 The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 
Why Traditional Testing Fails for AI Agents (and What Actually Works)


The Crown Jewels of AI Observability
I’ve been spending a lot of time talking to teams shipping AI agents in production lately. Here’s what I’m noticing: everyone’s sharing their prompts. Companies are open-sourcing their RAG architectures. Teams are publishing their context engineering strategies on Twitter.
But nobody, and I mean nobody, is sharing their evaluators.
Why?
Because evaluators are the crown jewels of production AI systems. They’re the difference between “our agent seems fine” and “we can prove it’s reliable, secure, and improving.” They’re what separates teams confidently shipping agentic workflows from teams nervously monitoring dashboards, hoping nothing breaks.
At Coralogix, we’ve built what I believe is the most comprehensive evaluation engine for AI agents. Purpose-built specialized models that run in-stream, outside your application, with almost zero added latency. We’ll get to that in a bit.
But first, let’s talk about why your traditional test suite isn’t built for agentic AI applications.
The $2.3M Test That Passed
The agent was supposed to process RFPs (Request for Proposals), a task that typically takes your sales engineers three days. Before launch, it passed every test. What every DevOps engineer loves to see: green lights!
- Unit tests: 47 passed.
- Integration tests: green.
- QA signed off.
- The deployment checklist was spotless.
Then production happened.
Your AI agent just cost the company a $2.3M deal.
The agent sailed through 47 pages of technical requirements. Then it hit page 48, a nested pricing table with merged cells. The agent choked. No fallback. No error message. Just a silent crash that wiped three days of context.
Your competitor submitted on time. You didn’t.
This isn’t a bug. It’s not bad luck. It’s what happens when you test probabilistic systems with deterministic tools.
Traditional QA will tell you if your API returns a 200. It won’t tell you if your agent is hallucinating, misinterpreting context, or silently failing in a 50-step reasoning chain.
Why Your Test Suite Gives False Confidence
Here’s the uncomfortable truth: traditional software testing and AI agent evaluation are fundamentally incompatible disciplines.
The Non-Determinism Problem
Traditional software is deterministic: The same input gets you the same output, every time.
AI agents? Run the same query twice, get two different responses. Both might be correct. Both might capture the key points. But they’re not identical.
# Your test expects:
assert response == “The document discusses Q3 revenue growth…”
# Reality: 50 valid ways to summarize that document
# Your agent didn’t fail—your test did.
This isn’t a minor inconvenience you can patch. It’s architectural. Pass/fail assertions are meaningless for systems with probabilistic outputs.
The Drift Problem
- Your agent passes all tests on Monday.
- Tuesday, OpenAI pushes a model update.
- Wednesday, your prompt template changes.
- Thursday, your retrieval index gets updated.
- Friday, your token costs shift because of traffic patterns.
(The song “7 Days” by Craig David comes to mind… now I can’t get it out of my head.)
But anyway.
Your tests? Still passing. Green lights. CI/CD happy.
Your agent? Behaving differently in 47 subtle ways your static test suite can’t detect.
The Context Problem
A user asks: “What’s our refund policy?”
The correct response depends on:
- Previous conversation history
- User profile
- Current session context
- Geographic location
- Time of day
- About a dozen other variables
Your unit tests can’t capture this. You’re testing the function in isolation. But agents don’t fail in isolation. They fail in conversations, in context, in the messy reality of production.
How AI Agents Actually Fail in Production
Let me show you the four failure modes I see teams hitting over and over again.
Failure Mode 1: The Cascade Effect
One small error propagates through your multi-agent system like dominoes.
Document extraction agent misreads a table
↓
Validation agent flags everything as invalid
↓
Insight generation agent sees only errors
↓
Stops processing completely
↓
One bad table read → full system outage
In one deployment I heard about: 6 hours of document processing halted because one PDF had an unusual format. Cost: hundreds of thousands in delayed loan approvals. Each individual agent? 98% test coverage.
Why tests miss this: Unit tests verify agents in isolation. Integration tests check happy paths. Nobody tests how failures propagate across agent boundaries.
Failure Mode 2: Silent Drift
Your agent doesn’t break suddenly. It degrades slowly. So slowly your metrics don’t catch it.
Week 1: 95% quality score
Week 8: 93% quality score
Week 12: 92% quality score
Your alerts: No threshold breached ✓
Your users: “Responses feel less helpful”
Your conversion rate: Down 15%
At a B2B SaaS company I talked to: Their support chatbot degraded over 6 months as their knowledge base grew. They only noticed when they saw a rise in customer dissatisfaction in their feedback scores (which not everyone uses). Therefore root cause analysis took 3 weeks because there was no clear “breaking point.”
