 Introducing the Coralogix CLI: Headless Observability for Every Agent.
Introducing the Coralogix CLI: Headless Observability for Every Agent. 
The Security Risks of Using LLMs in Enterprise Applications


Large language models (LLMs) are rapidly reshaping enterprise systems across industries, enhancing efficiency in everything from customer service to content generation. However, the capabilities that make LLMs valuable also lead to significant risks as they introduce unique and evolving security challenges.
Integrating LLMs into enterprise environments means these models process large volumes of data from diverse sources, often containing sensitive information. This creates an expansive attack surface susceptible to new and emerging threats. Organizations must be cautious to avoid unintended vulnerabilities as these AI systems interact unpredictably with users and other enterprise tools.
A recent University of North Carolina study revealed that even after implementing data removal procedures, LLMs can still unintentionally expose sensitive information, potentially leading to data leakage and legal complications.
The security landscape for LLMs is complex due to several critical vulnerabilities, such as data poisoning, where attackers manipulate training data to compromise model reliability and prompt injection attacks that can generate harmful or unintended outputs.
Understanding and mitigating these risks is crucial for enterprises wishing to leverage LLMs’ full potential without compromising data security or regulatory compliance.
TL;DR
- LLMs in enterprise applications face significant security risks, including prompt injection, data poisoning, and model theft.
- Supply chain vulnerabilities and insecure output handling threaten enterprise LLM deployments.
