

RAGs are Not the Solution for AI Hallucinations


The use of large language models (LLMs) in various applications has raised concerns about the potential for hallucinations, where the models generate responses that sound factual but are made up. Techniques like AI evaluators, fine-tuning, prompt engineering, and retrieval-augmented generation (RAG) have been proposed as potential solutions.
However, there is a growing body of evidence suggesting that RAGs are not a definitive solution to the problem of hallucinations in LLMs. Despite marketing claims, RAGs may not effectively mitigate the risk of hallucinations, as they can still produce misleading or inaccurate outputs.
Let’s explore the limitations of RAGs concerning AI hallucinations, dissecting evidence and expert perspectives. It clarifies that RAGs fall short of being a universal solution for this critical issue.
Understanding Retrieval Augmented Generation
RAG is a method employed to augment the functionality of large language models (LLMs) by integrating external data. Its mechanism involves retrieving pertinent information from a database to generate responses for a given prompt.
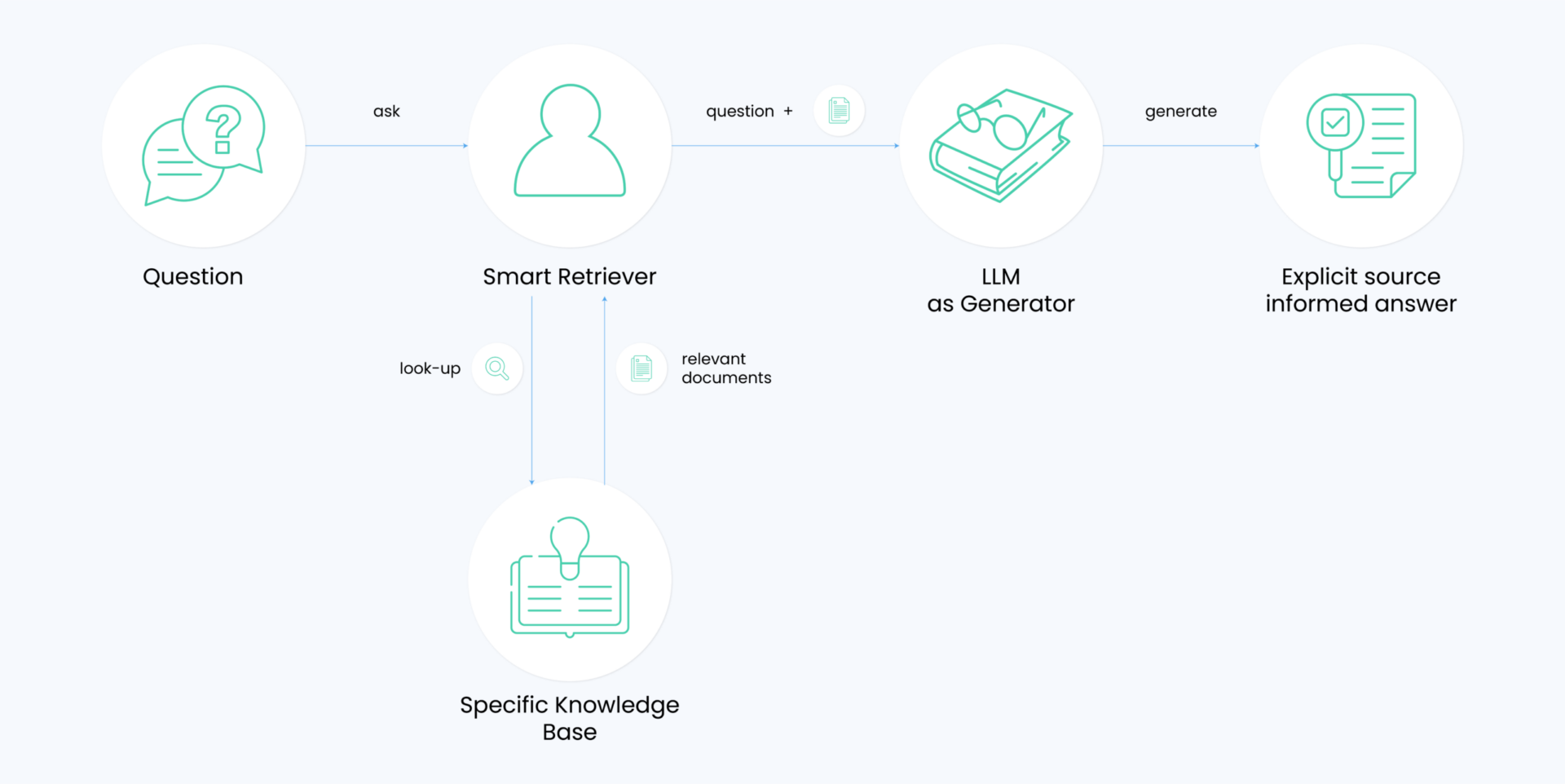
This retrieved data is then combined with the LLM’s internal knowledge, resulting in more precise and informative outputs. RAG proves beneficial in overcoming limitations inherent in LLMs, such as their inability to understand new information or adapt to dynamic contexts.
