

Building a Culture of Observability Through Ownership


The Real Cost of Ignoring Observability
There’s a problem in engineering culture that we don’t talk about enough: observability is an afterthought. It’s treated as tooling, not thinking. As a checkbox, not a habit. And that mindset gap creates real consequences: longer outages, frustrated teams and massive business costs. Atlassian’s Incident Management for High-Velocity Teams overview cites a 2014 study by Gartner, that the average cost of IT downtime is $5,600 per minute. This is an average and much higher for teams in finance and e-commerce. And yet, teams still rely on guess work during incidents.
I am writing this to tech leads, engineering managers and senior developers who want to change that – to embed observability into how their teams think, not just how they work. It’s about building a culture where developers take ownership of reliability and adopt the tools that support it – not because they’re told to, but because they see the value in it themselves.
Culture Beats Clean Code
As a Tech Lead, I’ve learned that building a high-performing team isn’t just about clean code or faster delivery. It’s about creating a culture that’s focused, resilient and proactive. Teams that move with purpose, cut through noise and solve real problems. But change like that doesn’t come easily, especially in development teams where inertia runs deep.
Why? It means breaking habits, disrupting workflows and inviting scrutiny. Most developers have lived through failed “shiny new thing” rollouts – tools that added friction instead of value and initiatives that died after one quarter.
Reset with Play, Not Pressure
I have been there, too. In one of my previous roles, I took over a team where DevOps was in disarray. Every customer ran on their own fragile codebase. Releases were chaotic. Nobody wanted to touch production. Even small changes triggered anxiety. Morale was low and turnover was high. The team needed a reset – fast. But rather than just push a new process top-down, I made the decision to make the experience fun. I turned learning into a game. Playful competitions, visible progress, small wins celebrated loudly — this changed the energy in the whole team. Slowly, the team started to own the transformation themselves – the culture shifted. Ownership spread. What began as a difficult mandate became something they championed. And that lesson stuck with me. So when it comes to adopting observability, I’d approach it the same way.
Why Observability Pays Off (Literally)
Why should a software development team care about observability at all? The simple answer is because there is too much guesswork in solving production problems and that guesswork directly impacts the bottom line – including their pay packets. Developers are often so deep in the code that they forget the bigger picture: customers pay the bills. When customers experience pain, it becomes business pain. And when the business hurts, so does the team.
A critical metric here is Mean Time To Resolve – the time it takes to detect, diagnose, fix and most importantly but often overlooked – prevent the production issues from reoccurring. MTTR matters because it shifts the mindset from firefighting to fireproofing. It focuses the team to think beyond immediate fixes and sets the focus on long-term resilience. Fast recovery is great, but preventing the problem from happening again? That’s where real value lies. And observability is key to making that happen.
The Incident Guessing Game is Broken
Most development teams operate in fast-moving environments. New features, high pressure deployments and growing user traffic — all signs of a healthy, scaling business. But more activity naturally increases the risk of incidents – which are ever more costly.
The usual incident response is painful to watch: first, someone combs through logs (if they exist), hoping for a smoking gun. Spoiler: they won’t find it. Logs alone rarely tell the full story. Then comes the scramble — pinging teammates for context, dragging multiple people into a war room to piece together fragmented clues. Hours pass. Context is lost. Productivity tanks. Every minute spent here costs the business. Every fire drill means developers aren’t building features, they’re firefighting. And when development stalls, revenue stalls. It’s a direct line from inefficiency to impact on business health and team compensation. This is not sustainable.
From Top-Down Mandates to Personal Wins
Developers are naturally skeptical of new processes – especially if they feel like extra overhead. If the rollout feels like another top-down imposition, they’ll resist it (either openly or quietly by not engaging). To succeed, the team needs to see the value for themselves. That’s why I focus on creating personal connections to the change. I’ll ask the team: “Remember that nightmare production issue that took days to resolve? How would it feel if you had caught and fixed it before it ever hit production?” That simple question reframes observability from a corporate mandate to a personal win. It makes the benefit immediate and real. For adoption to stick, the goals need to be simple, clear and anchored in ownership.
