
Un-observable AI is Un-trustworthy AI


Recently, someone talked Chipotle’s customer support agent into reversing a linked list – a task completely unrelated to burritos in any way. Screenshots circulated, people laughed, but underneath the joke sat a sharper question. If a production support agent will do that on a public channel, what else will it do that nobody is screenshotting? The bug is funny. The trust gap behind it is not.

Trust in a complex system has never been about understanding the thing itself. Most of us trust planes without being able to explain how a turbofan works, and we trust anesthesia without ever having read a pharmacology paper. What we trust is the system around the thing. Regulators, certifications, audits, black box recorders, post-incident reviews, the years of training behind every person in the cockpit. The plane is unknowable to almost everyone on board. The system around it is what you’re actually trusting when you sit down in seat 14C.
Large language models sit at an even higher level of abstraction. Not even the people training them can fully reconstruct why a model produced one answer instead of another for a specific input. Inputs and outputs don’t resolve back to a deterministic graph of logic. So if we want trust in AI (and given how much of it is already in production we probably do), we have to build what aviation built: a system around the model that produces evidence.
That system is observability. For a lot of teams, it’s the thing missing.
Three properties of agentic AI that break observability
Execution paths are unpredictable: the same query can take three tool calls or twelve, which makes request-level latency metrics like p95 lose meaning. Resource usage tracks decisions rather than traffic, so a single input can resolve in one LLM call or expand into a multi-step reasoning chain with retries, blowing up capacity planning and FinOps in the same move. Finally, when something goes wrong, the decision flow is obscured: tool calls may not have been logged in full, agent decisions will not reproduce, and “we don’t know why it did that” stops being an internal embarrassment and becomes a compliance problem under the EU AI Act for high-risk applications.
These aren’t bugs to be fixed in the next training run. They’re properties of how the technology works. The fix is to wrap the model in instrumentation that produces evidence about its behavior.
Different stakeholders need different evidence
There are three key groups that need to trust an AI application, and each one needs different evidence.
Users want reliability, and trust here is fragile: one off-task answer is enough to start them wondering what else they can’t see.
Leadership needs to trust the application is worth running. Gartner has predicted that more than 40% of agentic AI projects will be canceled by the end of 2027 due to “escalating costs, unclear business value, or inadequate risk controls.” Neither cost nor risk is something leadership can evaluate without seeing it concretely.
Developers need to trust the tools they build with. Claude Code, Codex, and Cursor now sit in the critical path of how software gets shipped. LeadDev’s 2026 State of AI Driven Software Releases report shared that 52% of respondents found the biggest challenge to using these tools was a lack of clear metrics to evaluate the impact on productivity. The trust developers extend to coding agents has direct downstream effects on what gets shipped, how fast, and how often it breaks.
Three audiences, three sets of questions, one artifact that answers all of them: a record of what the system actually did, captured in a format the team already knows how to query.
The Foundation: OpenTelemetry
OpenTelemetry is the foundation that makes that record possible. The CNCF annual survey reports that more than 60% of engineering teams use OpenTelemetry or are evaluating it, making it the second-largest CNCF project. The OpenTelemetry semantic conventions for generative AI mean a multi-team, multi-model deployment can standardize attributes across the stack rather than inventing a private vocabulary. Auto-instrumentation handles the model call itself. The work that earns the trust sits in four layers above and around it. Coralogix has end-to-end OpenTelemetry support, so the data lands in a backend that already knows the conventions.
What to instrument, in four layers
Layer 1: Development
The first layer is the coding agents writing the code that ships. Agentic coding tools like Claude Code and Codex already emit telemetry via OTLP, the OpenTelemtry protocol. Data like token usage, tool latency, code change volume, acceptance and rejection rates per session is just the start of the information you can gather. Pointed at an observability backend, this telemetry answers questions teams have, until now, been blind to: which model is producing code that actually ships, which teams are accelerating, and which sessions are burning tokens generating code that gets thrown away. Acceptance rate per team, cost per commit, and the correlation between AI adoption and DORA metrics like lead time and change failure rate are all measurable from data that is already being produced.