- Role-based access control and regular security audits are essential for protecting LLM systems.
- Organizations must implement comprehensive input validation and monitoring systems.
Key Security Risks in LLM-based Enterprise Applications
Integrating LLMs in enterprise environments introduces significant security vulnerabilities that require careful consideration and robust protective measures.
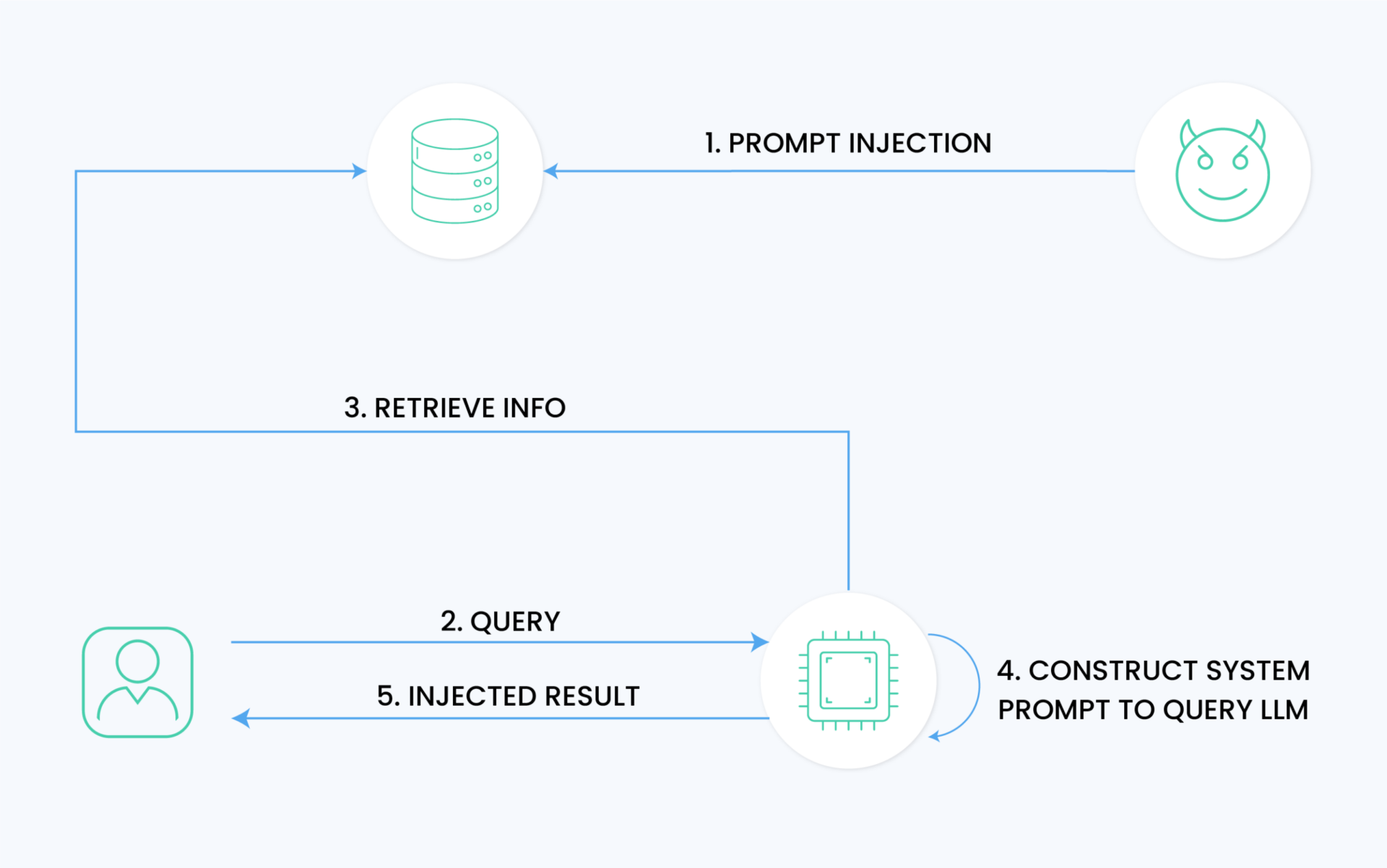
Prompt Injection Attacks
Prompt injection attacks are specialized attacks when malicious actors design specific inputs to manipulate LLM behavior. These attacks can bypass system prompts through “jailbreaking” techniques or embed harmful prompts in external sources.
Attackers can exploit LLMs to execute unauthorized actions, potentially accessing sensitive data or triggering malicious API operations. The impact extends beyond data breaches, as compromised LLMs can become unwitting proxies for attacking other systems or users within the enterprise network.
Training Data Poisoning
Training data poisoning attacks compromise LLM integrity by contaminating the training dataset with adversarial examples. Research demonstrates that larger models show significantly increased susceptibility to poisoning, even with minimal contamination rates.
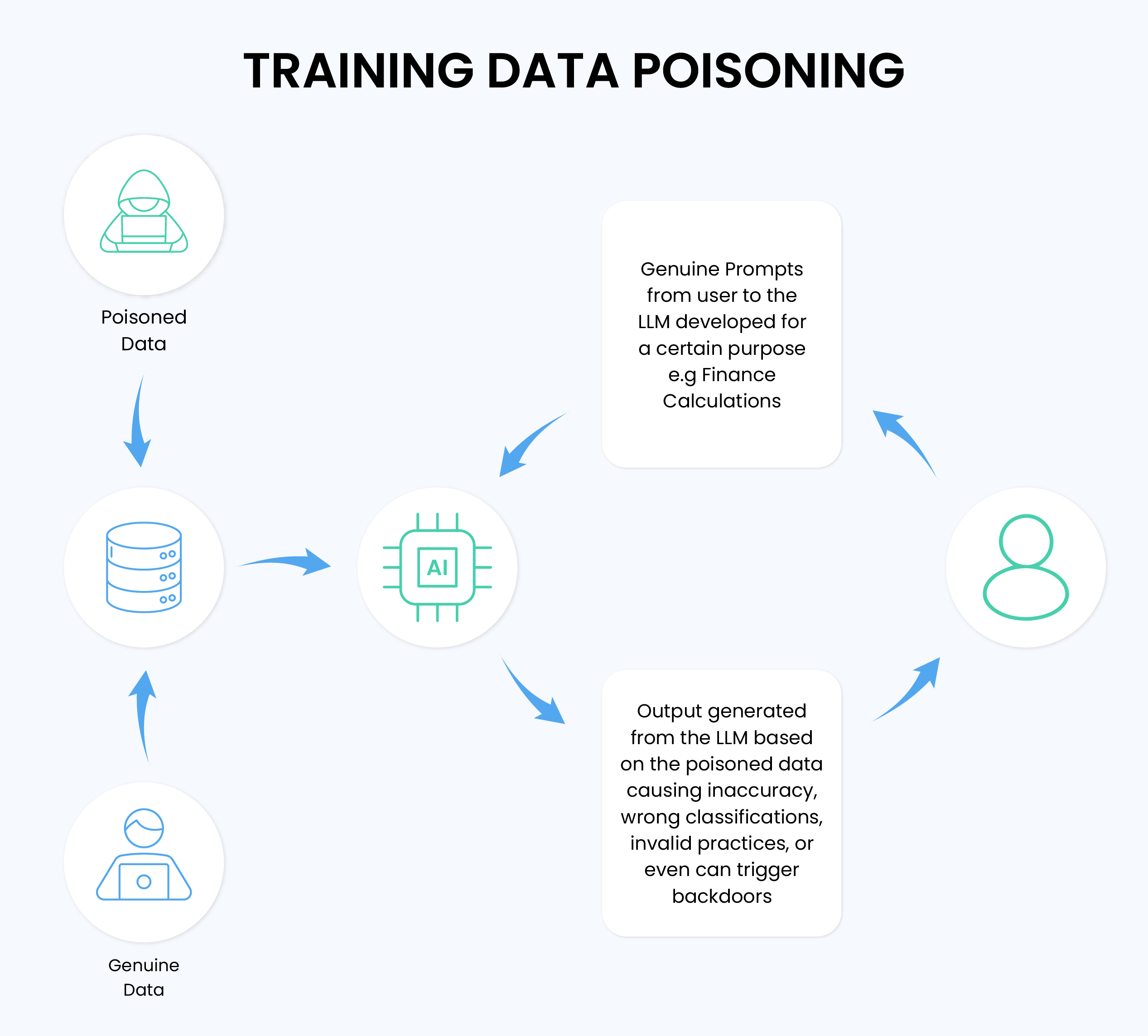
Adversaries execute these attacks by injecting malicious data into familiar web scraping sources and public datasets, leading to model behavioral changes that can persist through fine-tuning. The risk intensifies in domain-specific applications where data verification is complex, such as healthcare diagnostics or financial analysis systems.
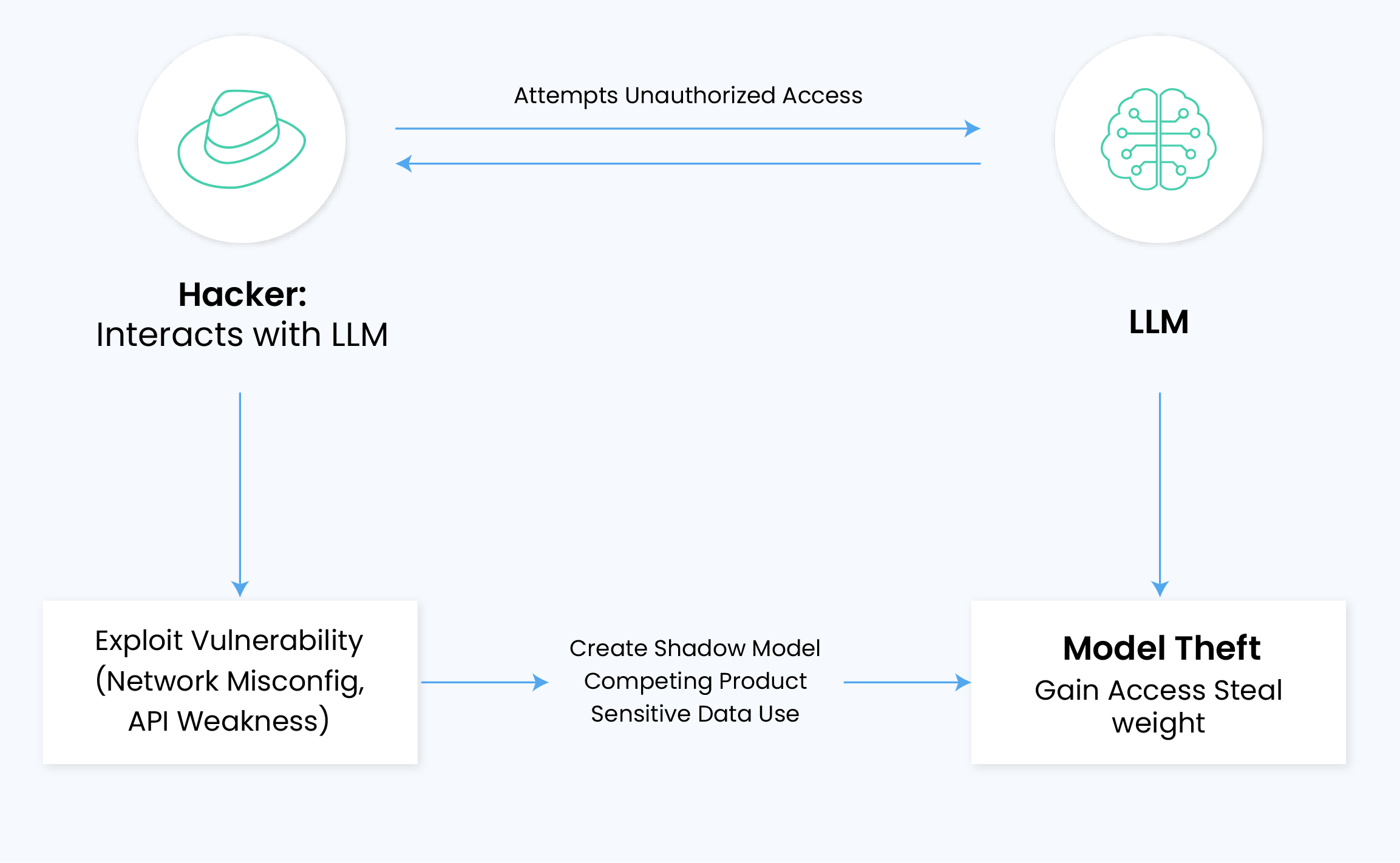
Model Theft
