
Long-Term Storage: Coralogix vs. DataDog


Long-term storage, especially for logs, is essential to any modern observability provider. Each vendor has their own method for handling this problem. While there are numerous available solutions, let’s explore just one – Coralogix vs DataDog – and see the benefits and limitations.
Coralogix already outpaces Datadog in support, with 30-second response times, and cost, where customers have experienced 40-70% cost reductions.
Flex Logs
DataDog has released its feature, named Flex Logs, that enables users to store their logs in their own cloud storage, for example, S3. This allows them to archive logs in very low-cost storage, enabling them to retain more logs without hugely increasing costs. This is especially useful for teams with a large volume of logs and need to retain them for compliance issues.
So what’s missing?
There are some limitations. While we believe that querying archived logs is possible in DataDog, there is a compute cost associated with this feature.
How does Coralogix Remote Query Compare?
Coralogix Remote Query has an initial similarity with DataDog. They both utilize cloud storage in the user’s cloud account for cost-effective log storage. However, Flex Logs is ostensibly a log storage mechanism, but Coralogix Remote Query is a data analytics solution that easily competes with DataDog Flex Logs, providing a wealth of insights out of the box.
Remote Query Data Does Not Need Rehydration
While DataDog does appear to offer direct archive query, it also appears that it charges monthly compute costs, which is likely to increase the total spend for the customer to access their own data. This is the fundamental difference when comparing Coralogix vs DataDog. Coralogix enables Remote Query, which allows users to directly query their archived data, without re-indexing.
Additionally, Coralogix Remote Query supports both schema on read and schema on write, allowing users to define their schema upfront for maximum query precision and optimization, or discover their unstructured data as they go.