Coralogix + OpenTelemetry = Momentum
Rolling out observability tools is easy enough. Getting real adoption? That is the hard part. This isn’t just about rolling out a tool — it’s about changing how the team thinks and works. The first imperative is adopting an observability mindset, where developers move from reactive problem-solving to proactive system health.
The second is getting hands-on with the tools themselves – and that means more than just wiring up a few dashboards. It’s about embedding observability into the development workflow with purpose-built tools like OpenTelemetry for instrumentation and Coralogix for real-time visualization, analysis and action.
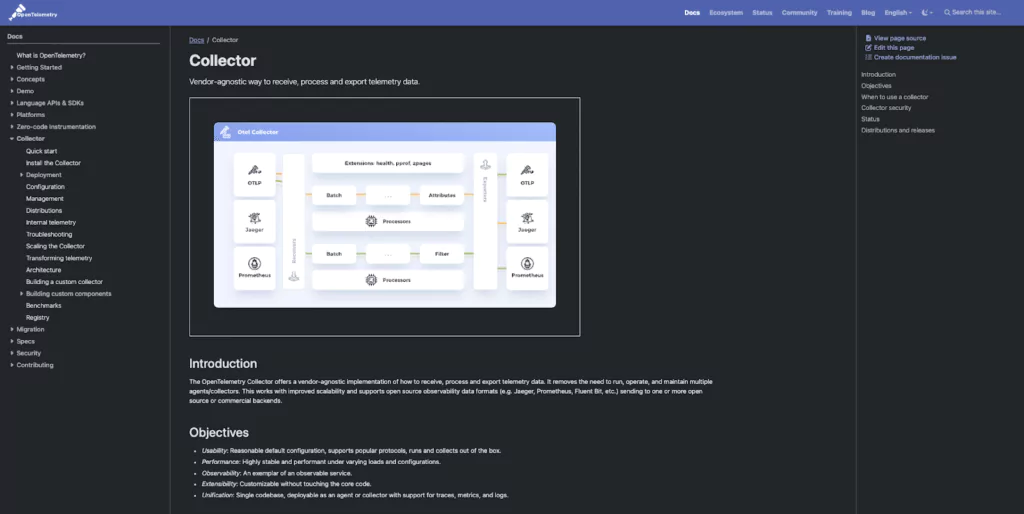
Coralogix addresses the root problem in many engineering cultures as I mentioned above: observability is treated as an afterthought. Observability with Coralogix helps teams move from reactive guesswork to proactive insight – fast. With prebuilt OpenTelementry integrations, guided setup flows and a 24/7 Customer Success team to help configure pipelines, parse logs and surface key metrics.
Coralogix makes it easy to get up and running. Ready-made extensions accelerate time to value, while advanced features like dynamic data routing and the TCO Optimizer lets teams declare exactly how their data should be stored and processed. The goal isn’t just to add tooling – it’s to build a habit. Developers need to feel ownership over their telemetry: the data, the insights and the improvements that follow. That’s what drives real change. That’s how observability becomes muscle memory – not a checkbox.
Make it Fun. Make it Stick.
Excitement is the fuel for change. I would create that spark by making observability adoption collaborative and playful. I love Lunch-and-Learns and Mini-Hackathons. These formats reduce the pressure and encourage experimentation. One such challenge is having the team extend the OpenTelemetry Demo Application by adding a new service and instrumenting it to send traces to Coralogix. Then awarding prizes for the most creative trace or the most verbose log – because humor matters and goes a long way to make these things fun and learning fun. I’d create leaderboards, healthy competition is good. I’d rotate Coralogix champions to lead future sessions. This keeps the momentum alive and turns observability from a one-off project into an ongoing team habit – that they now own.
