DevOps Security: Challenges and Best Practices
With the shift from traditional monolithic applications to the distributed microservices of DevOps, there is a need for a similar change in operational security policies. For…

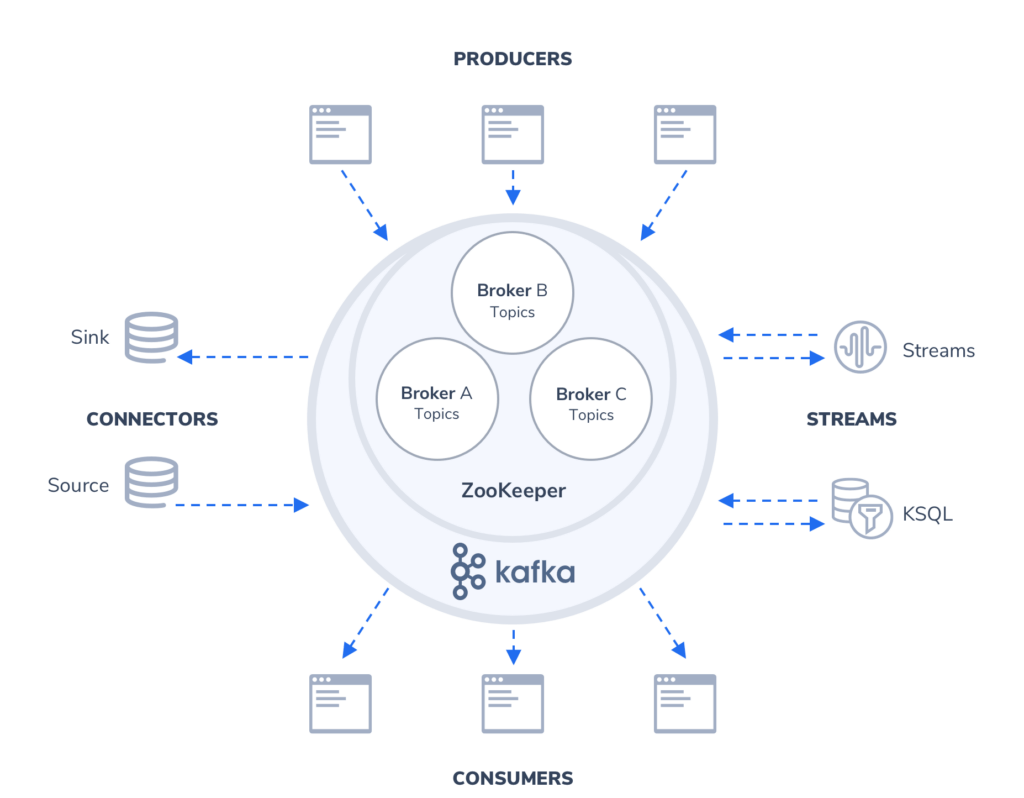
Kafka is an open source real-time streaming messaging system and protocol built around the publish-subscribe system. In this system, producers publish data to feeds for which consumers are subscribed to.
With Kafka, clients within a system can exchange information with higher performance and lower risk of serious failure. Instead of establishing direct connections between subsystems, clients communicate via a server which brokers the information between producers and consumers. Additionally, the data is partitioned and distributed across multiple servers. Kafka replicates these partitions in a distributed system as well.
Altogether, this design enables moving large amounts of data between system components with low-latency and fault-tolerance.
Kafka achieves high-throughput, low-latency, durability, and near-limitless scalability by maintaining a distributed system based on commit logs, delegating key responsibility to clients, optimizing for batches and allowing for multiple concurrent consumers per message.
Example use cases:
Kafka is maintained as clusters where each node within a cluster is called a Broker. Multiple brokers allow us to evenly distribute data across multiple servers and partitions. This load should be monitored continuously and brokers and topics should be reassigned when necessary.