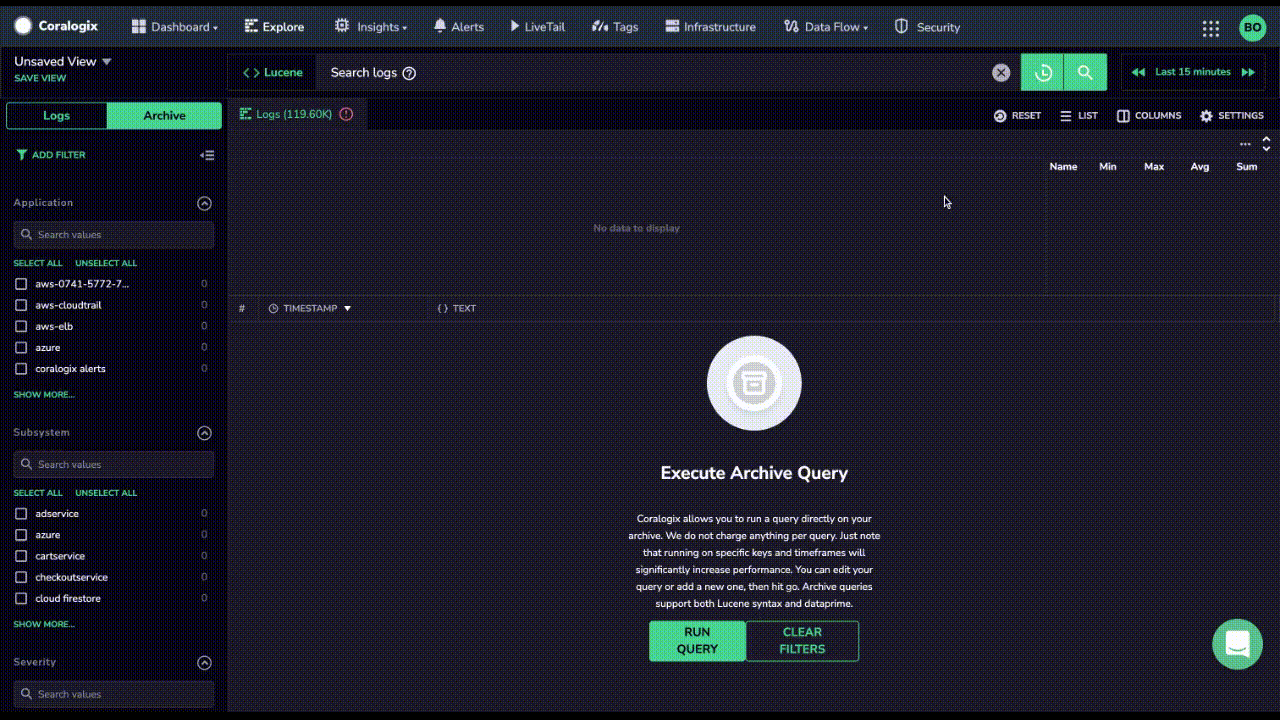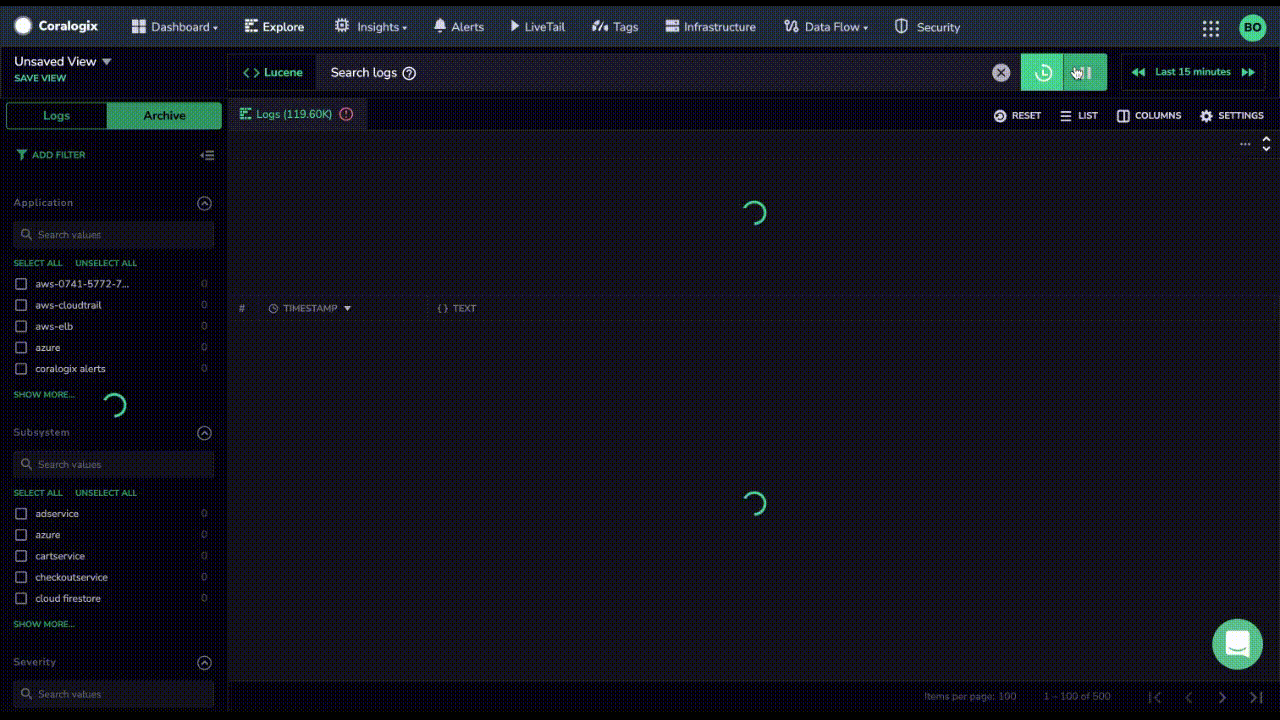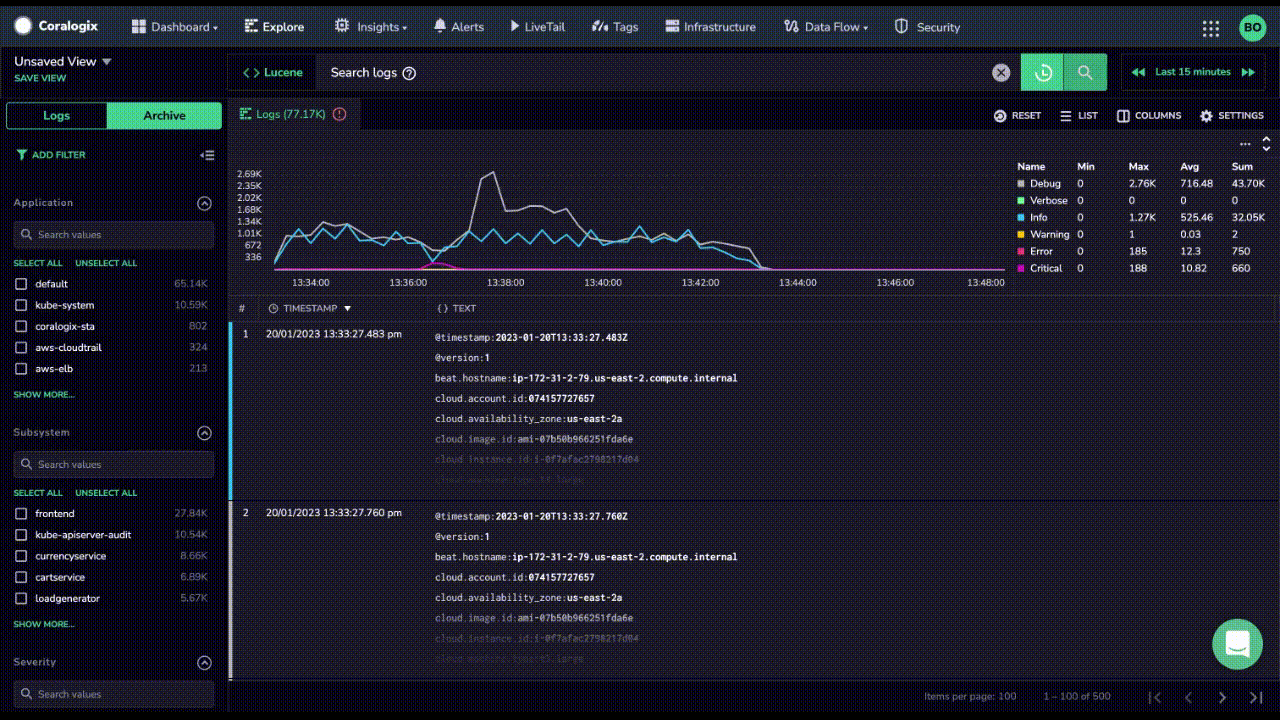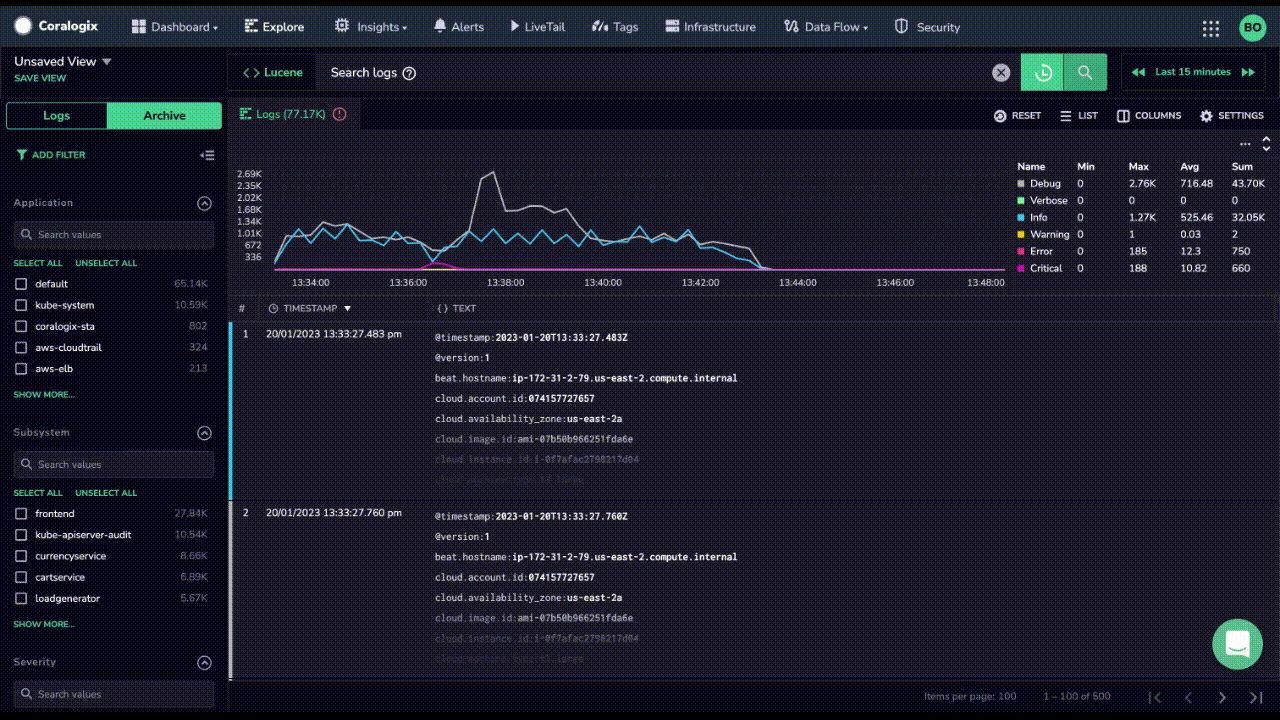
Why is Remote Query so Important For An Archive?
The need to reindex data raises some serious questions:
- How much data is necessary to reindex?
- How expensive will it be to hold all of this data in indexed storage?
- How long will it take to reindex this data, especially if there is a lot?
At Coralogix, we don’t force users down a data reindexing strategy. Coralogix does have a reindexing capability, which users can use as they wish. Still, with our unique architecture and the power of Remote Query, we have found that this is required far less than with other SaaS vendors.
Remote Query means users can easily discover their data at no extra cost. The only cost that the user incurs is their S3 hosting fees. Coralogix customers can issue as many queries as they like to their archive using Remote Query. This enables three key capabilities – discovering Coralogix Archive Data, holding less data in Frequent Search, and generating new insights via DataPrime.
Coralogix Archive Data is Discoverable
With Coralogix, data can be explored, new insights can be garnered, and new intelligence can be gathered without the need to reindex. This means that teams can freely (literally) explore their data without worrying about overages or charges for indexing a huge volume of data from the archive. DataDog, with its requirement to reindex, does not have this capability.
Users Can Hold Far Less Data in Frequent Search
Coralogix Remote Query is extremely fast, up to 5x faster than AWS Athena in certain scenarios. Many Coralogix users have realized that the significantly reduced cost and remarkable performance of Remote Query means they keep fewer indexed logs. This further reduces their costs while allowing them to explore more of their data than ever before.
