CI/CD Tutorial: How to deploy an AWS Jenkins Pipeline
Valentin Despa
October 13, 2020
Share article
In the previous article, we have created the Continuous Integration (CI) pipeline for a simple Java application. It is now time to start working on the Continuous Deployment (CD) pipeline that will take the Java application and deploy it to AWS. To build the CD pipeline, we will extend the existing AWS Jenkins pipeline. If you have missed the previous article on building Cotinuous Integration solutions for a Java application using Jenkins, make sure you read that first before continuing.
Quick introduction to AWS
Amazon Web Services or simply AWS is a cloud platform offering over 170 cloud-based services available in data centers located worldwide. Such services include virtual servers, managed databases, file storage, machine learning, and many others.
While AWS is the most popular cloud platform, many other providers, including Google Cloud, Microsoft Azure, or DigitalOcean share similar concepts and services to the ones presented here.
In case you don’t already have an AWS account, head over to https://aws.amazon.com/, and create one. You will have 12-months free-tier access, but you still need to enter your billing information and credit card number just in case you go over the free limits.
As a general recommendation, terminate any services once you don’t use them anymore before costs start adding up.
Once you have successfully signed up, you can open the AWS Management console available at https://console.aws.amazon.com/. The console will give you an overview of all the services that AWS has to offer.
AWS Jenkins Pipeline to deploy a Java application
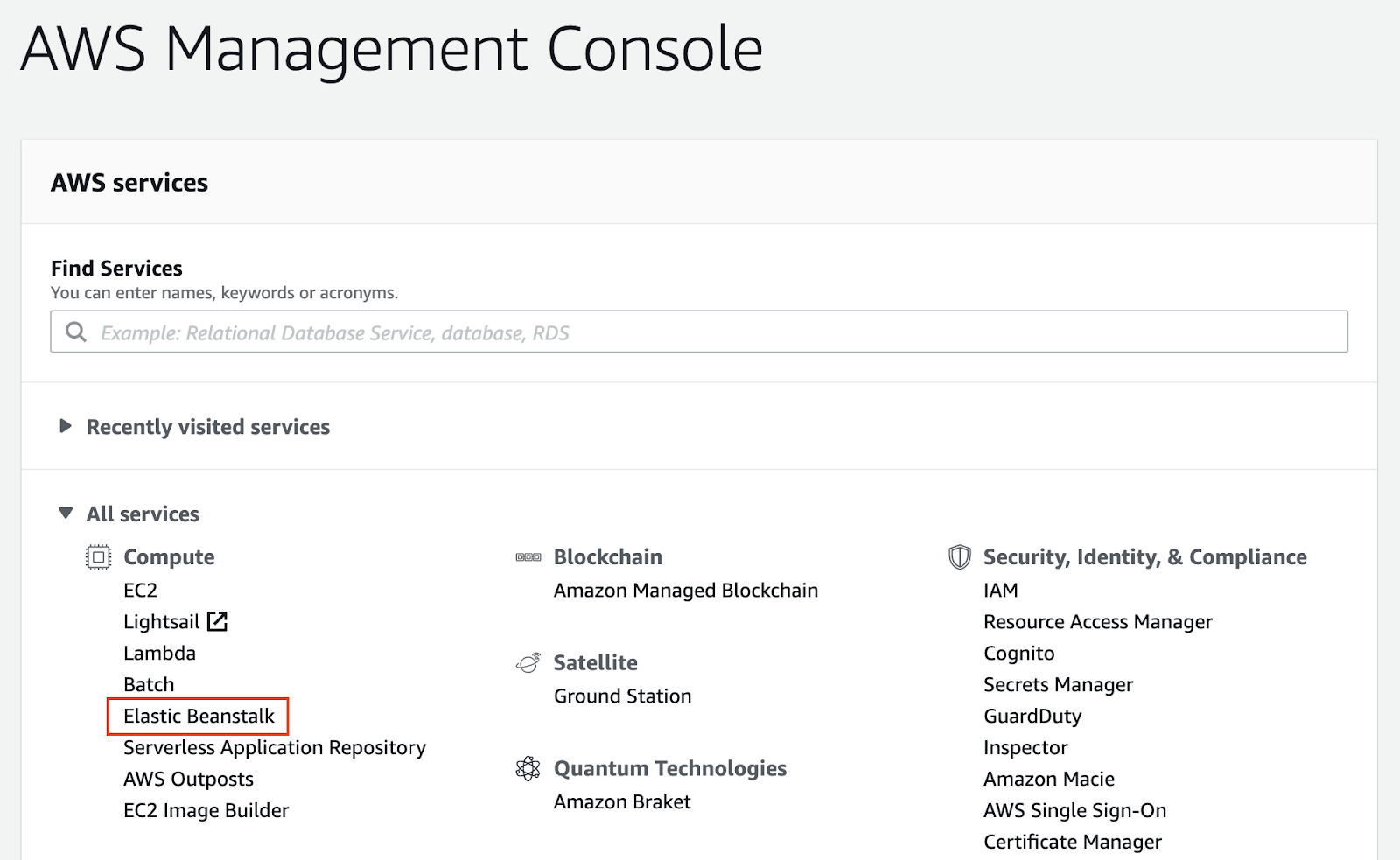
One of the easiest ways to deploy an application to the AWS infrastructure without getting into many technical aspects is using a service called Elastic Beanstalk (EB). From the console overview page, locate the Elastic Beanstalk service.
(01-aws-console.png)
The next step is to create a new application.
(02-eb-create-application.png)
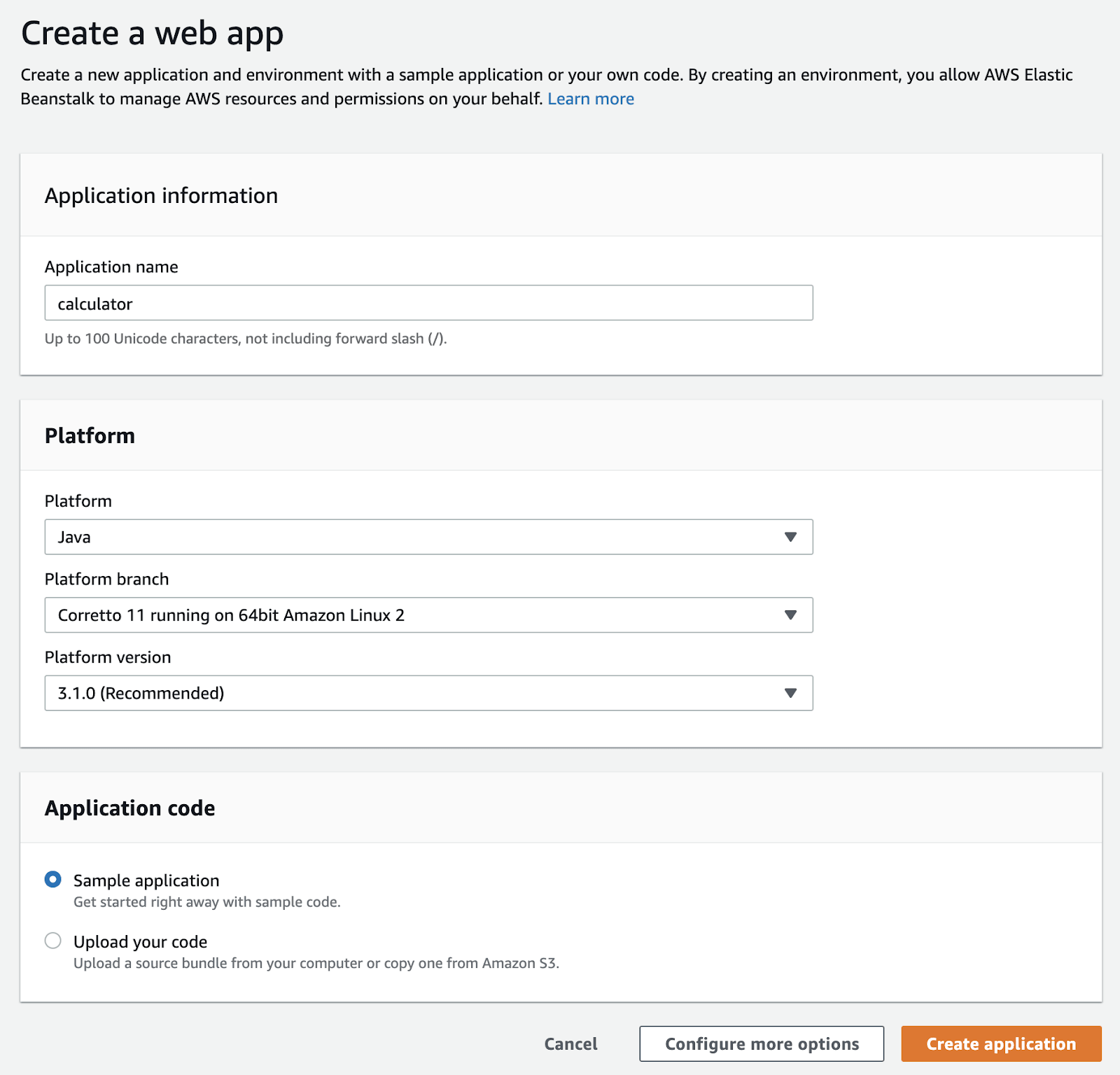
I have named the application calculator, but you are free to call the application as you wish. Since we are trying to deploy a Java application, we need to select the Java platform. Leave the rest of the platform fields to their default values.