Each Kafka cluster will designate one of the brokers as the Controller which is responsible for managing and maintaining the overall health of a cluster, in addition to the basic broker responsibilities. Controllers are responsible for creating/deleting topics and partitions, taking action to rebalance partitions, assign partition leaders, and handle situations when nodes fail or get added. Controllers subscribe to receive notifications from ZooKeeper which track the state of all nodes, partitions, and replicas.
As a publish-subscribe messaging system, Kafka uses uniquely named Topics to deliver feeds of messages from producers to consumers. Consumers can subscribe to a topic to get notified when new messages are added. Topics parallelize data for greater read/write performance by partitioning and distributing the data across multiple brokers. Topics retain messages for a configurable amount of time or until a storage size is exceeded.
Topics can either be preconfigured ahead of time or automatically generated by Kafka when a message doesn’t specify a specific topic. This is the default behavior, but you have the option to change it to prevent automatic topic creations.
Records are messages that contain a key/value pair along with metadata such as a timestamp and message key. Messages are stored inside topics within a log structured format, where the data gets written sequentially.
A message can have a maximum size of 1MB by default, and while this is configurable, Kafka was not designed to process large size records. It is recommended to split large payloads into smaller messages, using identical key values so they all get saved in the same partition as well as assigning part numbers to each split message in order to reconstruct it on the consumer side.
Kafka producers transmit messages to topics and may either allow Kafka to evenly distribute the data to different partitions or choose a specific partition based on a message assignment key’s hash value or the message can specify a partition when transmitted. Producer clients can assign keys to maintain a specific order of messages or to specify a partition semantically based on the data contained in the message. Otherwise, without a key, Kafka defaults to a round-robin approach to distributing the messages evenly across partitions for optimal balance.
Produces are in charge of configuring the consistency/durability levels (ack=0, ack=all, ack=1). This includes setting the number of replicas required to have saved the message before acknowledging it to the partition leader.
Generally speaking, a single producer per topic is more network efficient than multiple producers. As it becomes necessary to increase data throughput, we first want to increase the number of threads per producer if possible, before increasing the number of producers.
When setting up producers, you have the option to configure whether producers wait for acknowledgment from all in-sync replicas (ISRs), just the partition leader, or not at all. The different levels of acknowledgment allow you to strike a balance between data consistency and throughput.
Consumers are applications that subscribe to a topic in order to consume their messages. After a producer sends data to Kafka, it forwards the data to all subscribed consumers. Consumers send an acknowledgment to Kafka upon ingesting the message.
Kafka maintains load balance between Consumers and Partitions by evenly distributing the load between Consumers.
When setting up Consumers, you need to choose when the consumer commits the offset of the message. You several options, each with their own pros and cons.
Consumers are typically grouped by their shared function in a system into Consumer Groups. While Kafka allows only one consumer per topic partition, there may be multiple consumer groups reading from the same partition. Multiple consumers may subscribe to a Topic under a common Consumer Group ID, although in this case, Kafka switches from sub/pub mode to a queue messaging approach.
Kafka stores the current offset per Consumer Group / Topic / Partition, as it would for a single Consumer. This means that unique messages are only sent to a single consumer in a consumer group, and the load is balanced across consumers as equally as possible.
When the number of consumers exceeds the number of Partitions in a Topic, all new consumers wait in idle mode until an existing consumer unsubscribes from that partition. As new consumers join a Consumer Group and there are more consumers than partitions, Kafka initiates a rebalancing. Any unused consumers are used by Kafka as failovers.
The Kafka distributed system partitions and replicates Topics across multiple servers to scale and achieve fault tolerance. Partitions allow us to split the data of a topic across multiple broker servers for writes by multiple producers and reads by multiple consumers. Partitions are either automatically or manually assigned to a broker server within a broker cluster.
