engineer or a system admin keeping tabs on resource usage, you know that at-a-glance insights can be game-changers. Enter Polystat: a widget that explodes a single metric (or log or span field value) into a detailed, color-coded visualization, broken down by label.
In this tutorial, we’ll create a Polystat widget to monitor CPU utilization across Kubernetes containers, with each container’s CPU usage displayed in its own hexagon for an immediate snapshot of system health.
Why is CPU a good Polystat candidate?
Polystat’s design is perfect for monitoring CPU usage because it displays each container’s CPU utilization in an individual, color-coded hexagon, providing instant visual insights across your system. This layout allows you to quickly identify overused or underutilized containers through configurable thresholds, making it easy to spot issues at a glance.
Polystat works best with high-cardinality metrics. It allows you to break down CPU usage by many labels (like namespace or pod), adding the context needed to monitor performance at scale in Kubernetes environments.
Monitoring CPU
Let’s create a CPU utilization polystat widget that gives a real-time view of how each container is performing.
Step 1: Build your query
Start by adding the Polystat widget to your dashboard.
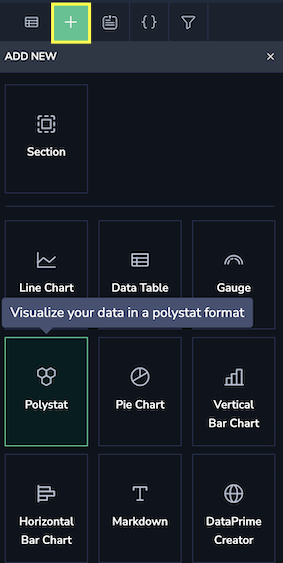
Once it’s in place, it’s time to build a query to pull in the CPU utilization data. For this, we’ll use Query Builder to fetch the relevant metrics.

Here’s a breakdown of how the query works:
Metric Source: We’re pulling data from
container_cpu_utilization_1, which gives the CPU utilization percentage for each container.sumbyk8s_container_name: To make this data useful at the container level, we group byk8s_container_nameand usesum. This lets us see the total CPU usage per container, not just per core or thread. By combining metrics this way, we get an easy-to-interpret view of how each container is performing in real time.avg_over_time (Query Range): Usingavg_over_timesmooths out short-term spikes by averaging CPU usage over a specific time range. This way, instead of seeing a jagged, fluctuating number, you get a more stable view of how much CPU each container is actually using, which can reveal patterns or sustained high usage.
Of course, if you are interested in fluctuations in CPU, even short-lived ones, then average is not the best choice, and you should consider a quantile instead.
Step 2: Configure the widget parameters
Once the query is set, you’re ready to define the widget parameters. This step ensures that your Polystat widget displays data in a useful and meaningful way.
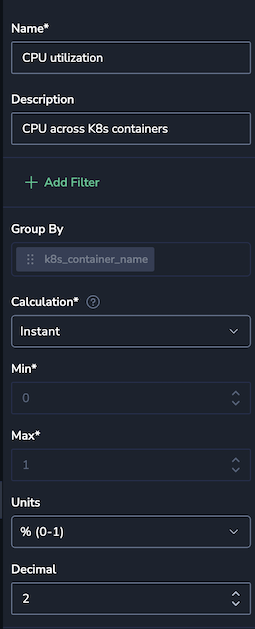
Here’s what each parameter does:
- Group By: Grouping by
k8s_container_namemeans each hexagon will represent CPU usage for a specific container. This setup gives you a color-coded breakdown of CPU utilization for each container at a glance. - Calculation: Set to
instant, so the widget pulls in the most recent data point for each container. This way, you’re seeing exactly what’s happening in real-time, which is ideal for spotting any container that’s currently under heavy load. - Min and Max / Units: Setting the min to
0and max to1(for 0% to 100% CPU utilization) defines the widget’s display range. Percentages are displayed with two decimal places, so you get an accurate view (e.g., 73.58%) without clutter.
Step 3: Set thresholds for real-time alerts
A core feature of Polystat is the ability to apply thresholds for any metric, log, or span value. Here we apply this feature to our mission of visualizing CPU utilization by color-coding based on CPU load, so you can instantly see if a container’s utilization is in the safe zone, trending high, or at a critical level.