(03-eb-new-app-config.png)
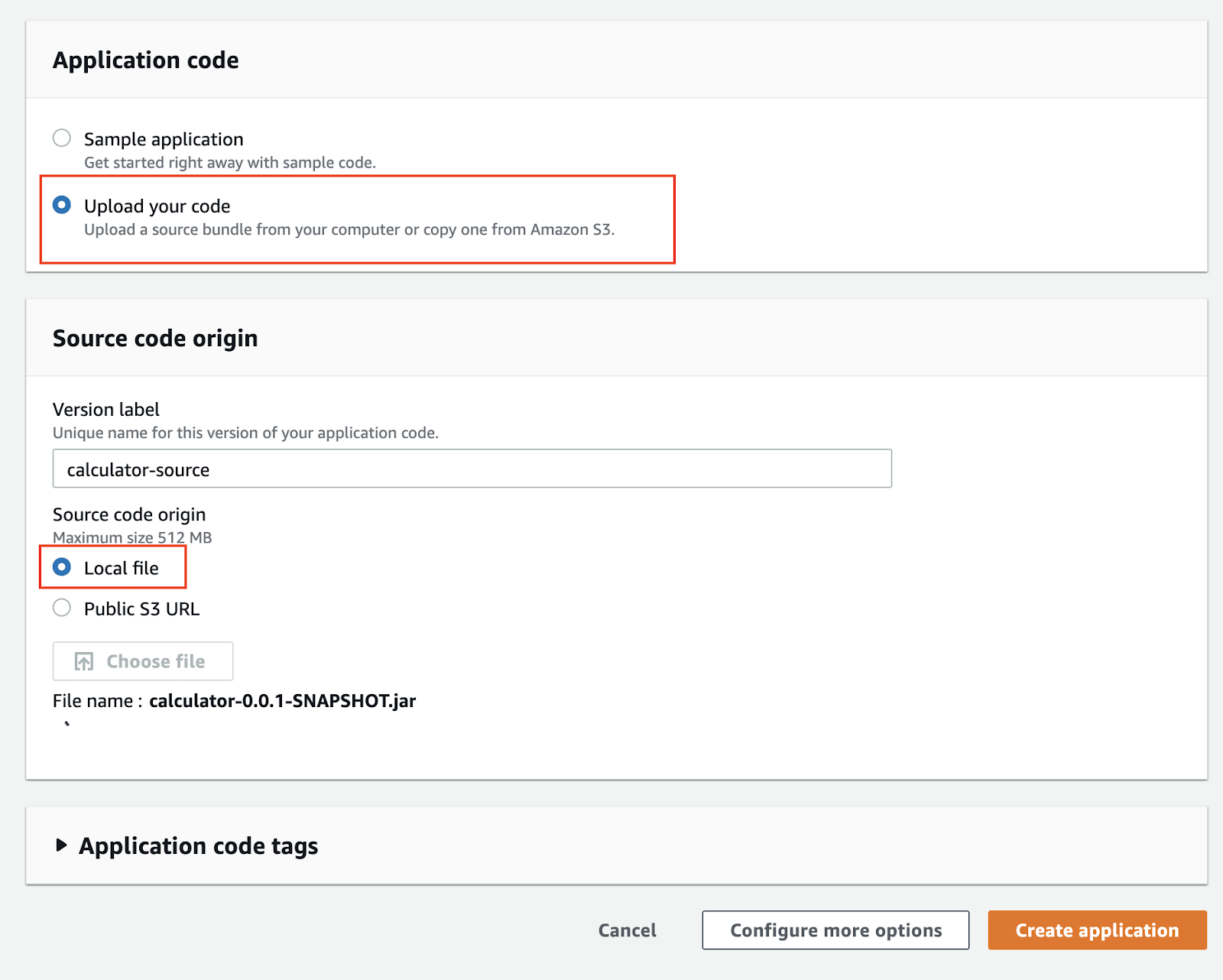
You can start the application with a sample code application, just to see that it is running. Since we already have a packaged Java application in the form of a jar file, we can directly use that.
(04-eb-upload-code.png)
Wait for the file upload to complete. Finally, click on Create application. This may take a few minutes to start.
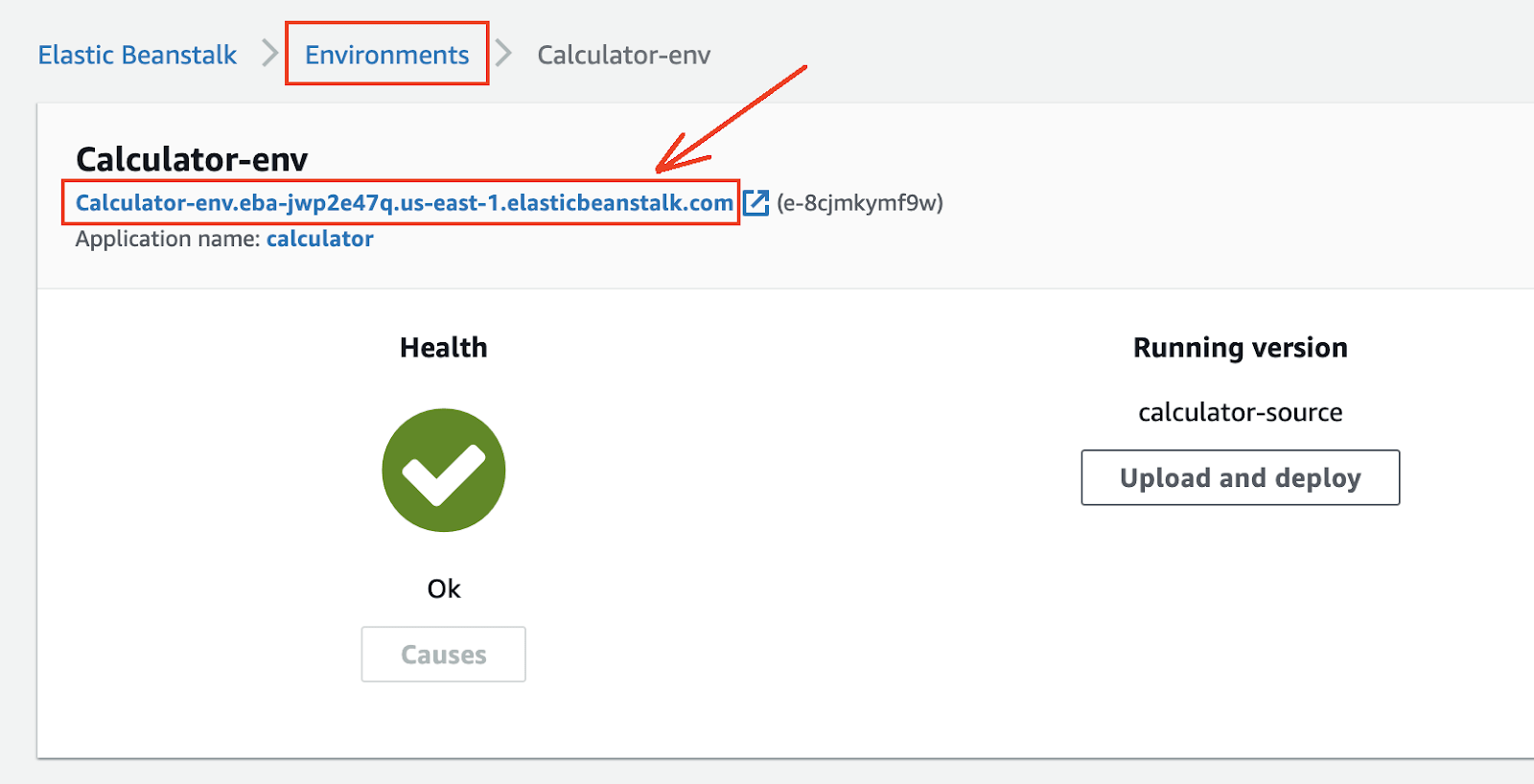
Now click on Environments, select the only environment being displayed, and right on top, you should see the public URL under which the application is available.