Model theft encompasses both direct exfiltration of model architectures and indirect extraction through API probing. Attackers target proprietary model components, including weight matrices, hyperparameters, and architecture configurations. The consequences extend beyond immediate IP loss – extracted models can reveal training data through membership inference attacks and enable adversaries to develop targeted exploits.
Organizations developing custom LLMs can face significant damages, as model compromise can nullify significant R&D investments and expose competitive advantages in market-specific applications.
Insecure Output Handling
Insecure output handling occurs when LLM-generated content lacks proper validation and sanitization before downstream use. This vulnerability can manifest through multiple attack vectors, including cross-site scripting (XSS), cross-site request forgery (CSRF), and privilege escalation.
Organizations directly integrate LLM outputs into applications without verification risk, exposing backend systems to remote code execution or providing users with unintended administrative access. A zero-trust approach to output validation becomes essential, treating every LLM response as potentially harmful until explicitly verified.
Supply Chain Vulnerabilities
Supply chain vulnerabilities in LLM systems extend beyond traditional software dependencies to include risks in pre-trained models and training data sources. These vulnerabilities can compromise model integrity and lead to systemic security failures. Common attack vectors include poisoned crowd-sourced data, vulnerable pre-trained models used for fine-tuning, and outdated components that lack security updates.
The complexity increases with LLM plugin extensions, which introduce additional attack surfaces through third-party integrations. Each component in the LLM supply chain represents a potential entry point for malicious actors, requiring comprehensive security measures across the entire deployment pipeline.