By supplementing LLMs with external data, RAG enhances their performance, rendering them more practical for real-world applications. However, RAGs do not offer an absolute solution for hallucinations in LLMs. While they contribute to output accuracy, they don’t guarantee the prevention of false or misleading information generation.
Hallucinations in LLMs
Hallucinations in LLMs are the generation of inaccurate, nonsensical, or detached textual content. These manifestations can be contradictory sentences, fabricated content, irrelevant information, or random outputs.
In critical sectors like healthcare, finance, and public policy, the associated risks of hallucinations are profound, potentially resulting in misguided decisions with severe implications. The ramifications of LLM hallucinations extend to disseminating misinformation, exposing sensitive data, and establishing unrealistic expectations regarding LLM capabilities.
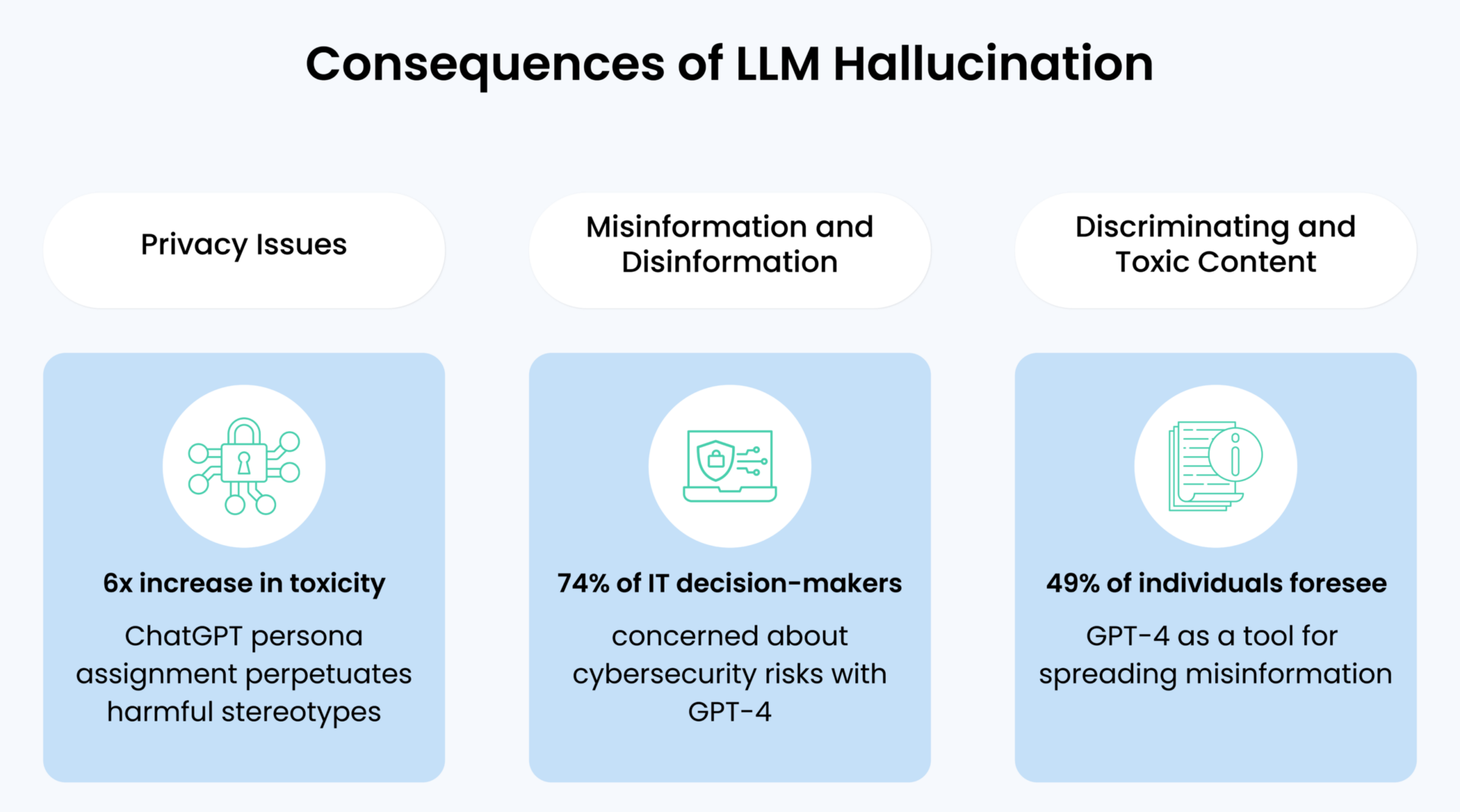
Ethical concerns arise as these hallucinations can impact individuals’ well-being and erode societal trust in AI systems. Recognizing and addressing the risks of LLM hallucinations are imperative to ensure the dependability and credibility of LLM-generated outputs.