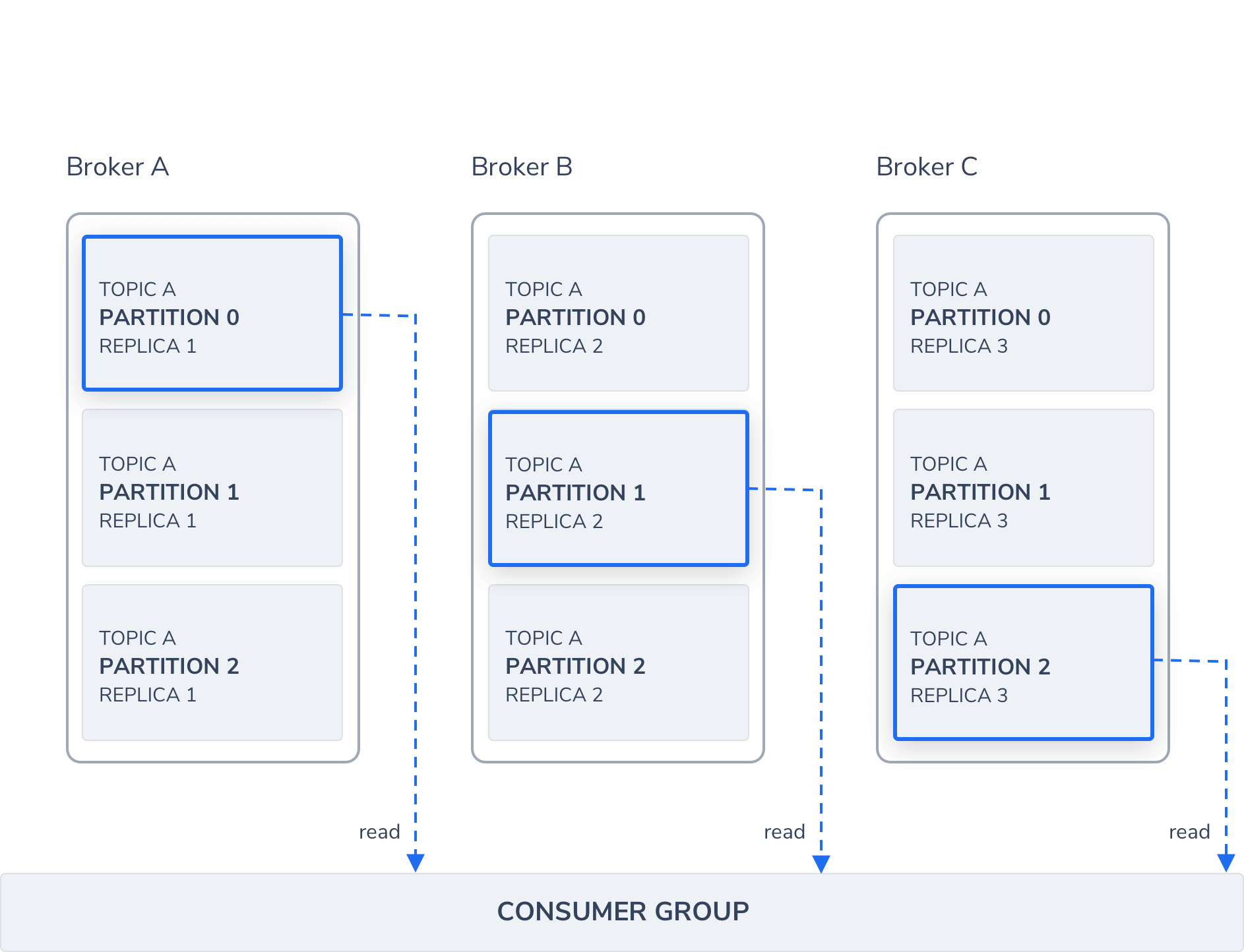
Kafka topics are divided into several partitions, which contain messages in an immutable sequence. A unique sequence ID called an offset gets assigned to every message that enters a partition. These numerical offsets are used to identify every message’s sequential position within a Topic’s partition, as they arrive. Offset sequences are unique only to each partition. This means that locating a specific message requires that you know the Topic, Partition, and Offset number.