(05-eb-environments.png)
If you click on the link displayed, you will get a 404 Not found status code, and that is expected. If you get a different status code, please check the Troubleshooting section within this article. Add /add?a=1&b=2 to the address, and you should see the response.
(06-eb-app.png)
Congratulations! You have just deployed a Java application to AWS with only a few clicks.
How to deploy to AWS from Jenkins
So far, the process has been manual, but it has ensured that our application works on the AWS infrastructure. Since we want to automate this process, we need to use the terminal to do the steps that we did manually.
Fortunately, AWS provides the tools needed to automate this process. The main tool that will allow us to interact with AWS is the AWS CLI, a software tool that has no graphical interface.
The deploy the Java application to AWS from Jenkins, there are a series of steps we need to follow:
Upload the jar archive to AWS S3 (S3 is like Dropbox for the cloud and the main entry point to the AWS infrastructure when dealing with files).
Create a new version of the application within EB by providing the jar achieve, which is now inside S3.
Update the EB environment with the latest application version.
You can easily download and install AWS from https://aws.amazon.com/cli/ . You will find installers for Windows, macOS, and Linux.
(07-aws-cli.png)
After the installation has completed successfully, open any terminal window and run the command aws –version. This will confirm that the installation has been successful and will display the AWS CLI version.
(08-aws-cli-locally.png)
If you have Jenkins installed on macOS, to get AWS CLI to work in Jenkins, you may need to create or adapt the PATH variable with the value: /usr/local/bin:$PATH
How to upload a file to AWS S3 from Jenkins
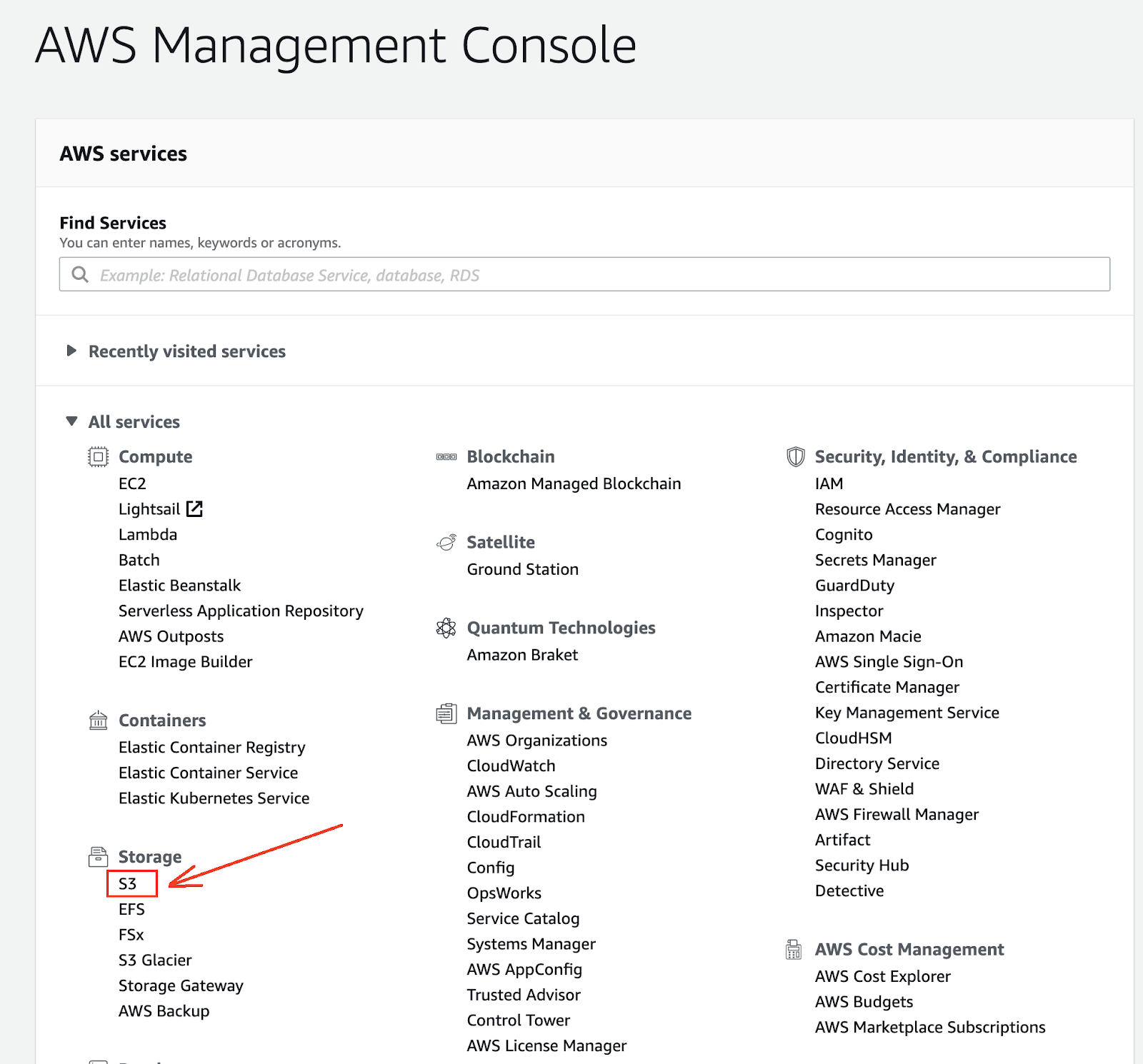
S3 stands for Simple Storage Service and is the gateway to the AWS infrastructure when working with files. You can see it like Dropbox but for the AWS infrastructure. Let’s go back to the AWS Management Console and select the S3 service.
(09-aws-s3.png)
In S3, files are organized in buckets, which are containers for storing data. Inside buckets, you can store files and folders, just as you would do on your computer.
