
Zillow Talk: How Companies Leverage AI & How to Keep It In Check


Over the last week we saw one of the biggest AI failures in recent years. American online real estate marketplace company, Zillow’s stock fell by over 25% after a nearly $330 million loss in Q3 and an exit from their home flipping business. Many fingers are pointing to their machine learningmodels, which were used to forecast housing pricing.
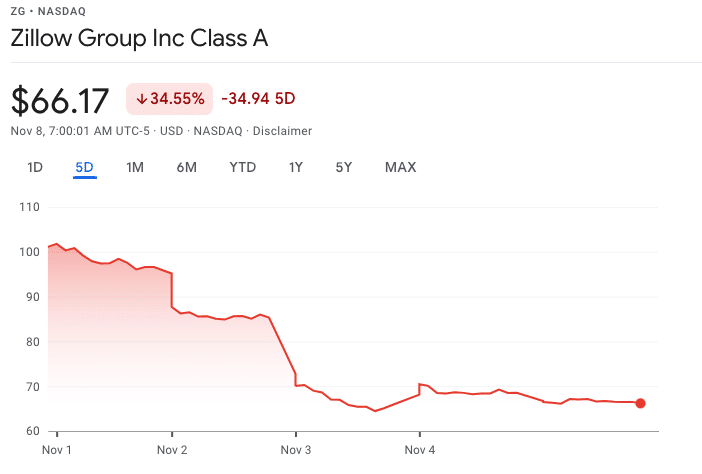
There’s a lot of speculation about how this happened. It’s impossible to know exactly what happened at this point. Nevertheless, as more and more businesses invest heavily and begin to rely on AI and machine learningmodels to improve their business results and processes, the question we need to ask is not how to become less reliant on ML models, but how can we ensure our ML models are performing as intended. Let’s start by digging a little deeper into what happened at Zillow.
Zillow’s Use of Machine-Learning Models
I want to preface this by saying Zillow was more advanced in leveraging AI than most companies. They utilized their data science and ML teams to develop predictive models to estimate home value, which had a huge impact on their business activity. They started by using the models to help their marketplace users know if they were getting a good deal. Although from the beginning some real estate agents questioned the estimation quality, Zillow stood by their machine learning algorithm. At the time, they were probably right to do so because the impact of a small prediction error was insignificant at a time when market value was continuously rising for five years.
This may have led Zillow to decide to apply their ML models to enable house flipping (the process of buying, rehabbing, and selling properties for profit) at scale. The intention was to predict the house value 6 month into the future, and based on their predictions decide whether or not to buy a property.
At first, Zillow was able to increase revenue by selling homes at higher prices relative to their original purchase price, but their margin of error was very small.
According to Zillow’s CEO Rich Barton, Covid-19 had a huge impact on the housing market, first freezing the industry and then leading to a steep rise that would’ve been impossible to predict for their models – leading to the significant loss we’ve seen recently.
How could they have foreseen and avoided these events?
Lessons Learned & How to Ensure Your ML Models Are Performing As Intended
The most important thing to learn when using machine learning models to drive your business is that the world is constantly changing. Even if you have a huge amount of data to use for building your ML models, and your model acts perfectly in training, this doesn’t mean your model will act the same in production.
Deploying a model to production is just the beginning. Ongoing monitoring of model behavior and its environment is imperative. Here are a few things to look out for:
-
The number of invocations of your model
-
-
- This helps you quickly notice changes in your model’s business environment (for example, are people buying houses at the same rate as they usually do?)
-
-
Features distributions
-
-
- It’s important to compare both features distribution the model was trained on, and the features distribution change over time (especially in time series models).
- This may not always be noticed in the predictions themselves, but in many cases it can be an indication of what’s to come
-
-
And the obvious, the predictions
-
- This can have a huge impact on your business – after all, this is the reason your model exists
If you notice a change in one of these things, you should try to understand the root cause, and see if you need to retrain your model (or even make changes in the business in extreme cases.)
Despite being in the top 10% for machine learning maturity, Zillow made mistakes which most likely could’ve been avoided. If it happened to Zillow, it could happen to any company, especially when a business is running at a fast pace, has invested heavily in their AI and wants to see a quick return on that investment from their data science and ML engineering teams.
Adding Monitoring to Your ML Models in Production
Always remember that once in production, it is not uncommon for deployed machine learning models to be impacted by the constantly changing environment and data, which often results in performance degradation. If you take part in the process of model development, it’s essential to continue evaluating and monitoring that model in production to detect drift, bias, and integrity issues early, and intervene as soon as possible, to ensure your model is working as intended. It’s easy to overlook a number of sticky problems that could quickly become million-dollar issues like Zillow’s if you’re not effectively monitoring your ML models.
The good news is that the majority of companies utilizing AI in their business are starting to understand the importance of monitoring. Nevertheless, that doesn’t mean they’ve adopted a comprehensive monitoring solution or dedicated the resources to build their own ML monitoring solution to keep their models from underperforming.