Partitions may also be used to split up a large size topic across multiple servers. Being that a partition cannot be split onto multiple servers, in order to scale a Topic beyond a server’s storage capacity, Kafka can use partitions to split the topic data across multiple servers.
Since a single partition may be consumed by only one consumer, the parallelism of your service is limited by the number of partitions contained in a topic.
For stronger durability and higher availability in case of failures, Kafka can replicate partitions and distribute them across multiple broker servers.
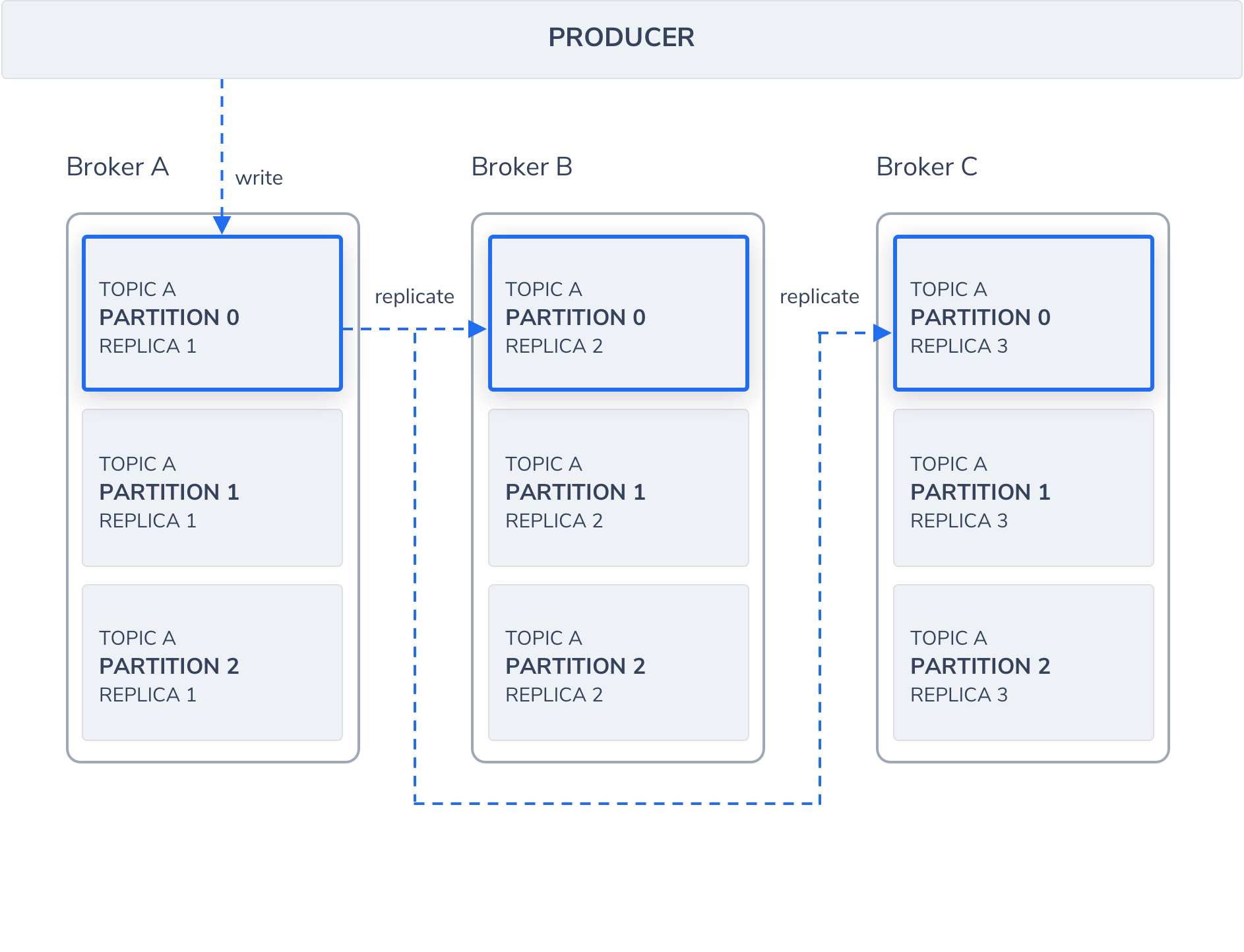
Kafka always designates one Leader partition which is in charge of handling all reads and writes, while Follower replicas only replicate the Leader’s data and take on the Leader role should the designated Leader experience a failure. Followers are designated as in-sync replicas (ISR) when they’re in sync with the Leader, and only ISRs are eligible to become Leaders. You can choose the minimum amount of ISRs required before the data becomes available for consumers to read. Kafka designates the High Watermark (HW) as the last offset in a partition that has been replicated.
