

DataPrime at Ingest: Fine-Grained TCO Routing with DPXL


Programmable routing changes the rconomics of observability
The real economic decision for observability happens at ingest, before storage, billing, and retention choices are locked-in. Until now, the logic governing that decision could only see three broad fields: application, subsystem, and severity.
That just changed. TCO routing now matches on any field in the event payload, including nested keys, custom fields, and event body content, using DPXL, the DataPrime Expression Language. The same filter logic teams already write in Explore can now govern where data goes at the moment it arrives.
The old way: broad rules, blunt tradeoffs
The TCO Optimizer has always been one of the most impactful cost levers in Coralogix, route business-critical data to High, push monitoring data to Medium, archive compliance logs to Low. Well-tuned TCO policies routinely cut observability costs by 40–70%. But there is a hard ceiling on how precise those policies can be: your TCO filters are only as fine-grained as the fields they can read. Until now, that meant three fields: application, subsystem, and severity.
A policy looked like this:
<v1> $l.applicationname == 'payments-service'That catches everything from payments-service, production errors, staging debug output, load test traffic, because the filter can only see the application label. Not all logs from the same app have the same value. Not every trace with the same subsystem deserves the same treatment. And not every spike in volume should be handled with a simple keep-or-drop decision.
The result is familiar: too much expensive data kept hot, not enough flexibility, and constant tension between visibility and budget. Teams worked around it — some by restructuring application and subsystem naming to encode routing intent, others by accepting imprecise routing and overpaying. The instinct was right; the tooling just couldn’t keep up.
What changes with DPXL at ingest
The Coralogix pipeline now evaluates TCO routing using DPXL, the expression language at the core of DataPrime, bringing the same filter logic teams already use in Explore to the moment data enters the system.
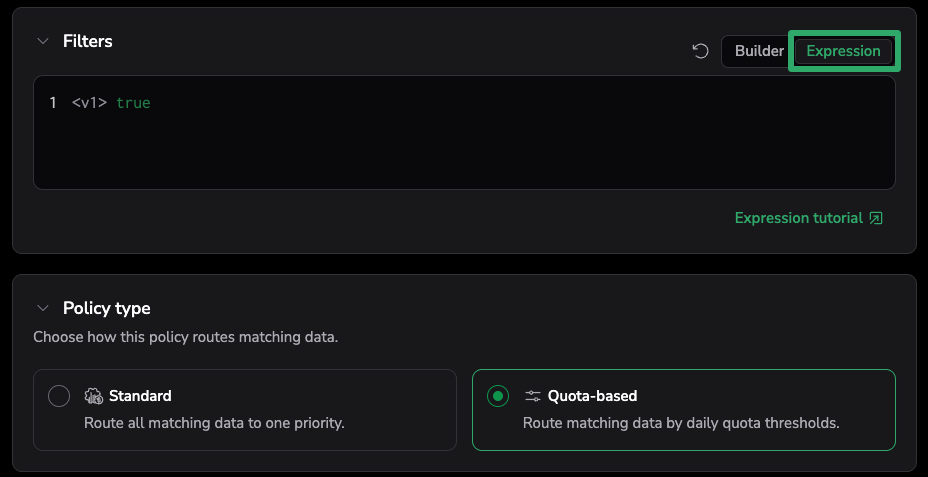
If you’re wondering how DPXL relates to DataPrime: think of DataPrime as a set of concentric capabilities. The full language sits at the outer ring: groupby, join, aggregation, etc. That’s what you use at query time, against data at rest. DPXL is the innermost ring: the subset of DataPrime built for the streaming pipeline, filtering, boolean logic, comparisons, and string operations. It doesn’t do aggregation or joins; those require the full language running against stored data. What it does is let you match on anything in your data: metadata, labels, and any field in the event body, including nested and custom keys.
If you’ve written a filter command in DataPrime, you already know the syntax. DPXL uses the same three keypath categories:
$mfor metadata (e.g.,$m.severity,$m.timestamp)$lfor labels (e.g.,$l.applicationname,$l.subsystemname)$dfor user data fields (e.g.,$d.environment,$d.kubernetes.pod_name,$d.tenant_id)
And the same operators and functions you use in queries: ==, !=, &&, ||, .startsWith(), .contains(), .matches(), .in().
