 The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 
DO NOT PUBLISH: Microsoft and CrowdStrike outage: Overview, timeline, cyber-attacks and more

Planes, trains, coffee shops and hospitals were amongst those impacted by the Microsoft issue on July 19th 2024, underscoring just how dependent the world is on a functional Microsoft environment. What was the cause of this issue, and what can users do to mitigate it?
A note before we begin
Incidents impact everyone. While it’s tempting to assign blame in situations like this, research has shown repeatedly that giving teams the time and breathing room to solve problems and perform detailed analysis reduces the odds of incidents recurring and drives better outcomes for everyone.
We wish Crowdstrike good luck and hope they are able to return to business as usual as soon as possible.
Overview of the incident
The root cause appears to be a code change that was pushed by Crowdstrike, a cybersecurity company based in Texas. While the details of the code change are, as of now, unclear, they appear to be very small, having been described by the CEO of Crowdstrike as a “content update”.
How did the issue manifest?
The issue chose to appear in classic style – the inimitable Blue Screen of Death (BSOD). Everything from ticker screens at airports, to checkouts in supermarkets, began displaying the familiar refrain.
The issue with the BSOD is that the computer is essentially unresponsive, making debugging difficult. It is also extremely familiar and striking, meaning companies had no opportunity to solve.

(Picture credit: Photograph: AAP/Reuters)
So was this caused by Microsoft?
Right now, it appears that Microsoft was not involved in this change. Instead, the issue occurs when Crowdstrike is running on a Windows operating system. Crowdstrike has over 29,000 users, so it’s no surprise that the impact here has been substantial.
And was this caused by a cyber-attack?
As of now, there is no evidence that this was caused by a cyber-security attack of any kind. It is a simple, classic case of a small change having a big impact.
Timeline of outage events
The event did not propagate slowly. As soon as the new release was made, incidents began to pile in. Data from Downdetector shows that the first issues spiked at around 05:30 GMT+1.
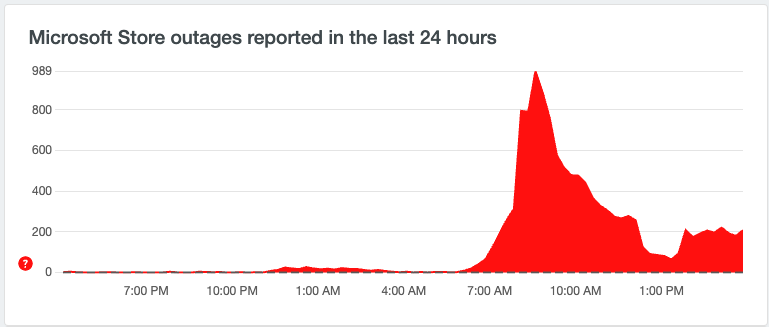
The next major milestone is the acknowledgement of the incident that was made by Crowdstrike CEO. This occurred at 15:45 GMT+1. This occurred around 10 hours after the initial incident reports. At the same time, the CEO also announced that a fix was being released.
What’s the fix for the Microsoft and CrowdStrike outage?
There have been some rather interesting diagnostic suggestions floating around. Everything from rebooting 15 times to deleting specific sys files. Ultimately, there is no singular path to solution right now. Crowdstrike have both pulled the impacted version and released a fix, but applying this update may be challenging on machines that are non-responsive.
The Azure status page has a lot of different suggestions for impacted users, and one of those should definitely cover your use case. If not, then it’s time to reach out to Crowdstrike directly.
Summary
This story serves to remind us of how fragile our fundamental services can be. Tiny changes to the codebase of small companies in Austin are now spreading to core institutions across the globe. This is why complete observability coverage is so important, to allow organizations to shift from a reactive posture to a proactive approach, and get ahead of incidents, no matter how far reaching they are.