The configurability of replicas allow us to configure Kafka for particular types of applications such as one needing high durability compared to another app requiring a lower write response latency.
In Synchronous Replication mode, messages are only available to consumers after all replicas in a partition have confirmed the data was saved via their commit logs. In contrast, the Asynchronous Replication option will make the message available as soon as it’s saved to the partition leader. The downside with the asynchronous approach is the risk of a broker failing and the commit message being lost.
While a leader replica is being replaced (i.e. due to a failure), Kafka may return LeaderNotAvailable errors. In this case, producers and consumers should pause activity until the next leader becomes available in order to avoid data loss.
Kafka Connect is a framework for importing data into Kafka from external data sources or exporting data to external sources like databases and applications. Connectors allow you to move large amounts of data in and out of Kafka to many common external data sources, and also provides a framework for creating your own custom connectors.
Kafka connect comes with the standard Kafka download, although it requires separate setup on a different cluster.
Kafka streams read data from a topic, running some form of analysis or data transformation, and finally writing the data back to another topic or shipping it to an external source. Although Kafka enables this activity with regular Producers, with Streams we can achieve real-time stream processing rather than batch processing. For the majority of cases, it’s recommended to use Kafka Streams Domain Specific Language (DSL) to perform data transformations. Stream processors are independent of Kafka Producers, Consumers, and Connectors.
Kafka offers a streaming SQL engine called KSQL for working with Kafka Streams in a SQL-like manner without having to write code like Java. KSQL allows you to transform data within Kafka streams such as preparing the data for processing, running analytics and monitoring, and detecting anomalies in real-time.
ZooKeeper maintains metadata for all brokers, topics, partitions, and replicas. Since the metadata changes frequently, sustaining ZooKeeper’s performance and connection to brokers is critical to the overall Kafka ecosystem.
Since Kafka Brokers are stateless, they rely on ZooKeeper to maintain and coordinate Brokers, such as notifying consumers and producers of the existence of a new Broker or when a Broker has failed, as well as routing all requests to partition Leaders. ZooKeeper can read, write, and observe updates to data as a distributed coordination service.
Zookeeper maintains the last offset position of each consumer so that a consumer can quickly recover from the last position in case of a failure. ZooKeeper stores the current offset value of each consumer as it acknowledges each message as received so that the consumer can receive the next offset in the partition’s sequence.
Since its launch as an open source project by LinkedIn in 2011, Kafka has become the most popular platform for distributing and streaming data. Any system that moves data around between services and may also need to transform the data in transit will find Kafka is a great fit.
With the shift from traditional monolithic applications to the distributed microservices of DevOps, there is a need for a similar change in operational security policies. For…

Like all programming, scripting is a way of providing instructions to a computer so you can tell it what to do and when to do it….

With progressive delivery, DevOps, scrum, and agile methodologies, the software delivery process has become faster and more collaborative than ever before. Scrum has emerged as a…