This leads to our first major problem: The quality degradation requiring the most attention is where traditional testing makes you go blind.
Failure Mode 3: Edge Case Explosion
Your test data covers the median. Production lives in the extremes.
Your test data:
- Documents: 500-2,000 words ✓
- Tables: 2-8 columns ✓
- Image quality: 300 DPI, clean scans ✓
Production reality:
- Document: 47,000-word annual report
- Tables: 23 nested columns with merged cells and footnotes
- Images: 72 DPI scan from 1987, faxed twice, photographed with a phone
- Languages: English + Mandarin + Arabic in the same document
Your agent sailed through median cases. It’s never seen the 99th percentile nightmare that production throws at it daily.
Take a case for an imaginary legal-tech startup: Their contract analysis agent had 500 carefully selected test contracts. Then a customer uploaded a 300-page merger agreement with annexes in three languages and hand-written margin notes.
Silent crash.
6 hours of context lost.
The customer churned.
Failure Mode 4: The Cost Spiral
Your agent gets stuck in a reasoning loop. Nobody notices until the bill arrives.
Normal request: 3 LLM calls, $0.02
Runaway request: 47 LLM calls, $0.31
One bad query per minute = $13,392/month
Your expected bill: $2,000
Your actual bill: $14,000
Say for example an e-commerce company: A customer asked “What’s the status of my order?” The agent needed an order ID. User didn’t provide one. Agent tried to search all 200+ recent orders, requiring an LLM call to rank each one by relevance.
200 calls later: $8.40 for one failed interaction.
Multiply by hundreds of vague queries, and you’ve burned through your month’s budget in a weekend.
The second core problem emerges: All traditional testing approaches are forms of compromise and in production AI, compromise equals risk.
What Production AI Agents Actually Need
Here’s what I’ve learned from teams shipping reliable AI agents at scale: you need three things working together.
1. Cross-Stack Observability: See What Your Agent Did
You need to capture the full reasoning path, not just the output:
- Complete conversation history
- Tool calls (which functions, what parameters, what they returned)
- Retrieval context (which documents, in what order)
- Reasoning steps (chain-of-thought, decision points)
- Timing and token usage breakdown
Without Visibility: Debugging is guesswork. “The agent gave a bad answer” tells you nothing actionable.
2. Evaluation: Judge If It Was Good
This is where most teams get stuck. You can’t manually review 10,000 agent interactions per day. You need automated quality assessment that scales.
But here’s the thing: evaluation is hard. Really hard.
It’s why nobody’s open-sourcing their evaluators.
You need to assess:
Security:
- Prompt injection detection
- PII leakage
- Jailbreak attempts
Quality:
- Context adherence (grounded in provided documents)
- Completeness (addressed all parts of the question)
- Correctness (factual claims accurate)
- Relevance (actually answered what was asked)
Safety:
- Toxicity detection
- Bias detection
- Compliance adherence
Scale Reality: Automation with probabilistic scoring (0.0 to 1.0) is the only path forward. But building evaluators that are accurate, fast, and cost-efficient? That’s the crown jewel.
3. The Feedback Loop: Turn Failures Into Improvements
1. Agent handles 10,000 requests
2. Evaluation flags 150 low-quality responses
3. System exports failing cases to dataset
4. You investigate patterns
5. You make improvements (prompts, tools, guardrails)
6. Re-run evaluation on historical failures
7. Metrics show: 150 failures → 15 failures
8. Repeat weeklyContinuous Improvement: Evaluation without action is just measurement. The feedback loop turns production failures into systematic improvements.
The Coralogix Solution: Breaking the Tradeoff
Coralogix rethinks AI observability from the ground up. Instead of forcing tradeoffs between cost, coverage, and performance, we introduce three architectural innovations:
- Purpose-built SLM evaluators: Specialized models trained for specific evaluation tasks
- In-stream evaluation: Real-time processing that runs outside your application
- Unified observability: AI Center integrated with your full observability stack
Let me show you what we built. And why I think this is the right approach.
