Thousands of Insights at a Glance With Coralogix Alert Map
An effective alerting strategy is the difference between reacting to an outage and stopping it before it starts. That’s why at Coralogix, we’re constantly releasing new…

During one of our data-munging sessions here at Coralogix, we found ourselves needing to assess the cardinality of large data sets. Getting the accurate result is seemingly trivial: you simply iterate over the data and count the number of unique elements. In reality, however, the task is more troublesome, mainly due to three constraints: process time-complexity, process space-complexity, and distributed processing. Surprising, isn’t it?
Many real-time algorithms require the execution of many queries every second and are thus tightly time-bound. In these cases, even dealing with small data sets can become a problem – as iterative counting may slow the algorithm down too much for real-time purposes.
On the other hand, when dealing with Big Data, issues arise from the space-bounded hardware. The data cannot be completely loaded into memory, limiting performance to reading from the hard drive, which is unacceptable.
Another problem comes into mind when dealing with Big Data: scaling-out. In this case, reaching consensus among different machines is necessary without replicating all the data in one place for checking uniqueness.
One solution for these problems is to give up precision. However, this is not easily done. In this blog post, we’ll explore an intriguing cardinality estimation algorithm: HyperLogLog.
HyperLogLog is an ingenious solution for Big Data, estimating the number of unique elements in huge datasets with 98% precision, with a memory footprint of only ~1.5kB!
I know, that sounds crazy. But trust me, the math works.
The idea behind HyperLogLog is to use the statistical properties of hash functions while avoiding the need to keep the hashes themselves. Briefly, each element is inserted into a hash function, and the number of sequential trailing 1’s (or 0’s) is counted. This integer is all you need.
A good hash function assures us that each bit of the output sequence is independent of the others, thus having an equal probability (50%) of being set to 1 – similar to tossing a coin. The probability of randomly stumbling upon a sequence of (n) 1’s is thus $latex 1 / 2^n$. Accordingly, looking at it the other way around, we would need to hash ~$latex 2^n$ unique elements in order to stumble upon a sequence of (n) trailing 1’s in one of the hashes. A naïve algorithm would simply return this figure as an estimation for the number of unique elements in a list. However, using only one hash function is prone to a lot of error – it’s enough for one element to incidentally receive a hash value with many trailing 1’s for the estimation to become extremely biased.
On the other hand, utilizing many hash functions is costly – as each hash calculation requires an O(n) operation. Additionally, finding a family of several hundred or even a thousand good distinct hash functions (for increased accuracy) is also a difficult task.
To solve these problems, HyperLogLog utilizes stochastic averaging:
Instead of keeping a single integer for the estimation (“1 bucket”), HyperLogLog introduces many ($latex 2^k$) registers, or “buckets”, which will be averaged when estimation is requested.
How are these buckets being updated? During insertion, each element is run through one good hash function, and the resulting hash value is broken into two pieces. The first k bits are converted into the integer index of the target bucket among our $latex 2^k$ buckets. On the remaining bits of the hash value, we count T – the length of trailing 1’s. If this T is bigger than the current register value, that register is updated accordingly; otherwise, we move on to the next element. This way we get an ensemble of $latex 2^k$ estimators for the cardinality of our data set.
(neustar research has built an awesome online demo of HyperLogLog demonstration which makes all this much more comprehendible: http://bit.ly/1GvbD3S)
When an estimation is requested, we just average the register values –
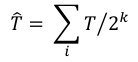
and output the estimation as before –
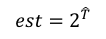
However, the arithmetic mean is sensitive to extreme values and may introduce higher estimation error. This issue is tackled by using the harmonic mean instead, which is much better when dealing with such values. These 5 simple lines of Python code emphasize this nicely:
>>> from scipy import mean
>>> from scipy.stats import hmean as harmonic_mean
>>> values = [1]*999 + [100000]
>>> mean(values)
100.999
>>> harmonic_mean(values)
1.0010009909809712
Of course, the more registers you have, the more accurate your result can get. To show this, we’ve run a small data set with about 250,000 unique elements through HyperLogLogs with different sizes. The figure below demonstrates how much more effective it is:
As you can see, the dark line, which represents an HLL with $latex 2^{16}$ registers, is closest to the 0 error line – with very little error variance and averaging at an impressive 0.000223% error across the board!
Another case this algorithm brings forth is the straightforward solution for distributed processing: when combining results from several machines each running HyperLogLog with the same hash function, all that is needed is to keep the maximum value between all pairs of matching registers for the cardinality of the whole system!
Summing up, cardinality estimation with HyperLogLog is extremely efficient when dealing with Big Data sets – keeping the error within a few percentages of the actual state. The process can run on distant machines, requiring minimum coordination or data exchanges. And all this is done while typically using little more than a kilobyte of state data per machine.
Truly state of the art.
Python has a nice built-in function called hash(), which is seemingly appropriate for hashing purposes. However, it is not considered a good hash function, and it is not even intended for real-world hashing at all!
For example, Python hashes every integer into itself, violating an important property where similar, but not identical, inputs hash into dissimilar outputs:
>>> hash(1135235235)
1135235235
>>> hash(-135235)
-135235
>>> hash(0)
0
>>> hash(1)
1Additionally, the underlying Cython implementation uses (-1) as an error code. Accordingly, no input can get this hash value, returning instead (-2):
>>> hash(-2)
-2
>>> hash(-1)
-2
>>> id(-2) == id(-1)
FalseLastly, since Python 2.7.3/Python 3.2.3 each python process initializes the hash() function with a different seed, resulting in a totally different hash value for identical inputs across runs:
>>> hash("different results on every run") # python process #1
4996284735471201714
>>> hash("different results on every run") # python process #2
5097553022219378483This is a security feature, to prevent an attacker from designing a set of inputs that will always collide in internal hash-tables, intentionally resulting in a very long processing time (and an actual denial of service attack in the meantime).
For these reasons, I’d recommend using a non-cryptographic and fast hash function, such as Murmur3 or the like.
Further reading:
The original HyperLogLog article, by P. Flajolet –
HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm
http://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf

An effective alerting strategy is the difference between reacting to an outage and stopping it before it starts. That’s why at Coralogix, we’re constantly releasing new…

If you’re just getting familiar with full-stack observability and Coralogix and you want to send us your metrics and traces using the new OpenTelemetry Community Demo Application,…

In the world of data observability, there are several distinct problems to solve. Fast queries, intuitive visualizations, scalable storage, and more. The technical problems receive the…