Integration Challenges and Vulnerabilities with LLMs in Enterprise Systems
System Integration Risks
LLM systems present complex integration challenges that extend beyond the models themselves. When LLMs interact with enterprise components, each connection point creates potential security vulnerabilities.
A critical risk occurs when LLM outputs are directly integrated into downstream applications without proper validation, potentially leading to code execution vulnerabilities or system compromises. The non-deterministic nature of LLMs means that output validation becomes essential, requiring robust post-processing mechanisms and security controls.
Data Privacy Concerns
The inability of LLMs to selectively remove or “unlearn” individual data points creates significant compliance risks, especially for regulations like GDPR that require data deletion capabilities.
Traditional data governance methods must adapt, as LLMs lack fine-grained access controls, making restricting information access based on user roles or permissions difficult. The challenge extends to data residency requirements, as LLMs consolidate information into a single model, making regional data isolation impossible.
Access Control and Authorization
Enterprise LLM deployments require robust policy-based access controls (PBAC) to manage system interactions effectively. These controls enable organizations to segment access to models and data based on specific roles, teams, or business needs. Implementing identity and access management (IAM) systems becomes crucial for centralizing user authentication and authorization, mainly when dealing with sensitive data and intellectual property.
For instance, customer service agents accessing LLM systems might unintentionally expose sensitive customer information across unauthorized boundaries.