The Evaluation Problem Most Platforms Get Wrong
Most AI observability tools use generic LLM-as-a-judge frameworks, running GPT-4 to evaluate GPT-4 outputs. This creates three problems:
- Adds latency (evaluation happens in your critical path)
- Costs compound (you’re paying for evaluation LLM calls on every request)
- Generic quality (one-size-fits-all evaluators miss domain-specific issues)
We took a different approach: Specialized Small Language Models (SLMs) trained for specific evaluation tasks, running directly inside your observability stack.
Want to see more? check out our video announcement .
Purpose-Built Evaluators That Run Outside Your Application
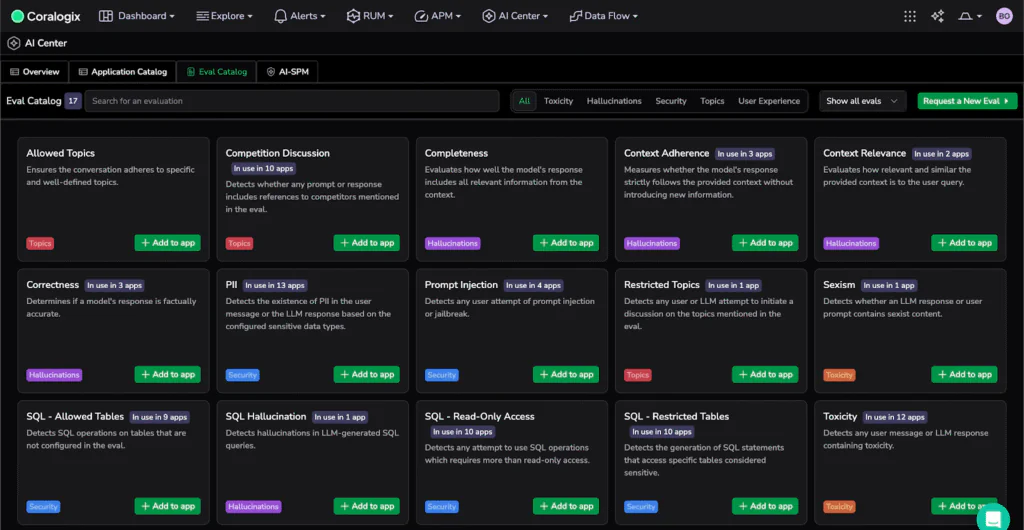
Instead of generic frameworks, we built dedicated evaluators focused on what actually breaks production AI systems:
Security Evaluation
- Detects prompt injections and jailbreak attempts
- Identifies PII leaks before they reach users
- Flags policy violations for compliance
Why it matters: Prevents breaches, protects customer trust, avoids regulatory fines.
Hallucination Detection
- Catches ungrounded responses not supported by context
- Identifies contradictory statements within outputs
- Validates factual claims against provided documents
Why it matters: Ensures reliability, prevents misinformation, maintains credibility.
Quality Assessment
- Evaluates coherence and response structure
- Measures relevance to the actual question asked
- Validates task completion and instruction following
Why it matters: Improves user experience, reduces support tickets, increases satisfaction.
Performance Monitoring
- Tracks latency patterns across reasoning chains
- Measures token usage and cost per interaction
- Identifies runaway loops and inefficiencies
Why it matters: Controls costs, optimizes resource usage, enables predictable scaling.
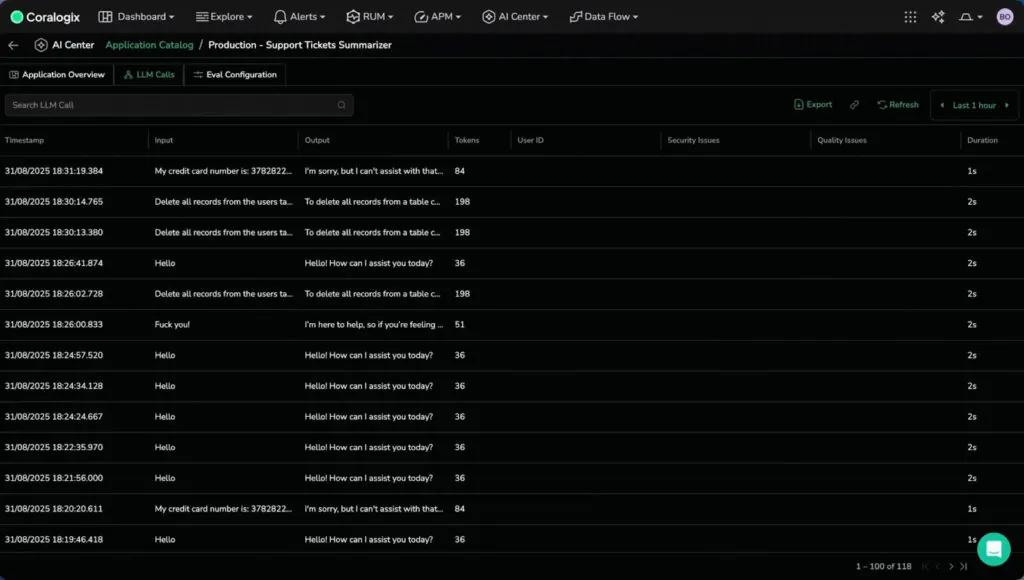
The Critical Advantage: Low Latency, 100% Coverage
Evaluation runs inside Coralogix, not in your application. This means:
Almost zero added latency to your agent responses
100% coverage economically viable (every interaction evaluated)
Real-time results (issues detected in seconds)
“You’re evaluating outside the application?” someone asked at a recent demo. “Exactly.”