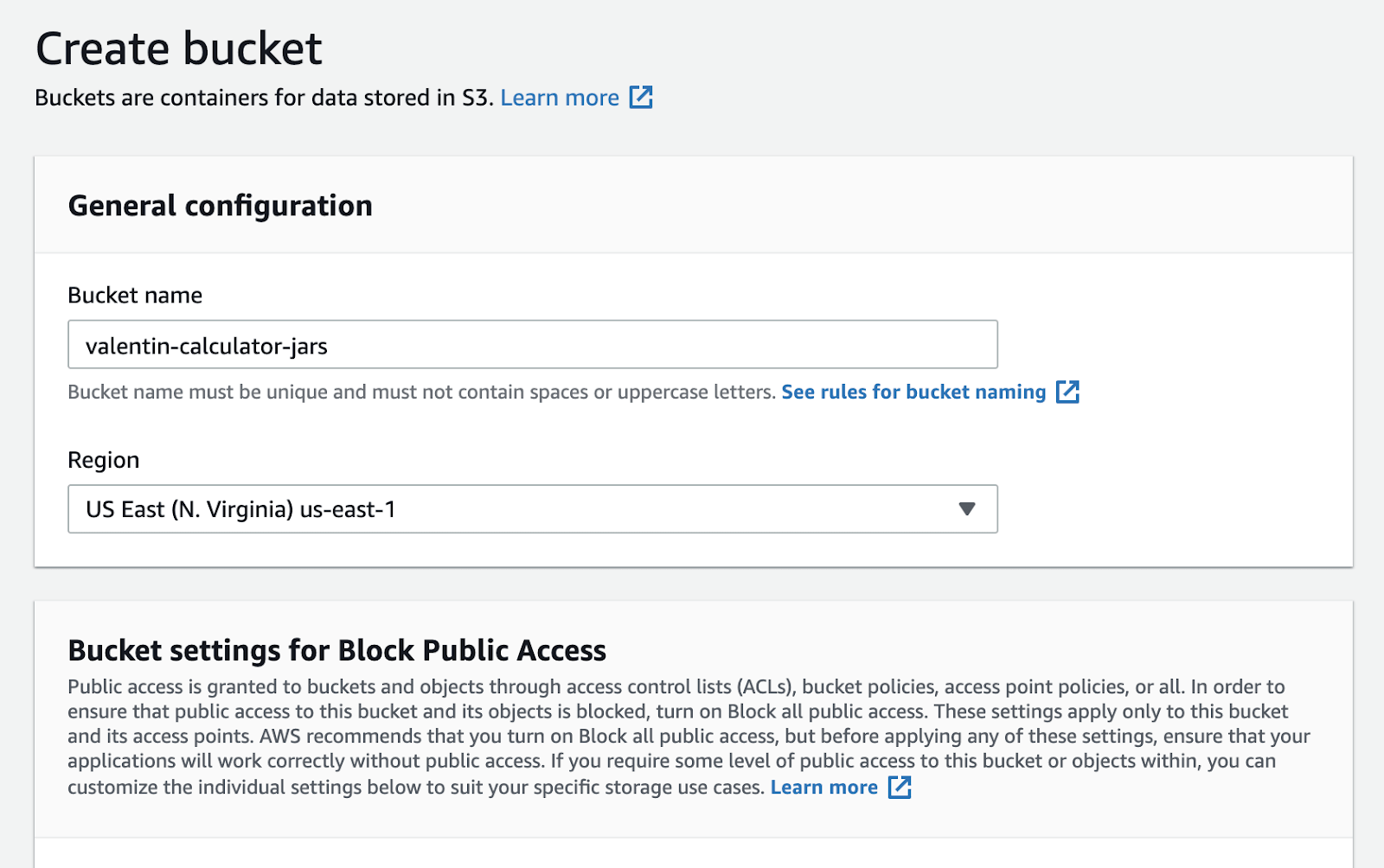
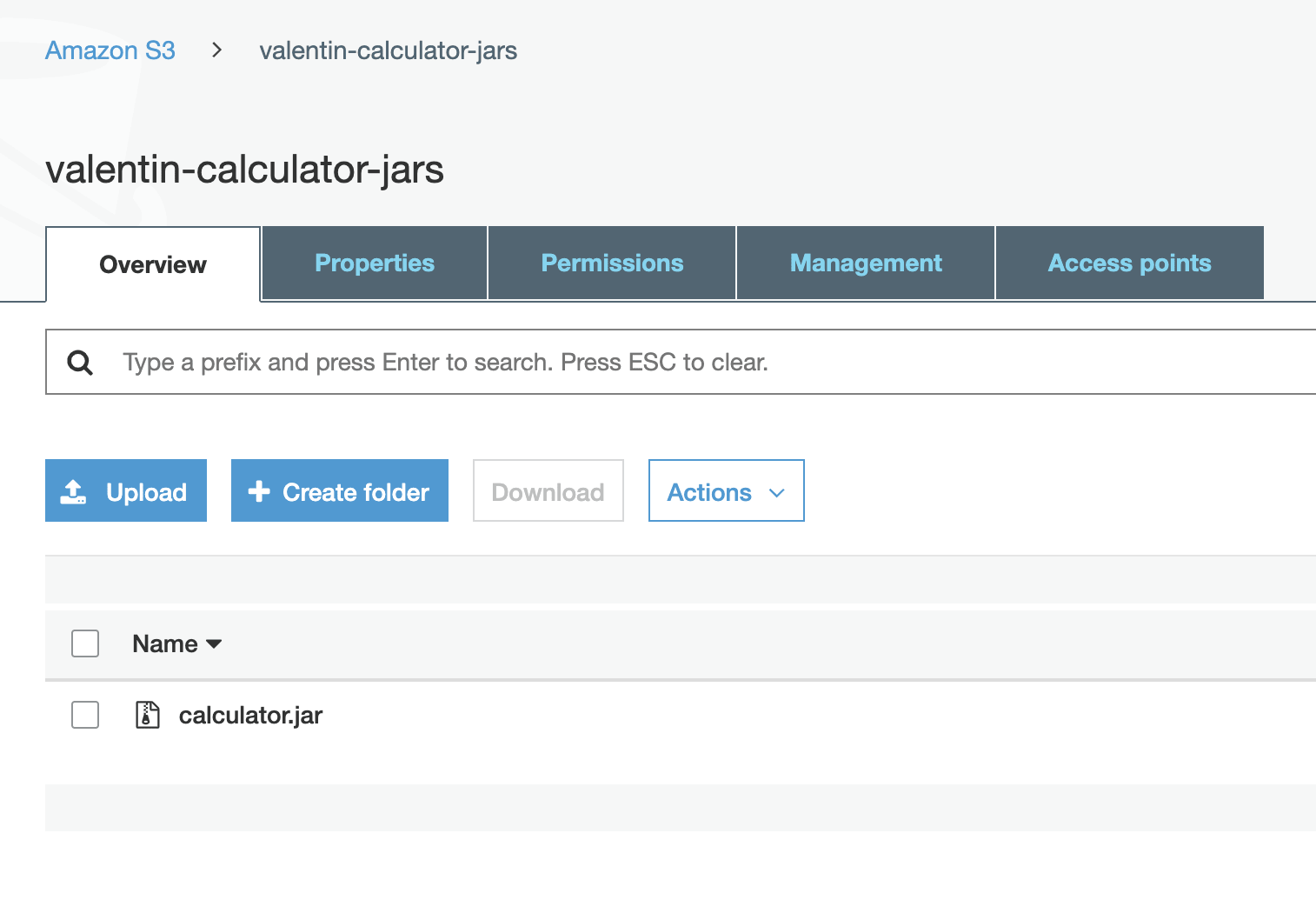
Let’s continue by creating a bucket for storing our jar archives. Your bucket name needs to be unique, and you may face conflicts if you decide to use common names. I choose to prefix the bucket with my name to avoid naming conflicts.
(10-create-s3-bucket.png)
At this point, all you need to do is remember the name of the bucket and the region in which the bucket has been created (in the screenshot above, the region is us-east-1).
To interact with any AWS service from the CLI, we cannot use our AWS account’s username and password. Not only would this be highly risky, but in many cases also impractical. We will create a special user that will only have access to the services required to perform the tasks needed.
For this reason, from the AWS Management console, identify the block Security, Identity, & Compliance and select the IAM service (Identity and Access Management).
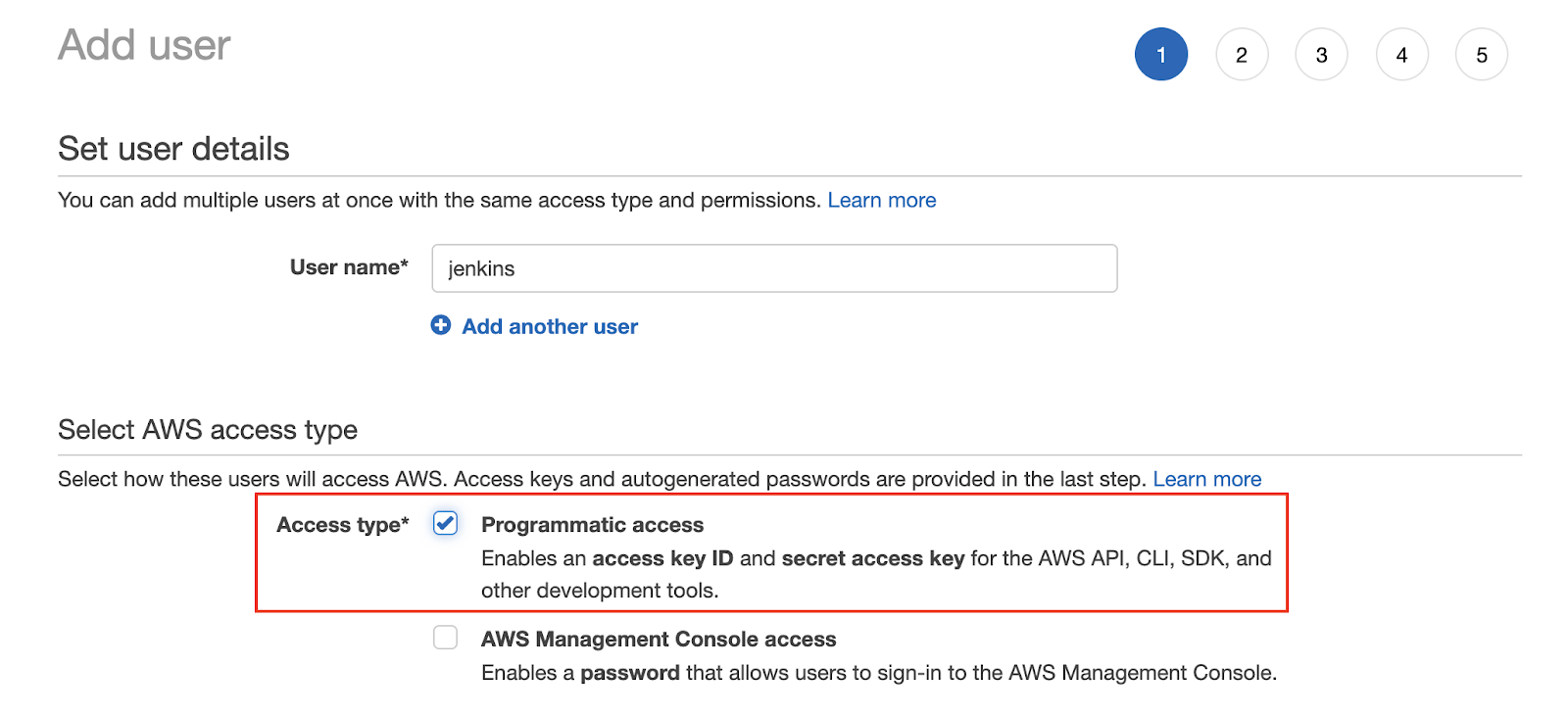
Click on Users > Add user. I will call this user jenkins, so that I can quickly identify it. Make sure to enable the Programmatic access to use this user from the AWS CLI.
