

The limits of MCP and how Olly surpasses them


Model Context Protocol (MCP) servers act as adapter layers between clients and AI based workloads. MCP installation into an IDE, such as Cursor, brings a wealth of information directly into the developers primary tool, minimizing context switching and, especially in the world of observability, bringing telemetry closer to the code.
MCP is not without its limits. These limits initially seem trivial, but in time, some of the inherent limitations to a basic MCP implementation become apparent. What are these limits, and how do they impact engineers on their day to day work?
Our experiment

Both Olly and Cursor (with Coralogix MCP installed) have been targeted at a Coralogix account with telemetry from a medium sized Kubernetes based microservices architecture. Within this account, multiple problems are being simulated, such as traffic spikes, latency spikes, newly introduced errors from every layer, as well as database related issues.
Root cause analysis with a high level request
AI systems encourage conversational interaction. This leads engineers to ask questions as they would of one of their colleagues. MCP struggles with this, because it does not have the suite of agents and tools, coupled with the essential context, necessary to decipher the deeper meaning to a high level request. For example, we integrated MCP into Cursor and tested it with the following problem:
Figure out why checkout latency spiked yesterdayNote that while the answer to this question relies on evidence from the telemetry, we are not asking for a simple explanation of what happened – we’re looking for the root cause.
How did MCP respond?