Here’s how we’ll set it up:
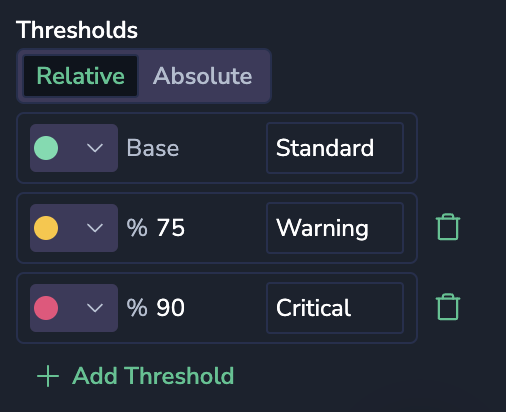
- Green (Base): Below the first threshold, hexagons will be green, indicating CPU utilization is at a normal level.
- Yellow (Warning): Set to turn yellow at 75%, signaling a moderate CPU load.
- Red (Critical): At 90% or higher, hexagons turn red, flagging containers under high load that may need attention. At this level, the container is under high CPU load and may soon become bottlenecked. If containers hit this level frequently, they might need additional resources, or the workload may need to be redistributed.
This color-coding makes it easy to spot issues. You don’t have to sift through numbers; instead, a glance at the dashboard tells you where to focus.
Step 4: Monitor and respond in real-time
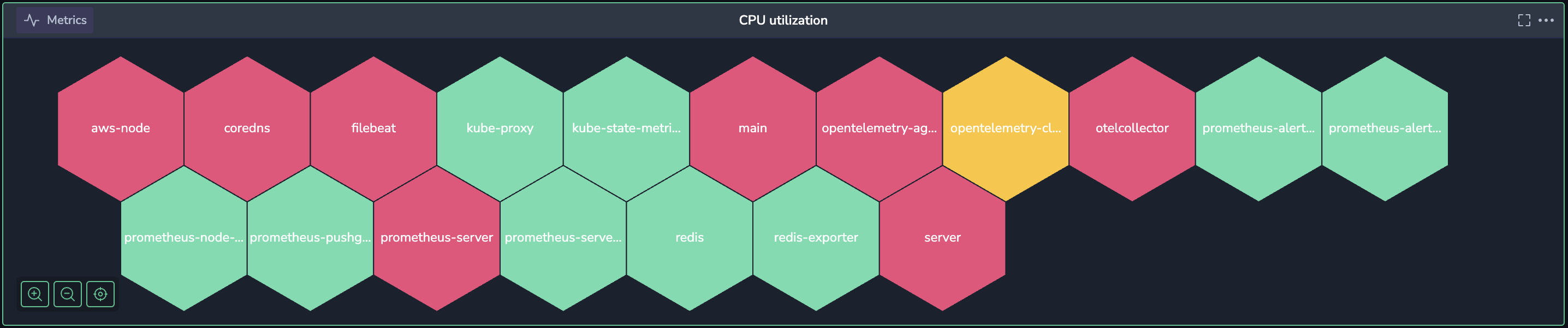
With everything set up, your CPU Utilization Polystat widget is ready to roll! When you start seeing traffic spikes, you’ll get a real-time, color-coded view of CPU usage across your Kubernetes containers. Hovering over a hexagon reveals the exact CPU utilization for each container and the container’s name. For instance, if prometheus-server is showing a CPU usage of around 95% and is marked in red, you know it’s time to investigate or scale up.
With this dashboard, you can make quick, informed decisions, like:
- Scaling up resources for any container in the red zone to handle increased demand.
- Redistributing workloads across other containers to balance the load.
- Proactively monitoring yellow-labeled containers to catch potential issues before they reach critical levels.
Beyond day-to-day monitoring, you can analyze patterns over time. If certain containers, like aws-node or prometheus-server, consistently hit high CPU during peak periods, it might be worth exploring optimizations. Maybe that’s adjusting configurations, or maybe it’s refactoring code to make the container more efficient.
Wrapping up
With this Polystat widget, you’ve created a powerful tool that gives you a clear, real-time view of CPU usage across all your Kubernetes containers. No more guessing which containers might be under strain—you can see it all at a glance.
Whether you’re responding to sudden traffic spikes or analyzing trends for long-term optimizations, this setup helps your team keep applications running smoothly and efficiently, even under heavy load.