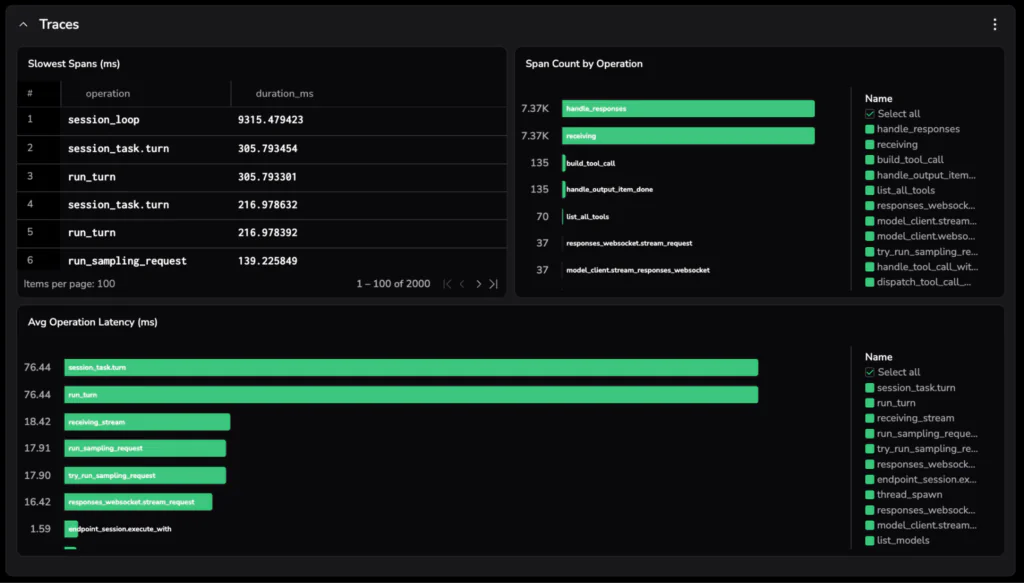
Layer 2: Operational
The second layer is operational metrics for the AI application itself in production. Total tokens and total spend are the surface. Underneath, the questions worth answering are which users, features, and models are driving the spend, how often max-token limits are clipping responses (a length finish reason is an underrated signal of operational issues that look like successes), and whether high-spend users are doing meaningful work or stuck in retry loops. This is the layer where leadership starts being able to defend the AI line item, and where FinOps starts having something concrete to optimize against.

Layer 3: Decision Path
The third layer is decision-path tracing. Logging inputs and outputs tells you that something happened. It doesn’t tell you why. The shift is to wrap the agent loop in a span, every turn through the loop in a child span, every tool call in its own span, and every plan adjustment in a span that records what changed and what triggered the change. With that in place, “the agent returned the wrong answer” turns into “the agent retrieved outdated context, called the pricing API, retried three times, exceeded its token budget, and hallucinated a fallback.” The first version is unfixable. The second tells you exactly where to look. LLM-Tracekit is a repository built on OpenTelemetry that ships pre-built instrumentation for the major agent frameworks and and emits traces that conform to the OpenTelemetry GenAI semantic conventions.
.png")
Layer 4: Quality
The fourth layer is quality. The evidence the earlier layers produce becomes the input to evaluators that score for issues such as hallucinations, toxicity, topic drift, and policy violations.
.png")
However, eval monitoring is post-hoc by design. It catches patterns over time but doesn’t stop a single bad request. Guardrails do. They sit in the critical path and screen inputs and outputs in real time for the things that can’t ship through, like personally identifiable information, prompt injection, and unsafe outputs.

Coralogix ships AI guardrails alongside the evaluators in the AI Center, so both layers are addressed in one place.
.png")
With these four layers in place, you have something to show when the question shifts from “is the AI working?” to “why did it do that, and what did it cost us?”
Build the system before you need to defend it
The trust gap isn’t going to close at the model layer. The properties that make agentic AI different from request-response systems – the unpredictable execution paths, the decision-driven resource usage and the obscured reasoning, are properties of how the technology works. They aren’t items on a backlog that get crossed off in a future release. The trust has to come from outside the model, the way it comes from outside the plane.
The instrumentation that produces that trust already exists. The OpenTelemetry semantic conventions for generative AI make it easy to integrate with your current OpenTelemetry set up, and the Coralogix AI Center pulls coding agent and application telemetry in without code changes. None of this is hypothetical, and none of it requires throwing out the observability stack you already have in place.
The teams that build the system around their AI now will have something to show users when trust is questioned, something to show leadership when the bill comes due, and something for developers to debug against when a regression hits production. The teams that wait will be reverse-engineering decisions from incomplete logs at the moment the stakes are highest.
Un-observable AI is un-trustworthy AI. The work is to make the behavior visible enough that your team can decide, run by run, when to trust it.