We’ve given some indicator of technical metrics to go after, but the root cause could be anywhere. The question is not asking how much the latency spiked by, or which period was the highest. They would be okay for an MCP server to handle. It is asking to figure it out.
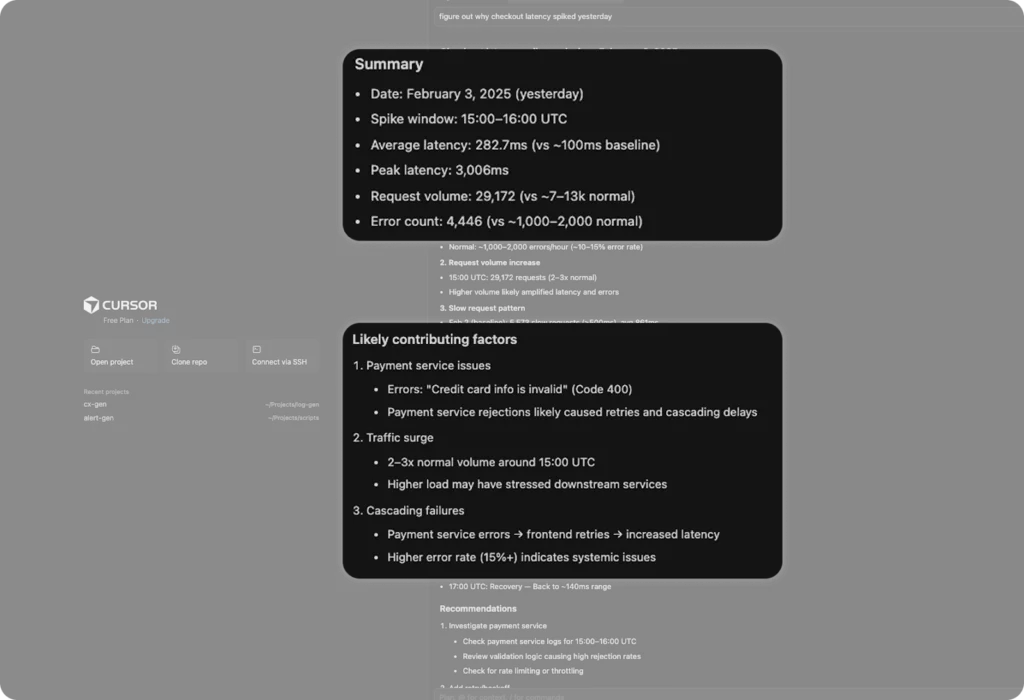
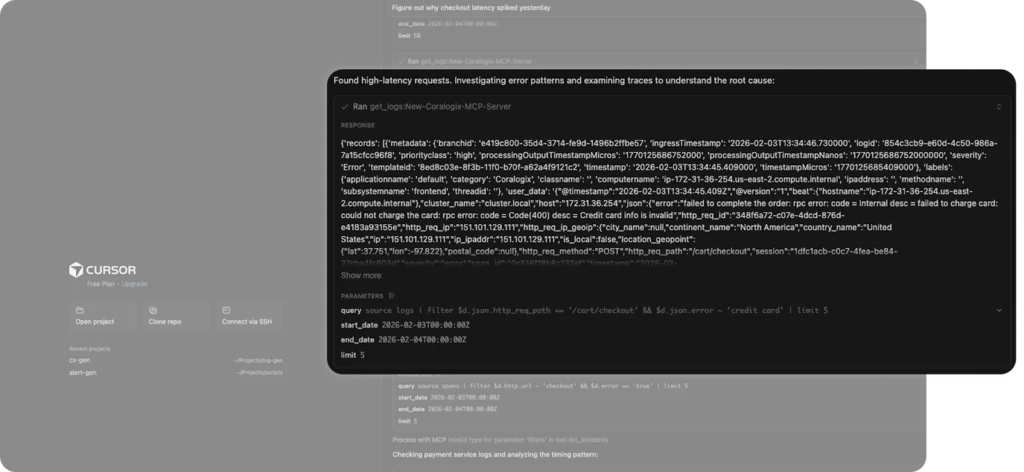
MCP has done a good job of the basics – looking out for average latencies and baselining them against hourly buckets to find the highest spikes. Where things become challenging is in the root cause analysis, in which the likely contributing factors are largely superficial, and a normal part of the background noise of any payment platform. “Credit card info is invalid” is a very common error in any system seeking to process payments.
After identifying the pattern, the investigation paused. MCP isn’t able to make autonomous decisions, so its ability to define hypotheses, leverage multiple agents and evaluate the responses is limited. This is not the case with Olly.
MCP responds. Olly investigates.
We provided the same query to Olly, with absolutely no background information, on the same account. It’s crucial to see how Olly moves through the problem, to understand the fundamental difference.
Generating a plan
Olly begins interactions by generating a plan. This plan is crucial, because it frames the investigation, and ensures that Olly has a clear idea of what the request is. Where MCP tore off and began querying, Olly has the tools and sophistication to do what any good engineer does: form a hypothesis.
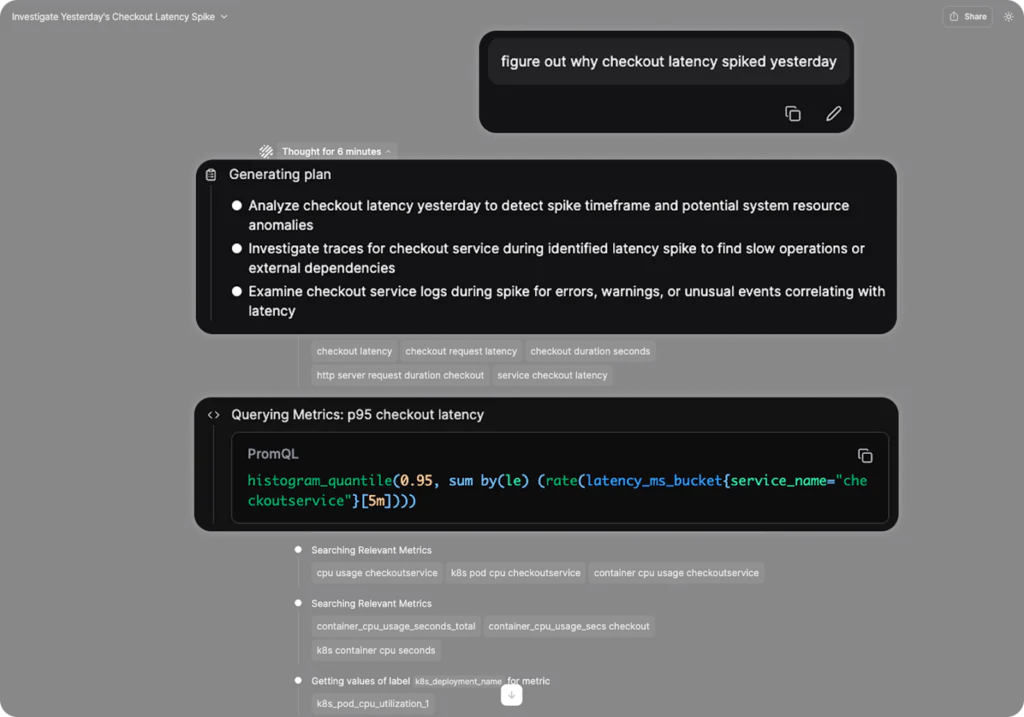
Olly’s process means that it can break down a complex issue into multiple pieces. This enables Olly to tackle a complex problem, and investigate it thoroughly. This thorough investigation means that it is more readily able to figure out the root cause of a problem.