The benefits speak for themselves. Once observability starts to take root, the team begins to feel it. Debugging becomes faster and the wild guessing game stops. Developers stop chasing shadows in log files and start working with clarity and confidence. There is a real sense of pride that comes from owning not just the code – but its quality, performance and the impact in production. That ownership translates to stronger CVs too – adopting the industry-standard stack of OpenTelemetry and Coralogix isn’t just good practice, it’s a career boost. And as the team shifts from reacting to incidents to preventing them, morale improves too. Work feels less chaotic and more intentional. Best of all, there is tighter alignment with the business.
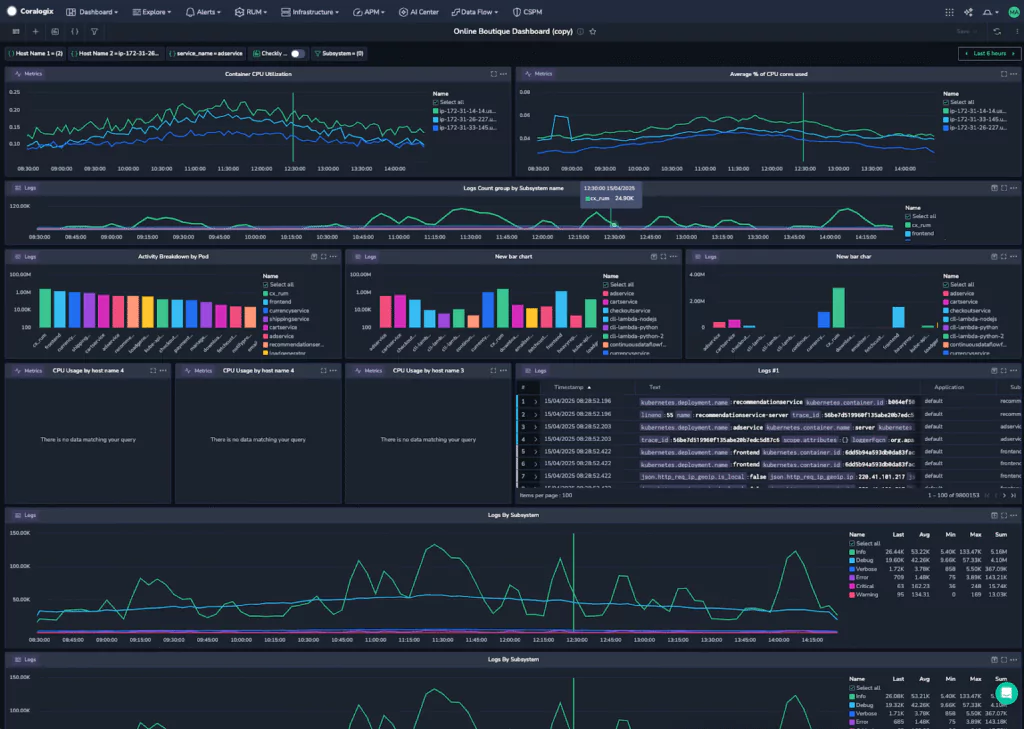
The team sees how reducing MTTR, improving reliability and delivering stable features directly support both their company’s success and their own growth. With Coralogix’s Investigations feature, developers can quickly correlate logs, metrics and traces in a single view – eliminating context switching and accelerating root cause analysis. This centralized approach streamlines incident response and fosters effective team collaboration. Additionally, Coralogix offers real-time alerting and anomaly detection powered by machine learning, enabling proactive identification of issues before they escalate. These capabilities make observability not just a process, but a measurable and impactful part of the development workflow.
Change is hard. I get that. But it’s also exciting — if you approach it the right way. The job of a Tech Lead isn’t to force change. It’s to make the path clear and energise the team to walk it themselves. When we focus on ownership, celebrate progress and keep things collaborative and fun, adoption follows naturally. Observability is no different. Start with mindset, support it with the right tools and build momentum with small, visible wins. Before you know it, observability becomes part of the team’s DNA — not because they were told to do it, but because they see the value and choose it for themselves. That’s the culture I build. No fluff, just focused, practical change that sticks.