In the TCO Optimizer UI, policy filters now offer two modes: Builder (the familiar structured picker for application, subsystem, and severity) and Expression (where you write DPXL directly). Existing Builder-mode policies continue to work, they generate DPXL under the hood now. Expression mode is where the new power lives.
From source identity to data content
Here’s what this looks like in practice.
Before: Route by label. All logs from payments-service go to High, regardless of what they contain.
<v1> $l.applicationname == 'payments-service'Now: Route by content. Production payment errors go to High. Everything else from that service goes to Medium.
Exception policy (placed first, because policies evaluate top-to-bottom and first match wins):
<v1> $l.applicationname == 'payments-service' && $m.severity.in(ERROR, CRITICAL)Broad policy (placed below):
<v1> $l.applicationname == 'payments-service'Going deeper: Route by fields in the event payload that have nothing to do with application or subsystem labels.
Route VIP tenant production traffic to High without touching everyone else’s policy:
<v1> $d.environment == 'production' && $d.tenant_id:string.in('acme','globex','initech')Route by Kubernetes dimensions — send all payment-namespace logs from production apps to High:
<v1> $l.applicationname.startsWith('prod-') && $d.kubernetes.namespace == 'payments'This is the fundamental shift: routing by what the data says, not just where it came from. Teams can now map business value to storage outcome at the point where that decision has the biggest financial impact.
Why this matters
Most organizations don’t have a data volume problem. They have a data discrimination problem: they know some data is mission-critical, some useful but not urgent, some necessary only for retention, but their pipeline can’t tell the difference. Routing by source is the only option when your filters can’t read content, and approximation costs money. What they’ve lacked is a way to encode that judgment precisely, at the moment it has the most financial impact.
Stop paying High-tier pricing for data that doesn’t deserve it. Staging noise, single-tenant debug output, known-noisy log patterns, these don’t need to share a storage tier with your production payment errors. DPXL lets teams target those specific conditions directly, so cost is matched to value at the field level, not the application level.
The team that already writes your queries can now own your cost policies. TCO tuning has always had an ownership problem: it requires routing expertise that doesn’t naturally live with the engineers who understand the data. Because DPXL is the same language teams already use in Explore, the person who can write a filter to investigate a spike can turn that same expression into a routing policy, no separate tool, no second syntax, no handoff.
Cost decisions made too late are already sunk. Once data enters a premium storage path, the economic choice is behind you. You can analyze it differently, archive it later, but you’ve already paid for the wrong tier. DPXL routing moves that decision to the only moment it actually changes the bill: before storage.
Getting started
If you’re ready to move beyond three-field routing, the transition is straightforward:
- Open the TCO Optimizer under Data Flow.
- Create or edit a policy.
- Switch from Builder to Expression mode.
- Write a DPXL expression targeting any combination of metadata (
$m), labels ($l), and user data fields ($d). - Set the priority and archive retention as usual.
DPXL infers types for simple comparisons, but when using .in(), always cast the keypath explicitly, DPXL does not infer types for collection functions (e.g., $d.country:string.in('us','il','gr')). The UI handles the <v1> version prefix automatically; you only need to include it when working with the API.
Important: TCO routing evaluates before enrichment in the pipeline. Fields added by enrichment rules (parsing rules, custom enrichments) are not available in DPXL policy expressions. Your expressions can only match on fields that are present in the original event as received. If no policy matches an event, it routes to the default priority configured for that telemetry type.
The DPXL documentation covers the full expression syntax, supported functions, and type casting.
The bigger shift
The bigger story is not just that TCO got better routing. It’s that DataPrime is moving upstream. Until now, DataPrime was primarily associated with querying and exploring data after ingestion, the outer rings of the language, running against data at rest. DPXL at ingest brings the innermost ring into the pipeline. The pipeline now speaks the same language as the query layer, and it’s positioned to absorb more of those outer rings over time.
That opens the door to smarter governance, more graceful cost control, and better alignment between what data is worth and what you pay for it. Because once routing becomes programmable, observability cost control stops being reactive. It becomes intentional.