(11-iam-user.png)
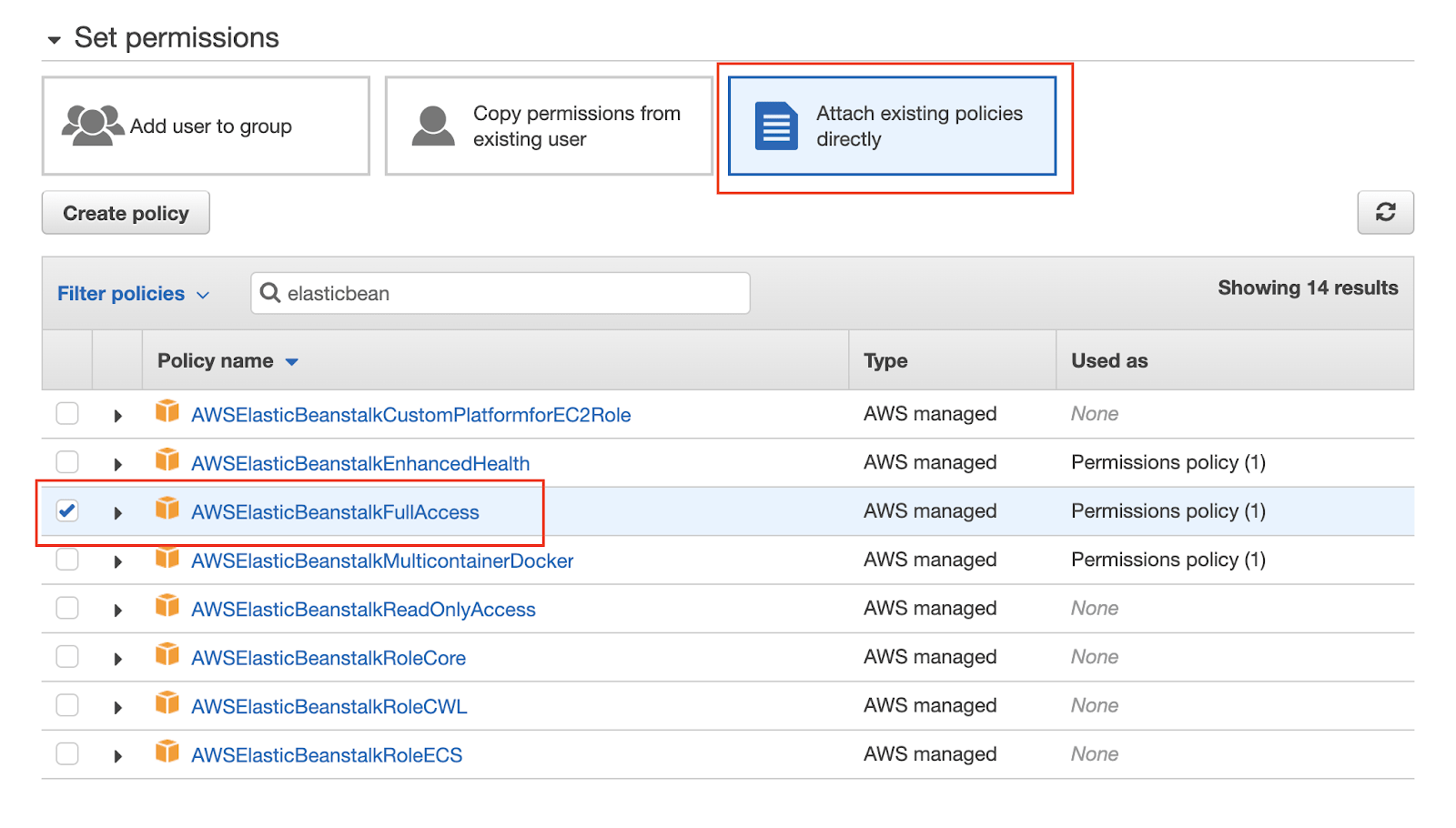
The next step will handle the Permissions that the user will have. We will use some predefined rules to get started. Select Attach existing policies directly. Using the search field, you can search for permissions, which often include the service name. Make sure that the user has the following permissions: AWSElasticBeanstalkFullAccess, AmazonS3FullAccess.
(12-iam-policies.png)
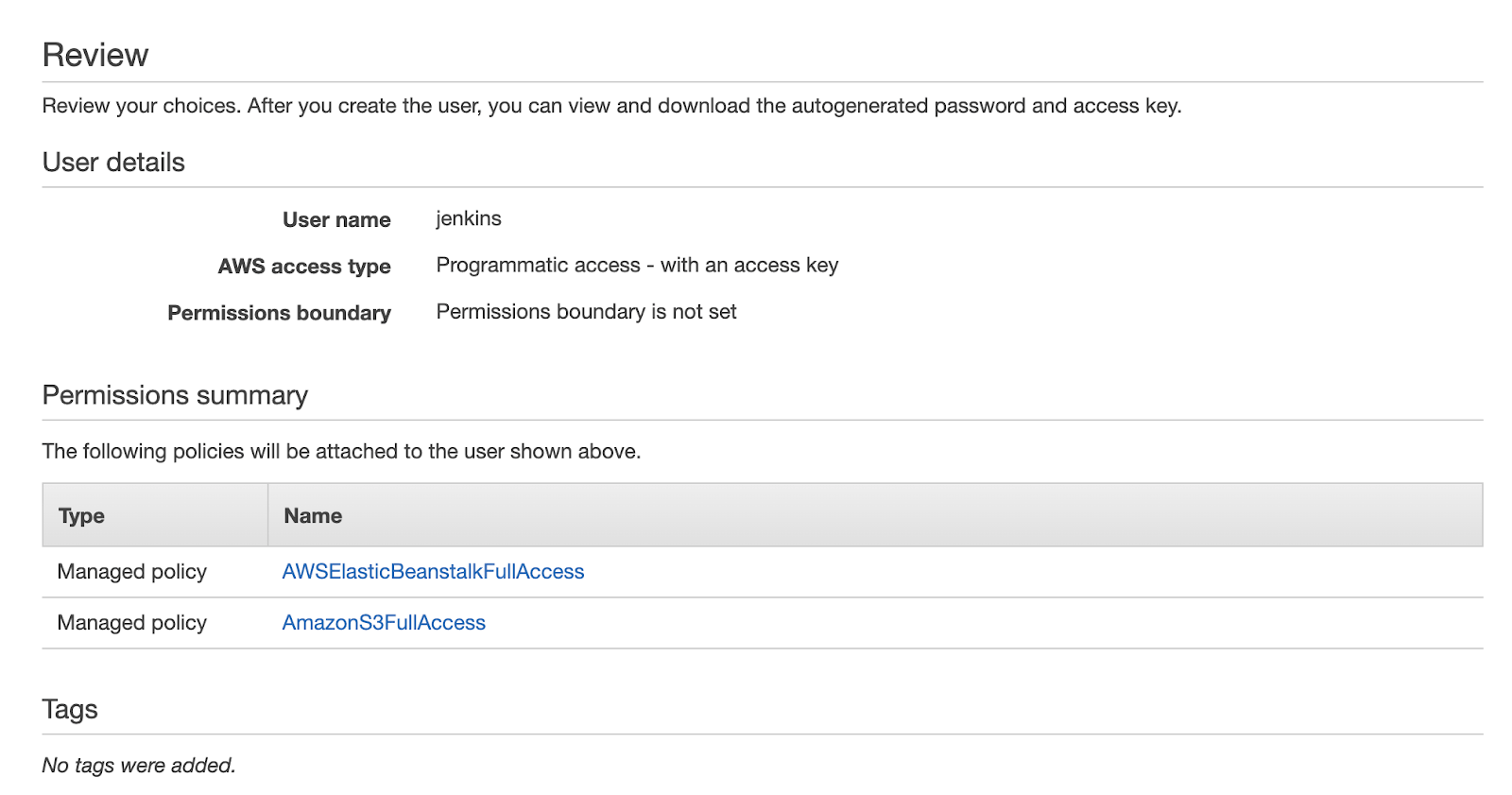
You can skip the Tags page, and on the Review page, your configuration should look very similar to the screenshot below.