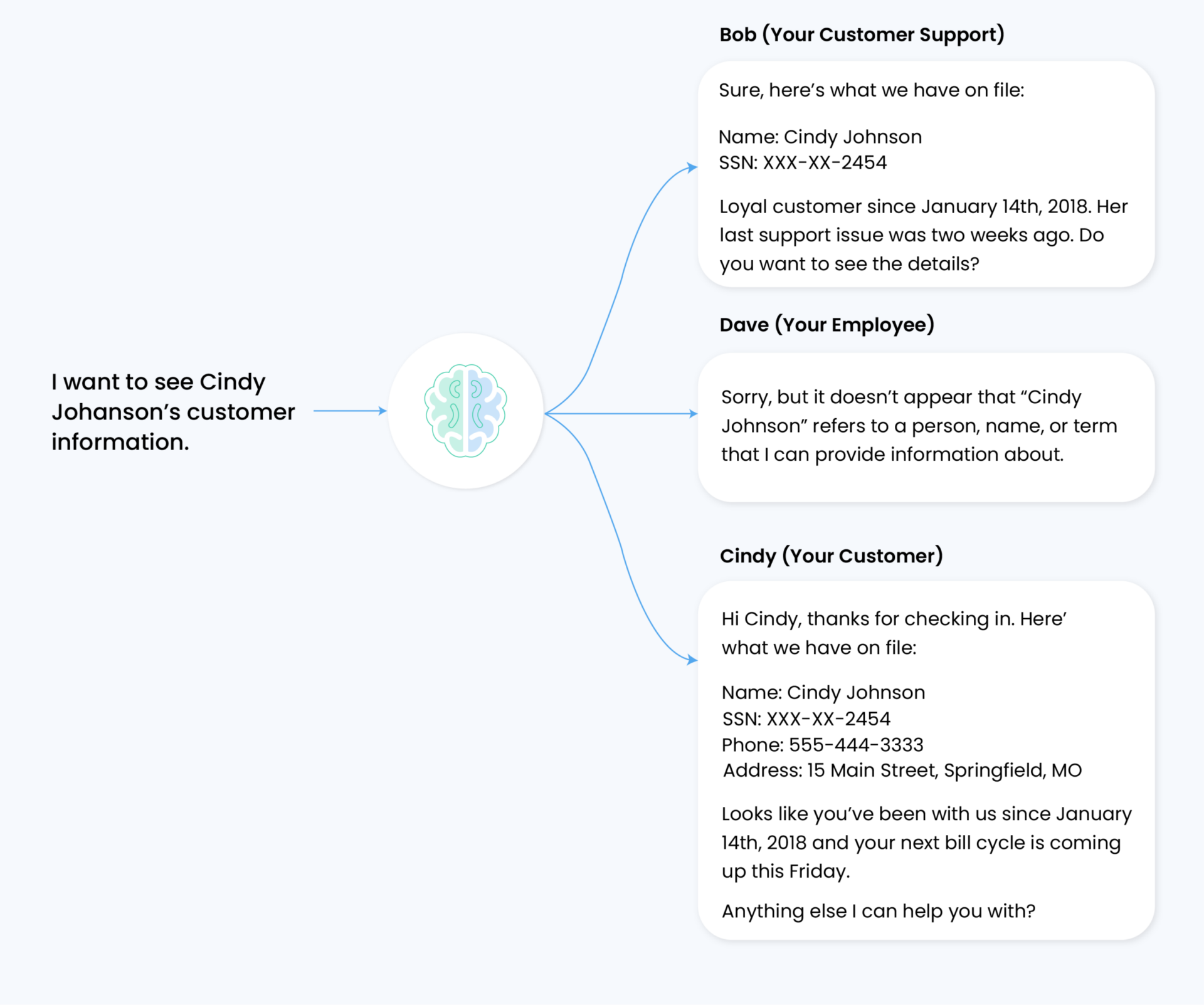
Organizations utilizing internal RAG (Retrieval-Augmented Generation) and fine-tuned models benefit from granular access control systems that only restrict model engagement to authorized personnel. This approach significantly reduces data theft risks and strengthens security layers across the enterprise infrastructure. The system also enables customized model actions based on specific use cases and user groups, ensuring appropriate resource allocation and usage controls.
Overreliance on LLMs
LLM outputs require careful validation due to their inherently unpredictable nature. Organizations must treat all LLM-generated content as potentially untrustworthy until verified, particularly in high-stakes environments. This requires strict validation techniques and output filtering mechanisms to maintain system integrity.
The risk extends to plugin integrations, where uncontrolled API calls can expand the attack surface. To mitigate these risks, enterprises should establish comprehensive logging systems for both inputs and outputs, enabling the detection of suspicious activities and systematic verification of LLM-generated content. This approach helps balance the benefits of LLM automation with necessary human oversight, ensuring that critical decisions maintain appropriate levels of human verification and control.