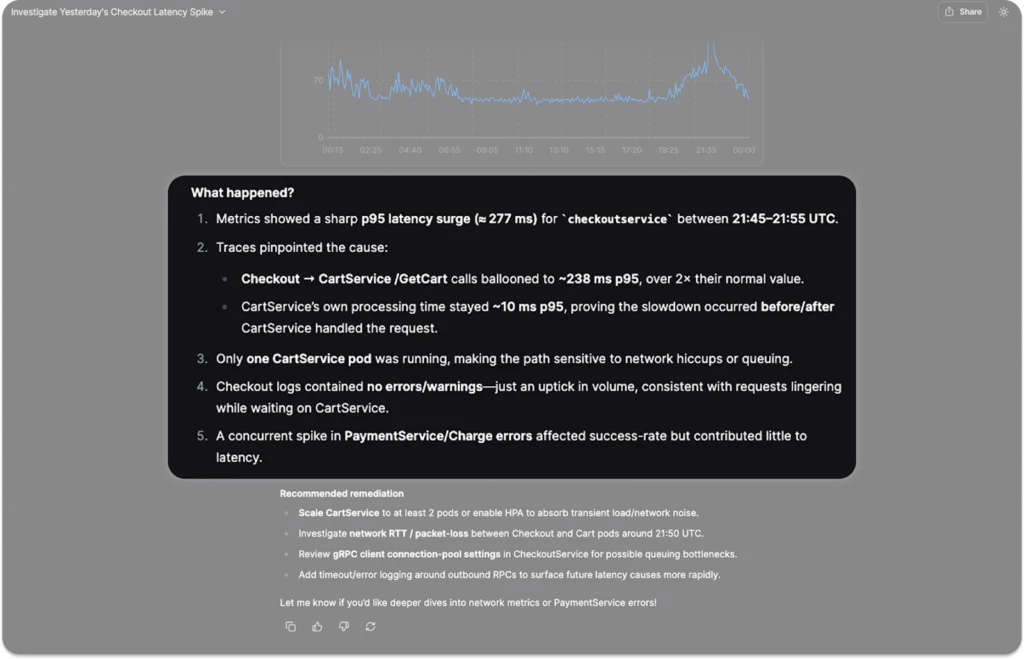
We can see that thanks to Olly’s planning and much more rigorous research, it was able to identify that the root cause lay outside of the cart service, because it leveraged the metrics that showed the processing time of the CartService.
It even saw the red herring, the payment and charge errors, that were correlated with the latency spike, but it saw enough to know that they were not causally related. The recommendations lead us to another key power that Olly has.
Olly knows your system, MCP doesn’t
MCP is stateless, merely transmitting prompts to queries. This is extremely useful for in-IDE querying, but for running high level investigations, context is king.