(13-iam-review.png)
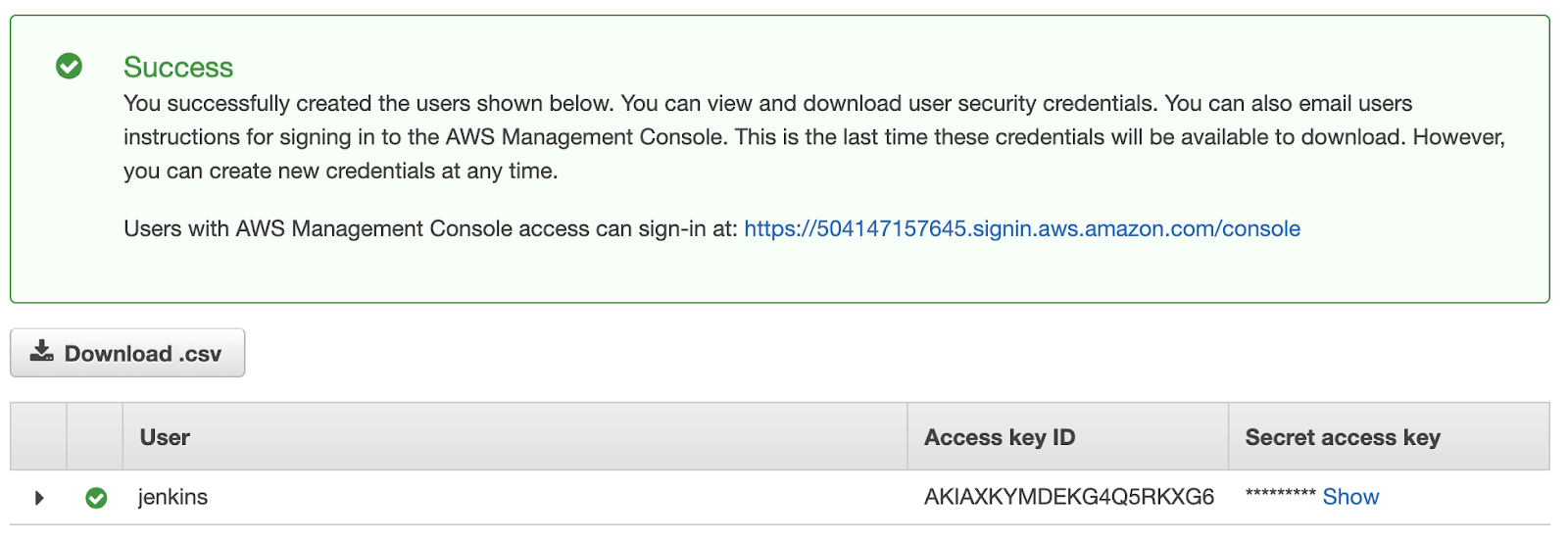
If everything looks right, go ahead and create the user. The final page will display the credentials that have been generated.
(14-iam-user-credentials.png)
Make sure that you store these credentials somewhere safe or keep this page open for a while. They won’t be displayed again. In case you lose them, delete the user and repeat the same process.
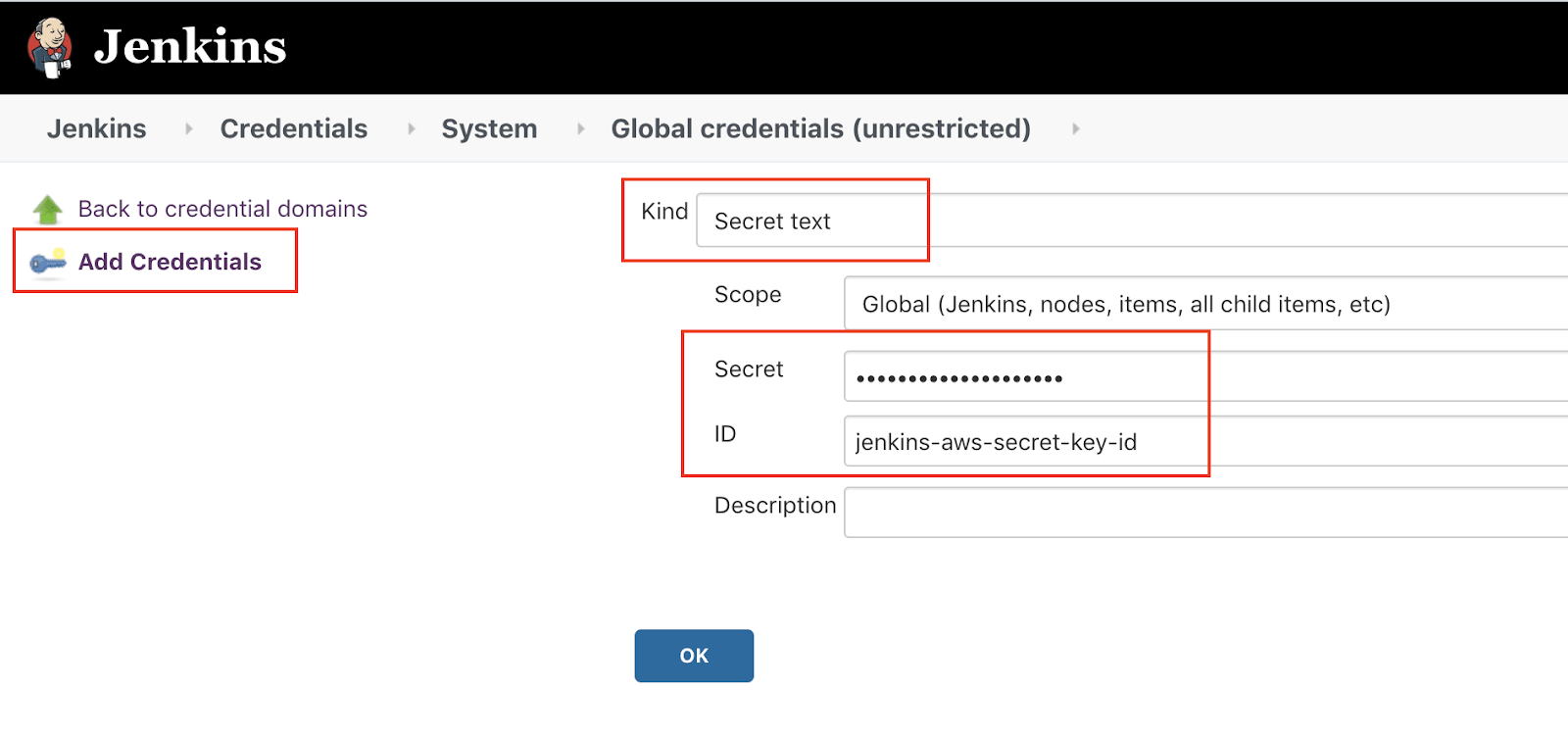
Now it is time to jump into Jenkins and store these credentials so that we can later use them in our pipeline. Go to Manage Jenkins > Credentials and click on the Jenkins store > Global credentials. If you see a menu item called Add Credentials on the right-hand side, you have reached the right place.
Add for both the access key id and the secret access key (two entries in total). I have used the IDs jenkins-aws-secret-key-id and jenkins-aws-secret-access-key.
(15-jenkins-credentials-add.png)
After adding both credentials, the credentials overview page should look similar to the screenshot below.
(16-jenkins-credentials-overview.png)
By using this approach of storing the credentials within Jenkins, we ensure that this sensitive data does not land into our Git repository, and the use of the values will not be displayed in any logs.
The AWS CLI will automatically pick-up the credentials stored in Jenkins, if we expose them as environment variables using a predefined name. The advantage of using environment variables is that many tools will automatically look for predefined names and use them. This makes the commands shorter and easier to read.
Inside the Jenkinsfile inside the pipeline block, add the following lines:
This will instruct Jenkins to create two environment variables (AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY) and initialize them with the values stored in the Jenkins credential store.