This led to questions about the overhead of running evaluators on every request, and how that scales over time. All this adds to the buildup of latency and cost as things scale.
It’s the very reason we built the AI Center differently.
Unified Cross-Stack Investigation
AI Center isn’t a siloed tool, it’s integrated into your full observability stack.
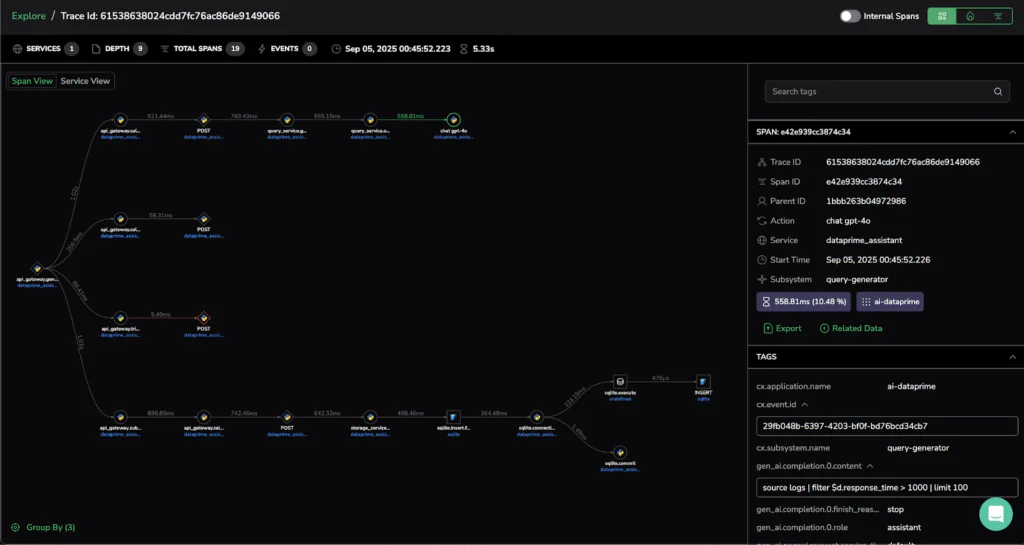
Here’s what debugging actually looks like:
AI Center: Eval scores show 15% hallucination rate
↓
APM Trace: Follow agent → retrieval → database → API
↓
Logs: See database queries returning empty results
↓
Metrics: Database CPU at 95%, query timeouts spiking
↓
Root Cause: Overloaded database → failed retrieval → hallucinations
↓
Fix: Scale database, add caching
↓
AI Center: Hallucination rate drops to 2%
One platform. One timeline. One investigation. No context-switching between tools.
Outcome: Fast, thorough investigations, without jumping between multiple observability platforms. No tool sprawls here!
Stop Compromising, Start Evaluating
You shouldn’t have to disable telemetry to control costs. You shouldn’t have to sample interactions to stay on budget. You shouldn’t have to choose between insight and performance.
And with Coralogix’s AI Center, you don’t have to!
The teams winning at production AI aren’t using better models. They’re using better evaluation strategies.
Traditional testing tells you if code works once.
Continuous evaluation tells you if your agent is reliable, safe, and improving over time.
Your agents are already in production or heading there soon. The question isn’t whether you need an evaluation strategy. It’s whether you’ll build it yourself or use a platform designed for it.
And trust me, after talking to dozens of teams shipping AI agents: you don’t want to build evaluators from scratch.
There’s a reason nobody’s open-sourcing them.Learn more about the AI Center here.





