 The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 
Stay ahead with proactive monitoring
Infrastructure monitoring
When the application isn’t the problem, the issue is often buried in the infrastructure. Coralogix helps you jump straight to the root cause.
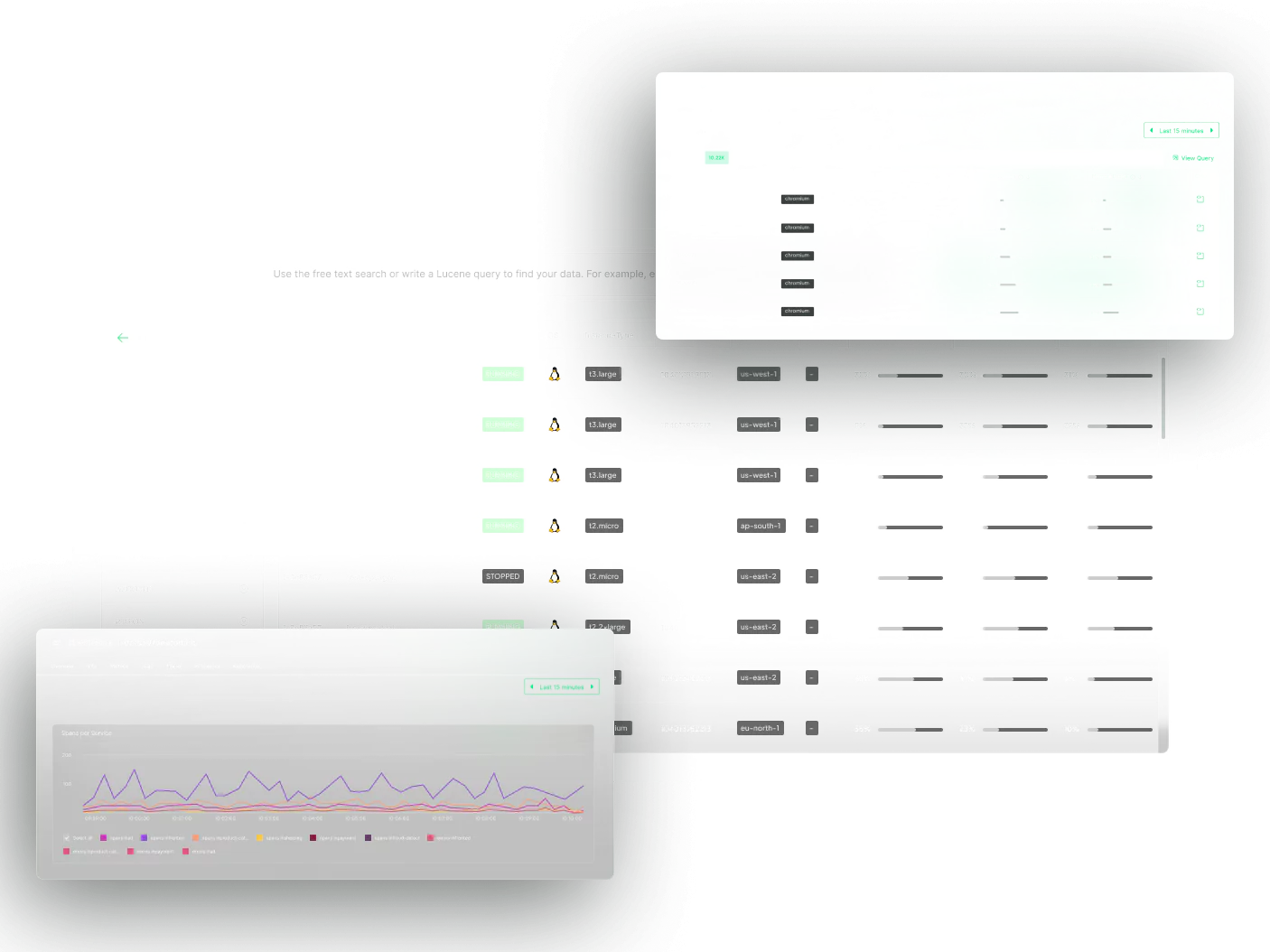
From application alerts to infrastructure answers

Investigate across layers
Correlate thousands of infrastructure metrics with logs and traces to understand where issues originate and link them to performance and business outcomes.

Reduce MTTD and MTTR
Spot CPU contention, memory saturation, and noisy neighbor scenarios before they ripple into application errors or degraded customer experience.