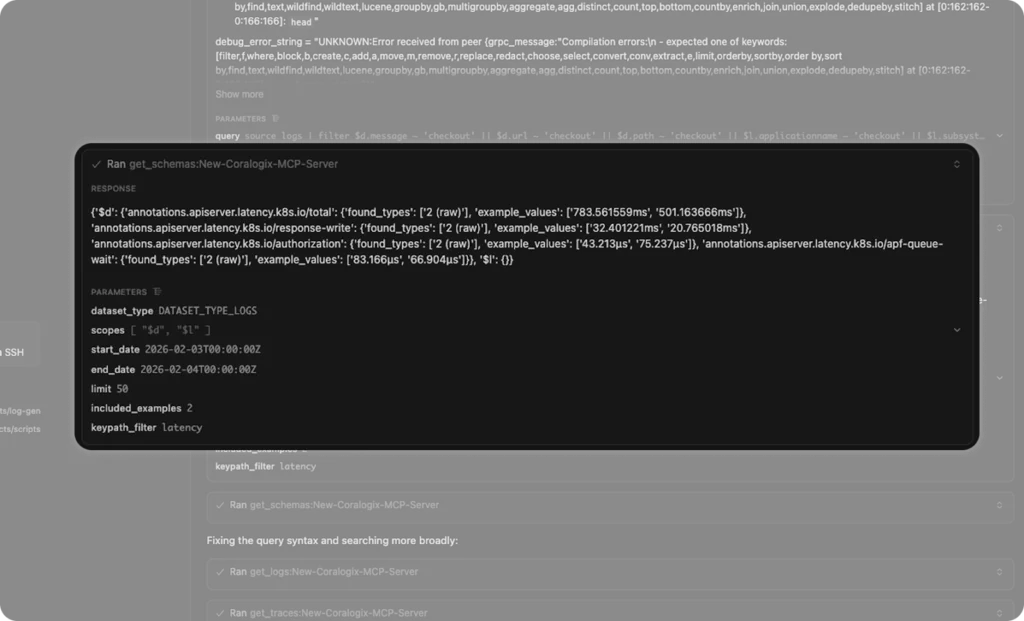
We can see in the MCP example, that early in the investigation process, the MCP server queried the schema store, looking for keys that it could use to find out more. This is an effective strategy for a stateless tool, but it introduces a lot of potential for incorrect conclusions.
Olly has done its homework
Olly is constantly indexing and scanning metadata (note, not actual customer data, only the metadata) so that it has an up to date, clear understanding of the keys, fields, time series metrics, span tags, alerts and dashboards that it has at its disposal.
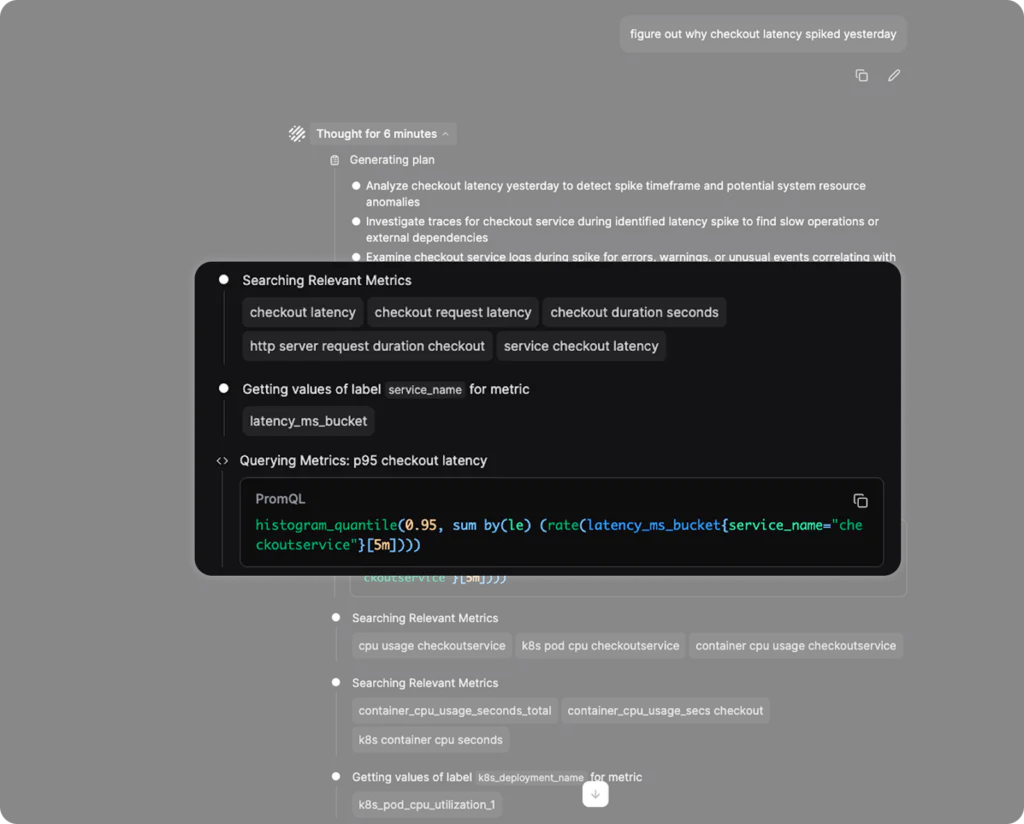
As such, when it was deciding which metrics to go with, it found much more relevant information from its own metadata.