Now we have everything in place to use the AWS CLI for uploading the jar archive to AWS S3.
There are two commands that we will execute.
The first command will let AWS know in which region you are operating. In my case, I have used the us-east-1 region for both S3 and EB:
aws configure set region us-east-1
The second command will do the upload from Jenkins to S3:
The copy (cp) command for the S3 service will take two parameters: the source and the destination. During this process, we will rename the jar file.
We will add both of these commands inside the success block of the publishing stage. The simplified pipeline after this step will look as follows:
pipeline { agent any environment { AWS_ACCESS_KEY_ID = credentials('jenkins-aws-secret-key-id') AWS_SECRET_ACCESS_KEY = credentials('jenkins-aws-secret-access-key') }
stages { stage('Build') { // build stage } stage('Test') { // test stage } stage('Publish') { steps { sh './mvnw package' // bat '.\mvnw package' } post { success { archiveArtifacts 'target/*.jar' sh 'aws configure set region us-east-1' sh 'aws s3 cp ./target/calculator-0.0.1-SNAPSHOT.jar s3://YOUR-BUCKET-NAME/calculator.jar' // bat 'aws configure set region us-east-1' // bat 'aws s3 cp ./target/calculator-0.0.1-SNAPSHOT.jar s3://YOUR-BUCKET-NAME/calculator.jar' } } } }}
Note: If Jenkins is running on Windows, use bat inside of sh.
If the pipeline’s execution does not indicate any errors, you should soon see the jar archive inside the newly created S3 bucket in your AWS account. Please check the Troubleshooting section at the end of the article if you notice any errors in the console.
(17-s3-upload-done.png)
How to deploy a new application version to AWS EB from Jenkins
Since we will start handling many parameters in the following commands, it is time to clean-up the pipeline code and organize all variables. We will begin to define new environment variables that will store the application-specific configuration. Make sure that the following values match the values you have configured in AWS.
The first step in deploying a new version to EB is to create a new application version, by referencing a new jar artifact from S3 and specifying the application name and the artifact version.
On an Unix-like system you will access environment variables using the notation $VARIABLE_NAME while on a Windows system the notation will be %VARIABLE_NAME%.
Please note that this command will only create a new application version ready for usage in EB, but it will not affect the existing running version.
To deploy a new application version, we need to use the update-environment command. This command will only work if we use a version that has already been created previously. The command options will be similar to the create-application-version command.
stage('Publish') { steps { sh './mvnw package' // bat '.\mvnw package' } post { success { archiveArtifacts 'target/*.jar' sh 'aws configure set region us-east-1' sh 'aws s3 cp ./target/calculator-0.0.1-SNAPSHOT.jar s3://$AWS_S3_BUCKET/$ARTIFACT_NAME' sh 'aws elasticbeanstalk create-application-version --application-name $AWS_EB_APP_NAME --version-label $AWS_EB_APP_VERSION --source-bundle S3Bucket=$AWS_S3_BUCKET,S3Key=$ARTIFACT_NAME' sh 'aws elasticbeanstalk update-environment --application-name $AWS_EB_APP_NAME --environment-name $AWS_EB_ENVIRONMENT --version-label $AWS_EB_APP_VERSION' } } }
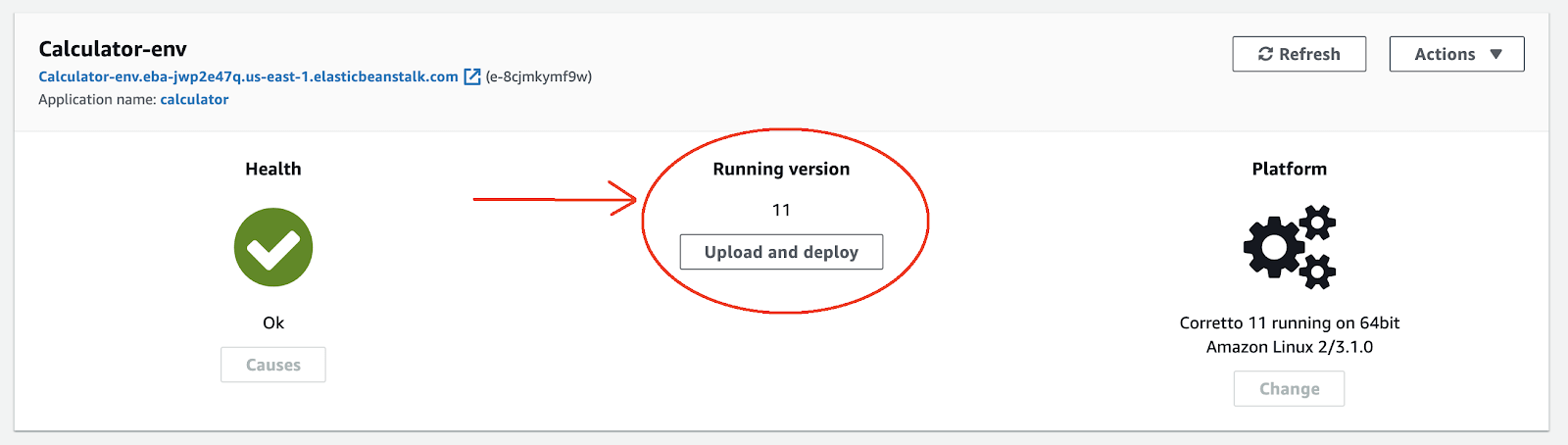