Users Can Generate Entirely new Insights with DataPrime
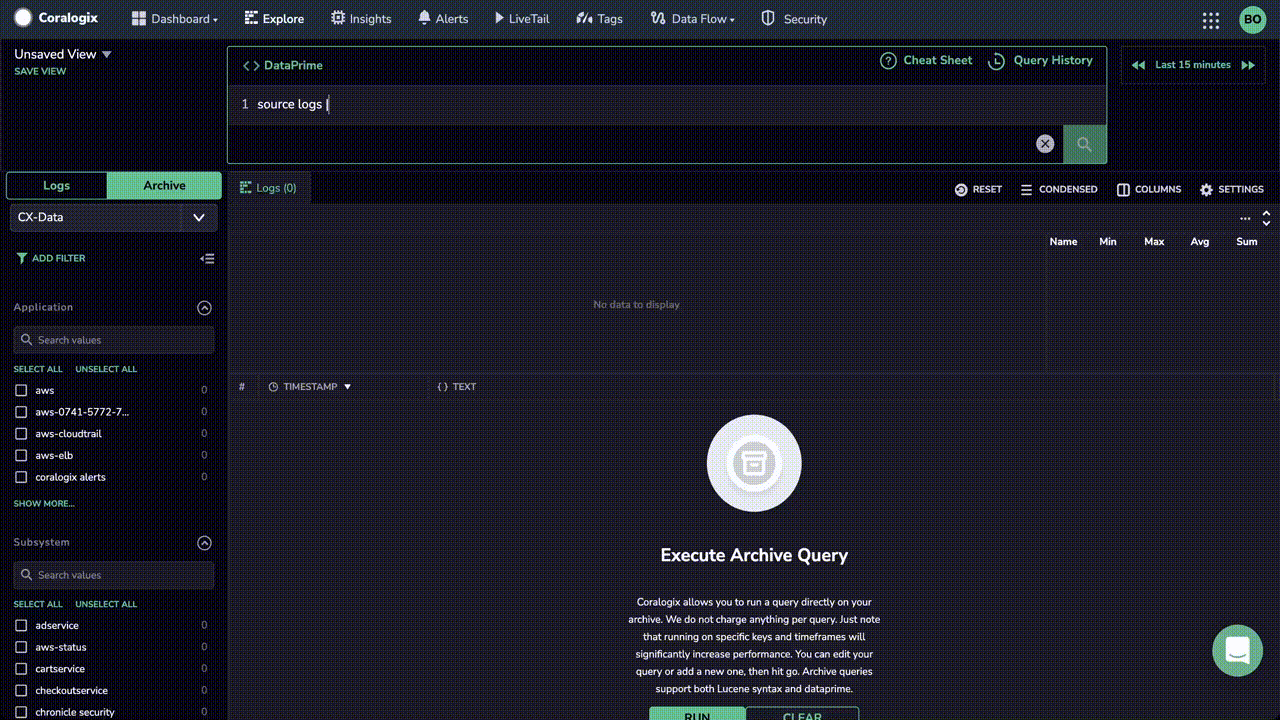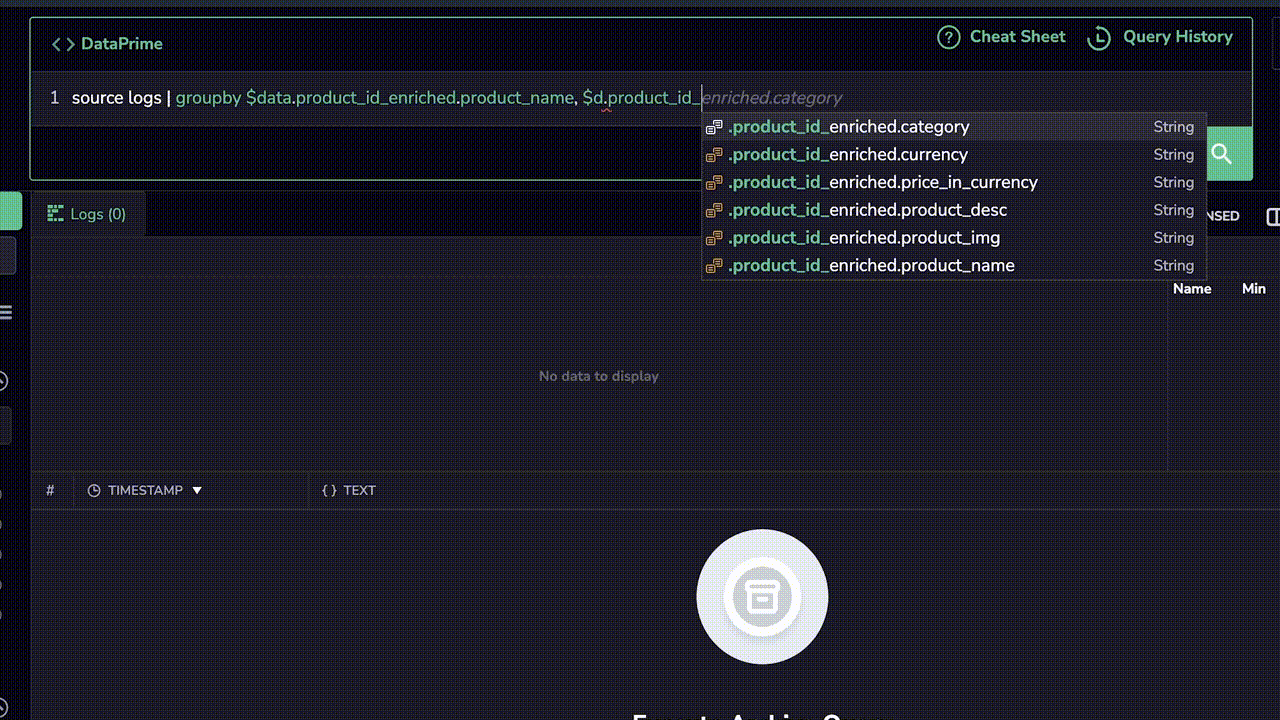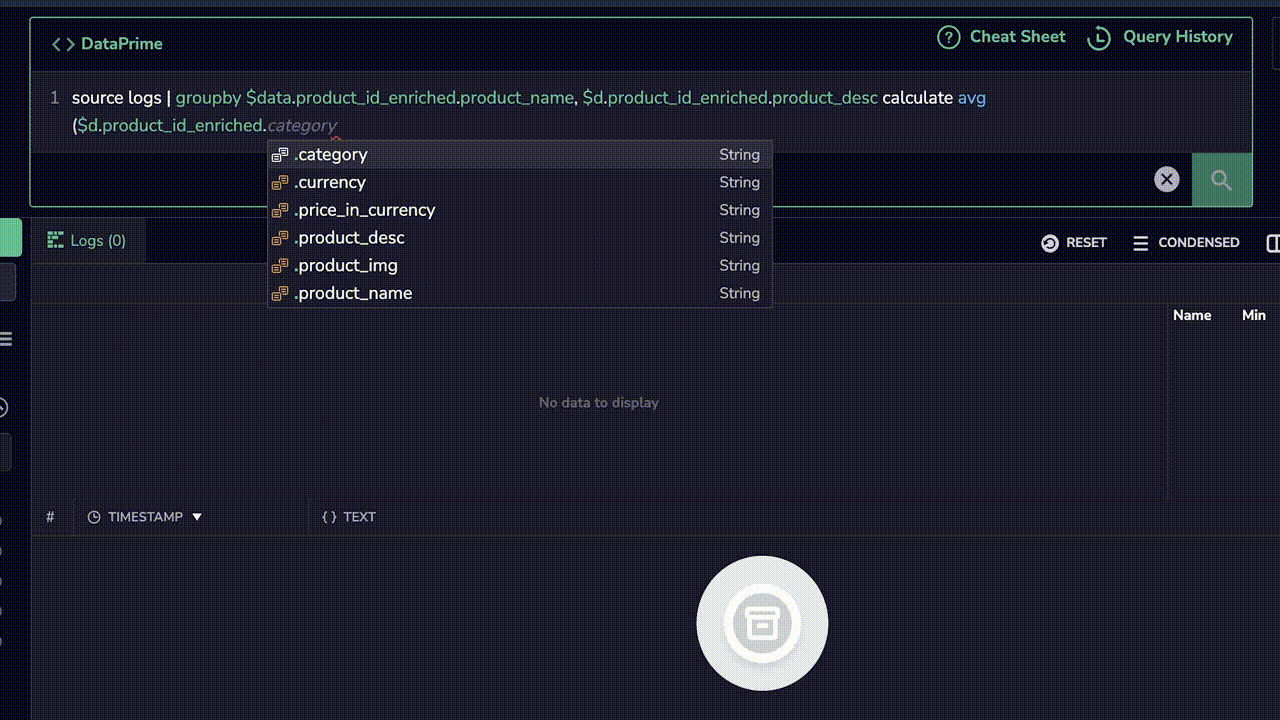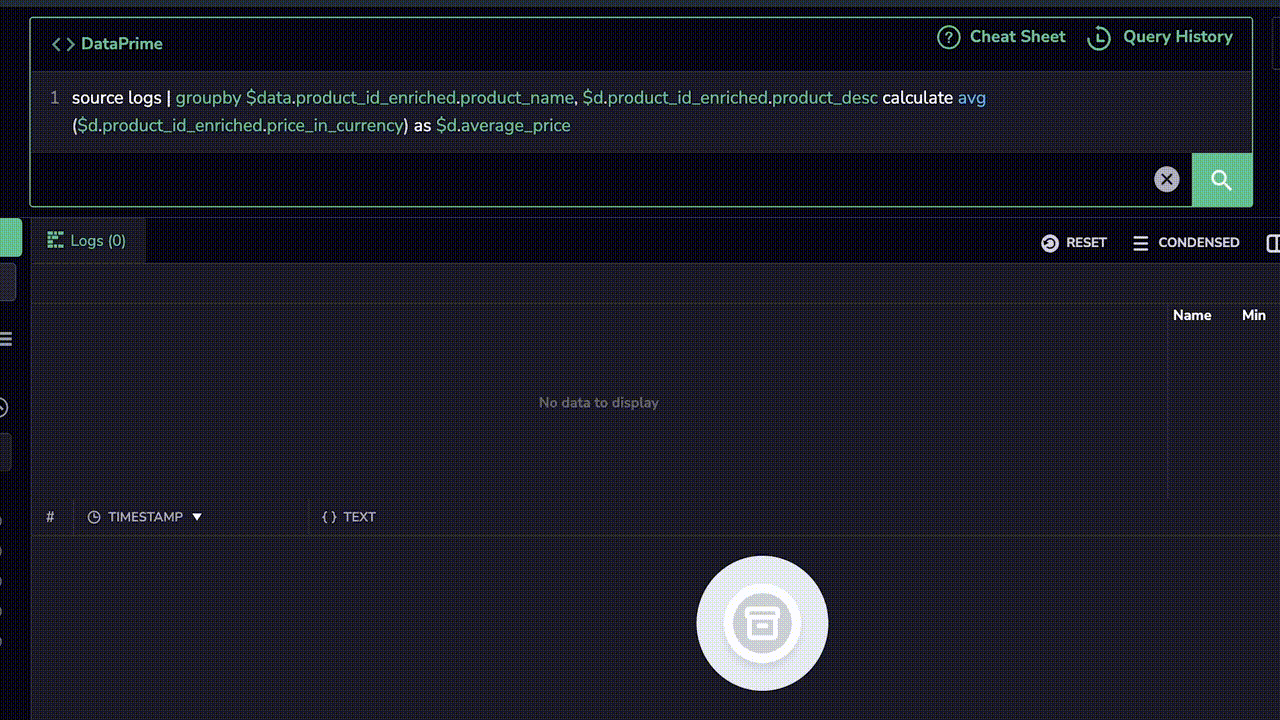
Coralogix Remote Query doesn’t just allow users to pull the data from remote storage. They can also perform aggregations on their data using the DataPrime syntax (SQL and Lucene are also supported). This enables true data discovery and the ability to directly generate reports on archived data, instantly.
Coralogix vs Datadog: Remote Query is the Next Generation of Archiving
Whether it’s the feature-set, the price point, the analytics capabilities, or the performance, by our overall estimations Coralogix wins with long-term storage of observability data. The capabilities available as part of the Remote Query feature are entirely unparalleled in the industry. Because our unique and fundamentally different architecture drives them, many of our competitors are years away from meeting the standard that we have set.
If you don’t believe us, sign up for a free trial and try it for yourself.