Olly’s understanding of your system metadata accelerates investigation performance, minimizes noise and ensures a consistently correct analysis.
An Olly investigation goes much deeper
Olly employs the context engineering loop, between context, agents (and tools) and evaluation. This means that it is aware of when the investigation has gone far enough. We asked a complex question with multiple nuanced answers. This is most clearly showcased by the limited investigation conducted by MCP.
On raw numbers alone, we can see that the MCP investigation ran 18 individual telemetry scans when looking for a clear answer. With the same prompt, backed by the same data, ran 33 different queries. MCP inherently lacks the tooling necessary to recognise the appropriate depth for a problem.
Twice the queries, but what about tokens? Olly handles that too
Olly ran just under 2x the queries that MCP did for the same problem, and came to much more robust conclusions and recommendations, but with twice the queries, did Olly consume a lot more tokens?
The answer is surprising: Olly consumed far fewer tokens. This is because Olly is natively trained to optimise queries, for example if we review the queries ran during the autonomous investigation, we see a pattern:
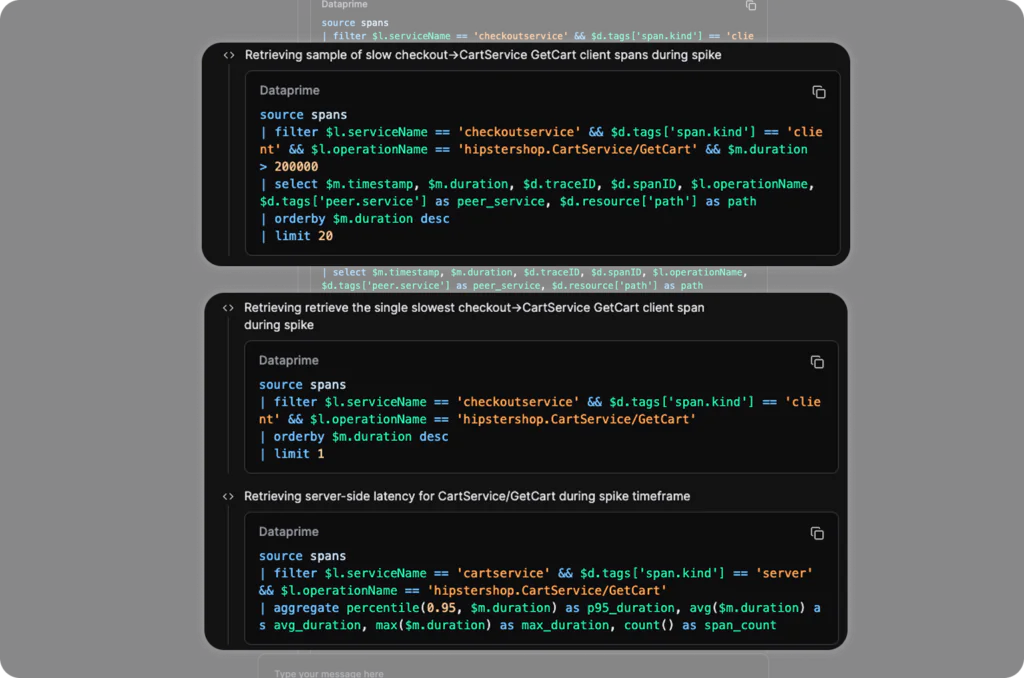
Olly makes use of limits and aggregations to ensure that representative samples are used over extracting huge volumes of raw data. The aggregations mean that the responses have a very small footprint.