Implementing Robust Security Measures in Enterprise Applications
As enterprises increasingly integrate LLMs into their applications, implementing robust security measures becomes crucial for protecting sensitive data and preventing unauthorized access. Here’s a comprehensive look at crucial security measures for enterprise LLM deployments.
Input Validation and Sanitization
Input validation must occur as early as possible in the data flow, particularly when receiving data from external sources. This involves two key processes:
- Validation checks whether inputs meet specific criteria and constraints
- Sanitization removes potentially harmful characters or elements.
Organizations should validate and sanitize inputs on both client and server sides, applying context-specific methods based on how the input will be used.
Role-Based Access Control
Implementing Role-Based Access Control (RBAC) in Large Language Model (LLM) applications enhances security by assigning permissions based on user roles within an organization. This approach ensures users access only the features and data necessary for their job functions, aligning with the principle of least privilege.
Key Steps for Implementing RBAC in LLM Applications:
- Define clear roles with specific permission sets
- Implement hierarchical access structures
- Enforce separation of duties for critical operations
- Regularly audit and review access patterns
Adversarial Training
Adversarial training enhances both model robustness and generalization capabilities in LLM deployments. This approach involves generating adversarial samples during training and using them to incrementally retrain the model, which can be done at pre-training or fine-tuning stages. The process includes perturbing input data along the direction of loss gradients and incorporating these perturbed samples into the training dataset.
Monitoring and Logging
Effective monitoring of LLM systems requires real-time observation combined with comprehensive logging of all interactions. Coralogix provides end-to-end security observability and monitoring with real-time alerts for potential security issues and unified visibility of all LLM operations.
The monitoring framework includes advanced root cause analysis capabilities to diagnose and resolve complex problems while maintaining detailed audit trails for immediate incident response and forensic analysis.
Conclusion
AI security’s evolving landscape presents challenges and opportunities as enterprises increasingly adopt LLMs. While LLMs offer transformative capabilities, their integration demands a proactive approach to addressing vulnerabilities like prompt injection, data poisoning, and insecure outputs.
Companies must commit to stringent validation protocols, robust role-based access, and comprehensive security audits to safeguard sensitive information and protect enterprise systems from evolving threats.
Coralogix’s observability solution for real-time monitoring, secure input handling, and adversarial training, Coralogix confidently help enterprises navigate the complexities of LLM security. By partnering with leaders in AI security, organizations can harness the full potential of LLMs while maintaining robust defense mechanisms, ensuring that the benefits of these technologies are realized without compromising safety or trust.
FAQ
What is prompt injection, and why is it dangerous for AI agents?
How can Coralogix help secure enterprise LLM deployments?
What makes output handling a critical security concern?
How does Coralogix protect against sensitive data and PII leakage?
References
- https://www.metomic.io/resource-centre/what-are-the-top-security-risks-of-using-large-language-models-llms
- https://www.wiz.io/academy/llm-security
- https://www.csoonline.com/article/575497/owasp-lists-10-most-critical-large-language-model-vulnerabilities.html
- https://www.wattlecorp.com/llm-security/
- https://perception-point.io/guides/ai-security/why-llm-security-matters-top-10-threats-and-best-practices/
- https://www.stibosystems.com/blog/risks-of-using-llms-in-your-business
- https://granica.ai/blog/llm-security-risks-grc
- https://arxiv.org/html/2408.02946v1
- https://learn.snyk.io/lesson/training-data-poisoning/
- https://www.exabeam.com/explainers/ai-cyber-security/llm-security-top-10-risks-and-7-security-best-practices/
- https://www.crn.com/news/ai/2024/the-ai-danger-zone-data-poisoning-targets-llms
- https://genai.owasp.org/llmrisk/llm05-supply-chain-vulnerabilities/
- https://stg-Coralogix-staging.kinsta.cloud/learn/llm-insecure-output-handling/
- https://www.skyflow.com/post/private-llms-data-protection-potential-and-limitations
- https://www.redhat.com/en/blog/llm-and-llm-system-risks-and-safeguards
- https://calypsoai.com/article/the-importance-of-permissioning-large-language-models-in-enterprise-deployment/
- https://www.lasso.security/use-cases/secure-llm-applications-for-enterprise
- https://www.spiceworks.com/it-security/identity-access-management/guest-article/genai-rbac-security-strategy/
- https://stg-Coralogix-staging.kinsta.cloud/ai-guardrails/session-explorer/