If you look inside the AWS console, you should be able to notice the latest version available.
(18-ec-new-version.png)
Troubleshooting tips
Deploying to AWS is a complex topic, and errors sometimes occur, often due to mistakes in the pipeline configuration. Below you will find some ideas on how to troubleshoot some of the most common errors.
How to find errors in the Jenkins console logs
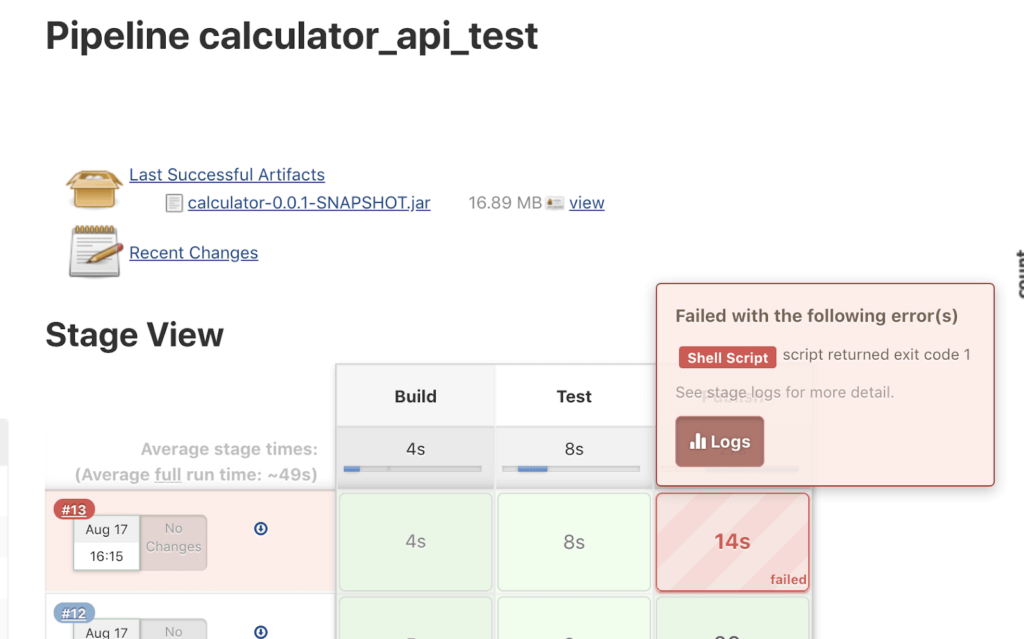
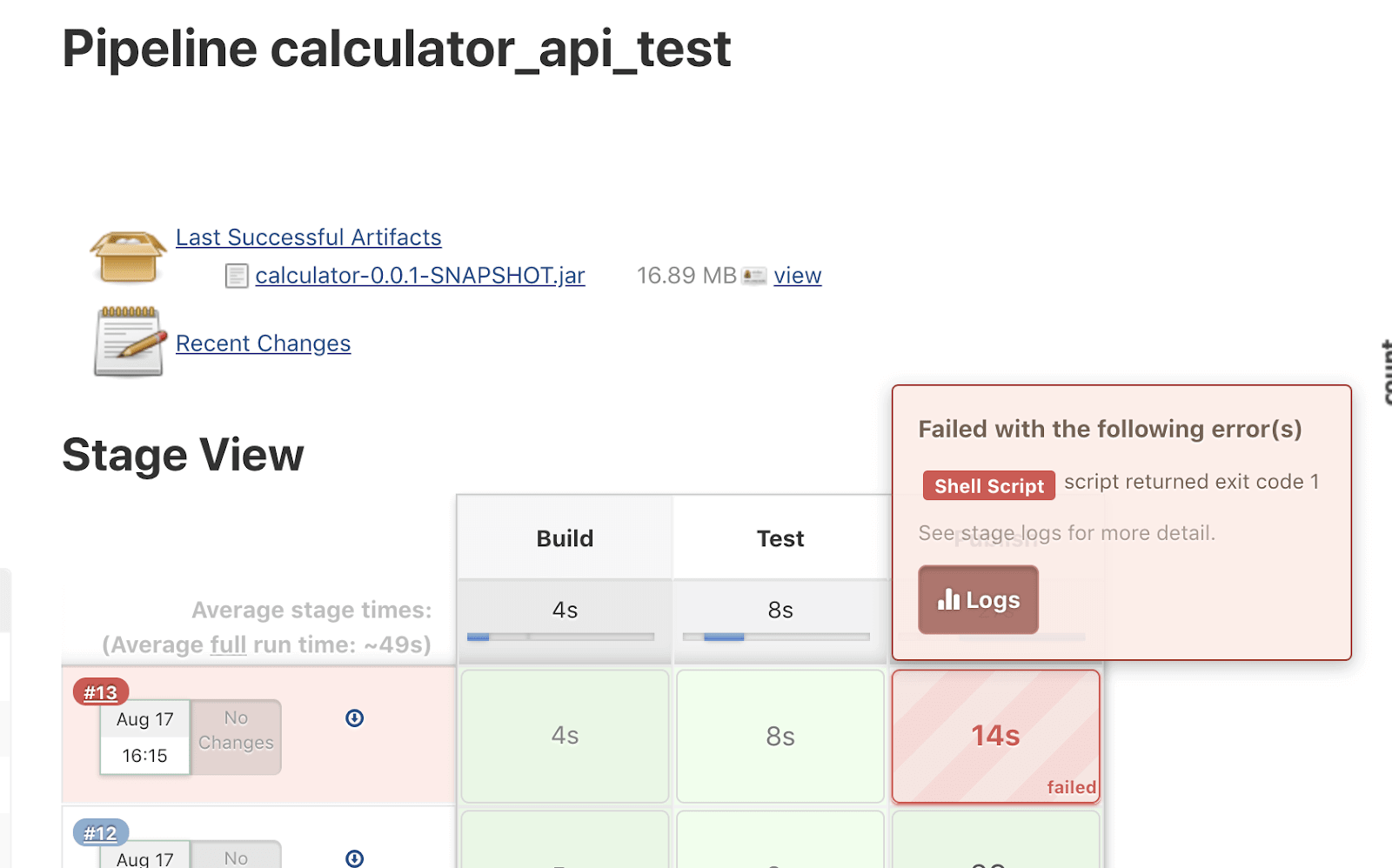
Should the pipeline fail at any stage, it is essential to read the logs for hints on what has failed. You can view the logs by clicking on the build number or clicking on the failed stage.
(19-jenkins-error-logs.png)
Try to identify the error and the command that has generated the respective error.
S3 upload failed – Unable to locate credentials
This error is an indication that the AWS CLI was unable to read the environment variables that contain the credentials needed: AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY. Make sure that both variables are defined and correctly spelled.
S3 upload failed – Invalid bucket name “”: Bucket name must match the regex
Take a look at the entire aws s3 cp command in the Jenkins logs. You may notice that the bucket name is empty. This is typically due to a missing or misspelled environment variable.
An error occurred (InvalidParameterCombination) when calling the CreateApplicationVersion operation: Both S3 bucket and key must be specified.
Take a look at the entire aws elasticbeanstalk create-application-version command in the Jenkins logs. You may notice that the S3Bucket or S3Key is empty.
The application endpoint responds with 502 Bad Gateway
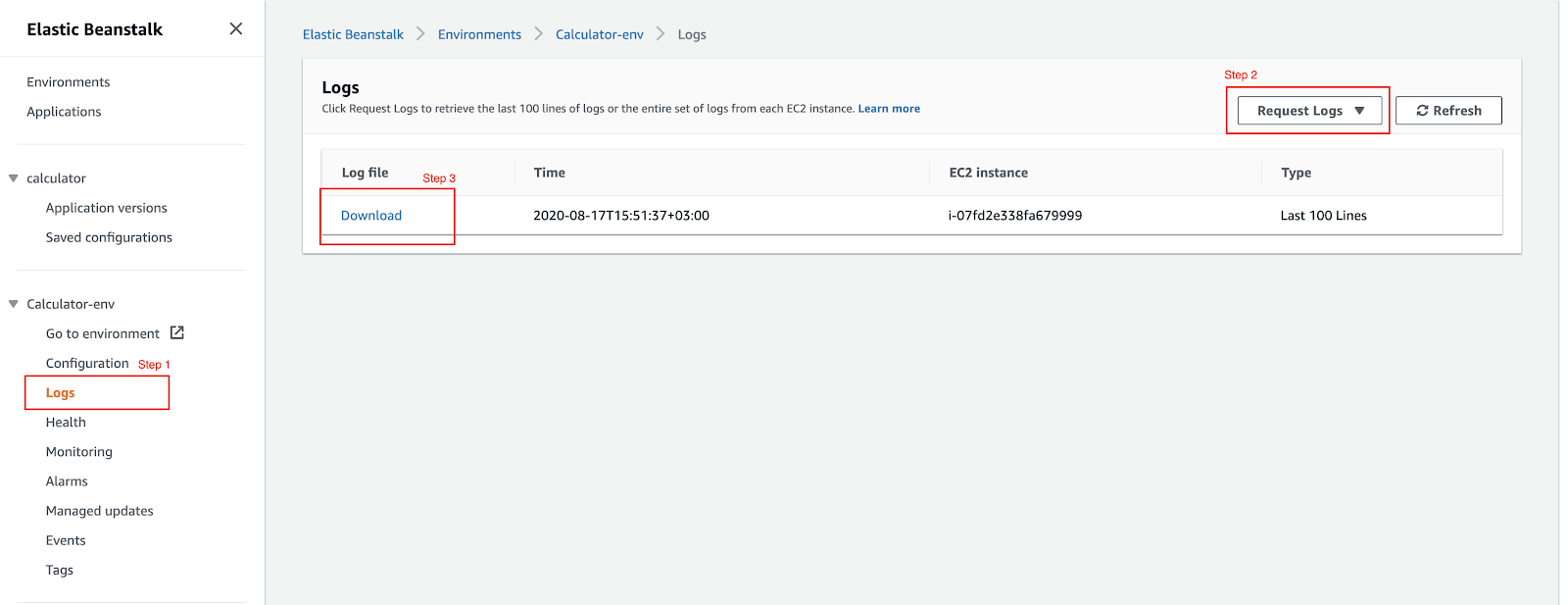
This is an indication that the application had some issues starting. It is hard to tell the root cause precisely, but the first place where you can look for hints is in the application logs. To get them, go to the respective environment and select the menu item called Logs.
(20-ec-app-logs.png)
From the list with Request Logs, get the last 100 entries. Once the logs are available, click on Download.
‘aws’ is not recognized as an internal or external command error in Jenkins
This is an error indicating that the aws command could not be found by Windows. The first step is to restart the computer and in many cases this will solve the problem.
Conclusion and next steps
We now have the foundation for a simple but fully working CI/CD pipeline. While we are building, testing, and deploying a Java application to AWS, this solution is not production-ready.
The CI pipeline may include additional code review, code quality, test or security stages to ensure the artifact fulfills all requirements before attempting a deployment.
For the CD pipeline, you may also want to include additional environments and tests to ensure that a deployment to the production environment will work without any issues.
CI/CD pipelines have become a cornerstone of agile development, streamlining the software development life cycle. They allow for frequent code integration, fast testing and deployment. Having…
Continuous Integration/Continuous Delivery (CI/CD) has now become the de-facto standard for all engineering teams seeking to keep pace with the demands of the modern economy. At…
Continuous integration (CI) and continuous delivery or deployment (CD) cover the process of automatically merging, building, and testing code changes ready for release, and – in…
Where Modern Observability and Financial Savvy Meet.