If Olly does need the raw data, it leverages AI specific formatting, like TOON, to minimize token consumption per query. Olly is designed, whether querying aggregates or raw data, to use the minimum responsible amount of tokens it can during an investigation.
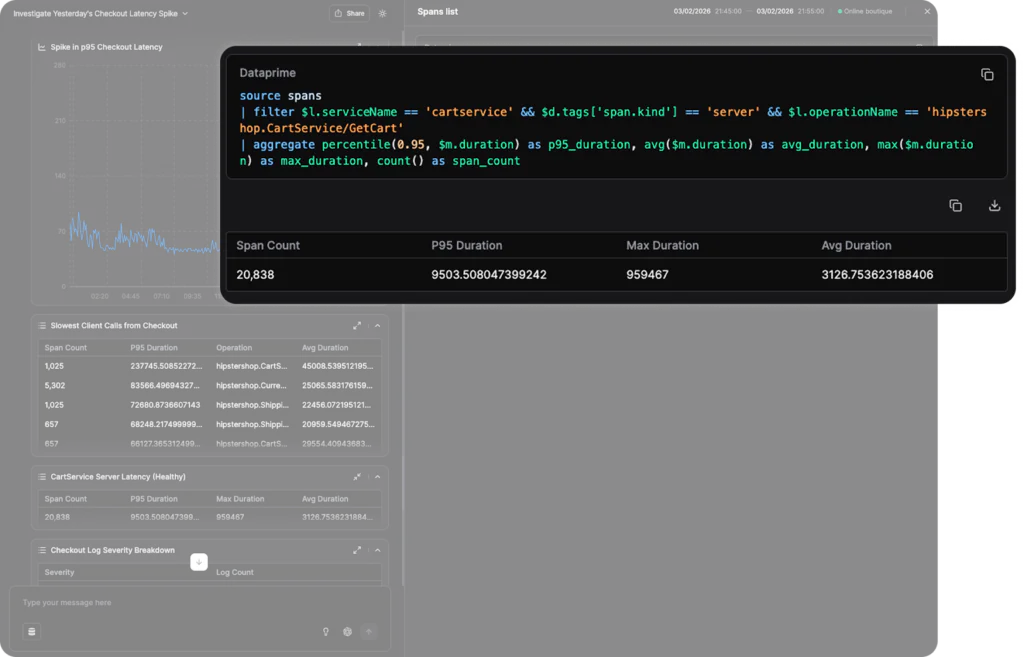
This makes Olly uniquely efficient with token consumption. When we observe similar queries from the MCP server, we see raw data being pulled back. MCP will leverage limits, but 5 logs is not a good sample size, because the MCP server does not have the sophistication necessary to trade off between token consumption and a representative sample.
Olly isn’t subject to MCP’s model problem
Olly’s recommendations are driven by an enormous amount of training within the models themselves. Rather than loose correlations or general assessments of what might solve, Olly combines a specific knowledge of your system with a wealth of training on good practice within almost every conceivable application infrastructure.
What did Olly recommend vs an MCP server?
MCP acts as an adapter layer, so the contextual information that you’re bringing is limited by the consuming model. This will vary the quality of the analysis, based on the client you’re using. This inconsistency will cause confusion, since some models will recommend one course of action, and other models may expressly forbid the same tact.
Consider the recommendations given by our MCP server after our initial prompt. These recommendations are uncited, so it is difficult for the user to make an assessment of whether MCP is correct here or not.

The recommendations are also generic. There is no evidence in the telemetry of rate limiting / throttling, network issues or external payment API calls timing out. They are good ideas, but they lack specificity. This is a fundamental limitation with an MCP workflow – it all depends on the quality of the model that is making the request. With an MCP installation into Cursor, the inference is limited.
How do Olly’s recommendations differ?
Olly brings specific recommendations based on the evidence. We can see that Olly puts the relevant measurements next to the recommended remediations, so that users can easily see the rationale and track the chain of reasoning.