Does RAG Mitigate LLM Hallucinations?
Numerous blogs such as the New Stack, Pinecone, and Info World advocate Retrieval-Augmented Generative models (RAGs) to mitigate hallucinations in large language models (LLMs). However, upon closer examination, these claims appear misleading.
Retrieval-augmented generative models (RAGs) are crafted to elevate the accuracy of generated text by integrating external information; they do not offer an infallible solution for preventing hallucinations in large language models (LLMs).
Studies indicate that while RAGs might enhance the coherence and informativeness of generated content, they fall short of completely eradicating the possibility of hallucinations.
Data sparsity is also a cause of hallucinations, driving home the importance of refreshing data to diminish biases. But despite the fact that they do this, RAGs may not always prevent the generation of false or misleading information.
Paradoxically, the incorporation of external data via RAGs may even contribute to the escalation of disseminating false information, aggravating the challenge of hallucinations within language models.
Mitigating RAG Hallucinations
Beyond Retrieval-Augmented Generation (RAGs), various alternative approaches exist for addressing hallucinations in large language models (LLMs). These methodologies target distinct facets of LLM performance and safety, providing diverse strategies to enhance their dependability across different applications.
1. Coralogix’s Evaluation Engine
Coralogix employs real-time evaluators to secure LLM responses and mitigate hallucinations. This proactive approach ensures the reliability and relevancy of retrieval in RAG systems. The evaluators work behind the scenes to alert you and update your custom dashboards to profanity, off-topic content, hallucinations and more to boost trust and ensure safe interactions that are aligned with your brand.
2. Prompt engineering
Prompt engineering focuses on enhancing LLM performance by thoughtfully crafting input prompts to encourage the generation of precise and relevant outputs. This approach may employ evaluators, such as instructions or constraints added to prompts, guiding LLMs toward producing more dependable results.
3. Fine-tuning
Fine-tuning involves training LLMs on specialized datasets to refine performance and mitigate the risk of hallucinations. This method facilitates LLM adaptation to specific tasks or domains, fostering increased accuracy and reliability in output generation.
The role of user feedback
Integrating user feedback, encompassing actions like upvotes and downvotes, proves instrumental in refining models, enhancing output accuracy, and diminishing the risk of hallucinations.
Distinguishing themselves from Retrieval-Augmented Generative models (RAGs), these approaches take a different route:
- RAGs concentrate on enriching LLMs with external data while fine-tuning, prompt engineering, and Coralogi’s evaluation engine prioritizez enhancing LLM performance and safety.
- RAGs will still induce hallucinations, leading to issues like context relevance and Q&A relevance failures. In contrast, fine-tuning, prompt engineering, and Coralogix’s evaluators aim to diminish hallucination likelihood by bolstering LLM performance and safety.
- RAGs demand extensive experimentation for accurate results, whereas fine-tuning, prompt engineering, and evaluators offer more focused and efficient solutions for addressing hallucinations.
Exploring these alternative strategies to avoid hallucination provides a better understanding of hallucination mitigation challenges in LLMs, fostering the discovery of more effective measures to uphold their reliability and trustworthiness across diverse applications.
The Main Takeaway
The takeaway here is that while RAG adds value by enriching language models with external knowledge, it’s not foolproof against hallucinations. The key solution in combating these hallucinations comes from implementing Coralogix’s evaluators. This approach ensures the information produced by language models is both accurate and relevant, directly addressing the challenge of hallucinations in RAGs.