Debug faster
Filter telemetry by precise time ranges to trace incidents to root cause without losing context between logs, metrics, and infrastructure views.
Build clean, reliable, observable infrastructure
Centralize your infrastructure footprint
Ingest infrastructure data across every cloud, account, and environment into one unified view. Monitor every host, container, cluster, and network interface in real time with standardized templates and automated discovery.
Surface insights in seconds, not hours
Investigate infrastructure performance issues with full visibility into metrics, logs, and traces. Jump from pod to process to log line in seconds, tracing the problem to application impact in two clicks.
Track what’s running and why it’s there
Track infrastructure composition across accounts and regions to ensure uniformity in server types, sizes, and configurations. Avoid resource sprawl and simplify optimization by keeping your architecture clean, consistent, and easy to manage.
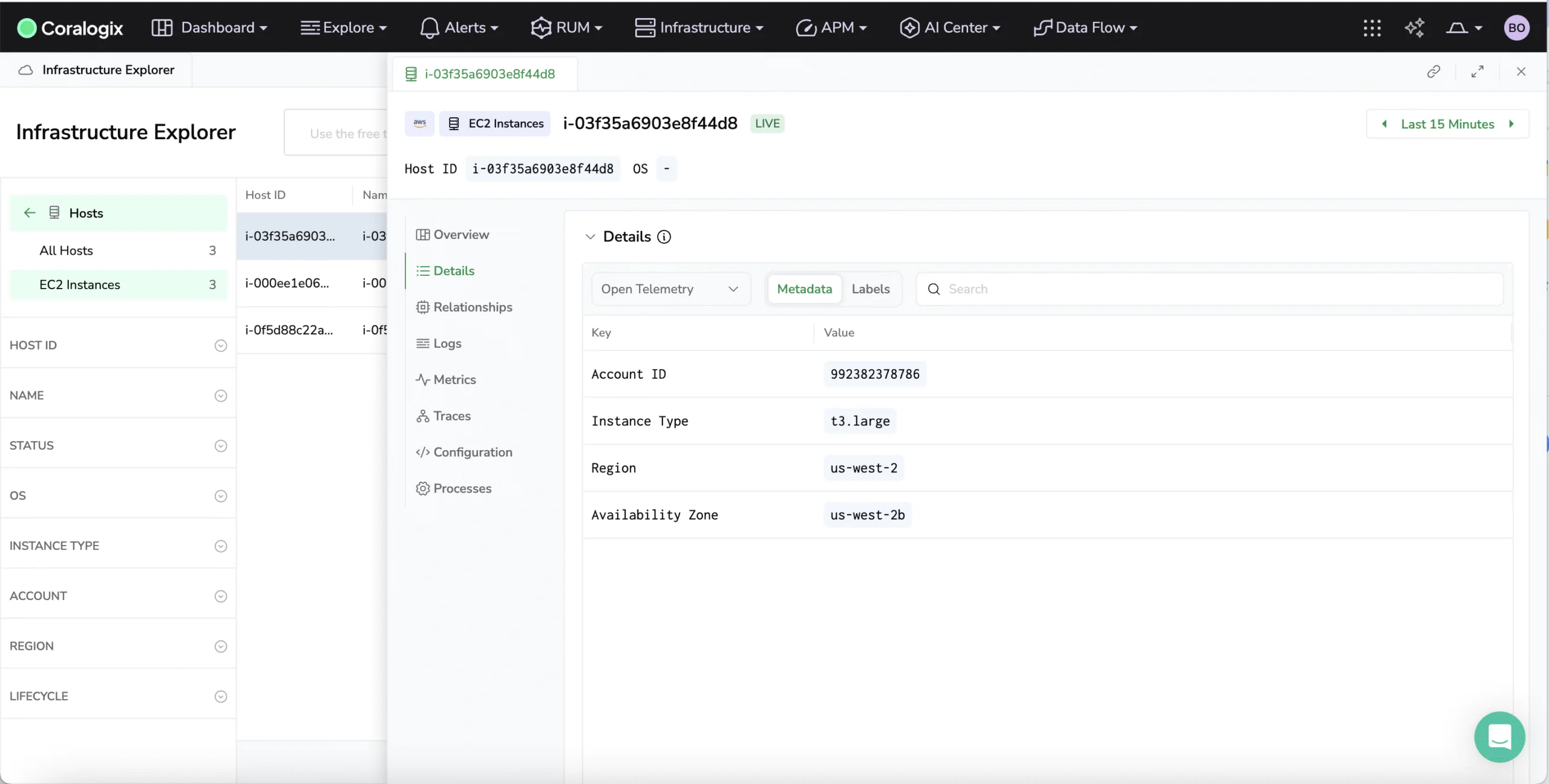
End-to-end infrastructure visibility
Collect metadata like tags, regions, and instance types for every resource, and retain historical snapshots to track how infrastructure evolves over time. No manual reporting required.
Track real-time configuration states and map system changes over time. Detect misalignments early to prevent cascading issues across services.
Visualize pod-to-node, service-to-volume, and other key Kubernetes relationships to understand impact and dependency chains across your infrastructure.
Scalable observability for your systems
Scalable observability for your systems
In-stream analysis
Continuous, real-time monitoring of AI interactions, detecting risks and performance issues before they impact users.
Infinite retention
Ensures historical AI data remains accessible for long-term trend analysis and deep troubleshooting without data loss.
DataPrime engine
Tracks token usage and suspicious resource consumption, helping teams prevent cost overruns while maintaining AI efficiency.
Remote, index-free querying
Lightning-fast searches without the overhead of indexing, ensuring real-time AI observability without unnecessary storage costs.