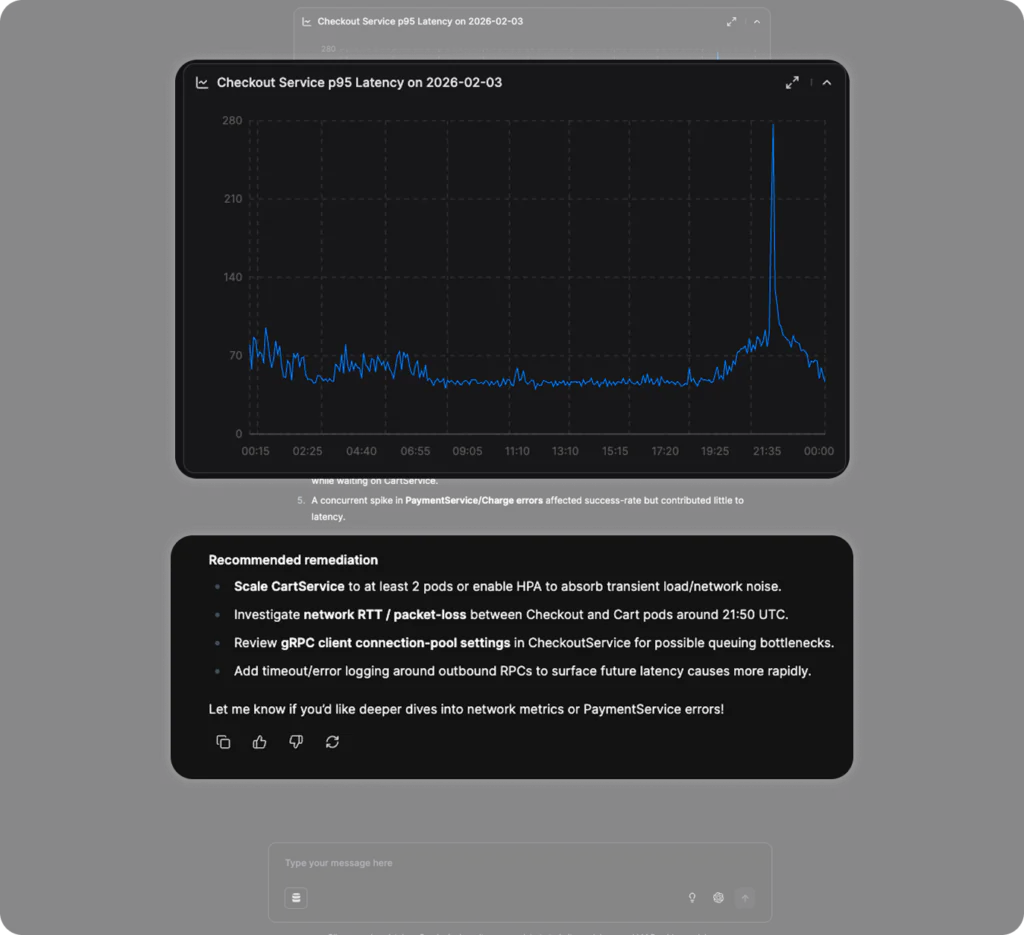
In this example, Olly has found something very specific that was missed by the MCP server – The Cart service has only 1 pod running. Olly brought domain knowledge around good high availability practices, and anyone who has deployed an application to Kubernetes knows that a single pod is a risky proposition – multiple pods deployed across nodes is far better. Olly recognized this too.
It also identified that the slowdown was not inside the CheckoutService and so made recommendations to focus on queueing, connection pooling and other constraints around the service.
The choice is yours
MCP brings telemetry into the IDE and reduces context switching. For targeted queries and quick validation, it works well. But it remains a stateless adapter layer, dependent on the consuming model and limited in its ability to plan, hypothesize and investigate autonomously.
Olly is built for investigation. It understands your system’s metadata, generates a plan before it queries, evaluates competing signals, and distinguishes correlation from causation. It goes deeper when the problem demands it and stays efficient while doing so.
If you’re looking for lightweight, in-IDE querying, MCP delivers. If you’re looking for autonomous, evidence-backed root cause analysis with system-aware recommendations, it’s time to put Olly to work.
To find out more, check out ollyhq.com.


