

Building visibility and resilience across Kubernetes


Why Kubernetes Security and Monitoring Matter
Kubernetes has transformed how modern applications are deployed and scaled. Its flexibility and automation power innovation but also expand the attack surface. From control plane access to runtime drift, Kubernetes introduces layers of complexity that can obscure visibility if not properly monitored.
For security leaders, Kubernetes is both an opportunity and a risk. While it enables agility, it also decentralizes security responsibility across teams, tools, and cloud layers. Strong preventive controls like RBAC, Pod Security Standards, and NetworkPolicies reduce risk, but they’re only half the story. The real differentiator is continuous monitoring and observability: seeing what’s actually happening in real time.
In this blog, we’ll cover:
- The shared responsibility model between self-managed Kubernetes and managed Kubernetes services
- The key telemetry and log sources that drive visibility
- Real-world use cases and detection examples
- How to centralize observability for unified detection
Understanding Shared Responsibility
Just like database or cloud infrastructure monitoring, Kubernetes security begins with understanding who owns what. In a self-managed deployment, you’re responsible for the entire stack – from the control plane to worker nodes. In managed Kubernetes services (such as Amazon EKS, Azure AKS, or Google GKE), the cloud provider manages the control plane, but you remain accountable for workloads, nodes, networking, and observability.
| Layer | Self-Managed Kubernetes | Managed Kubernetes |
| Control Plane (API, etcd, scheduler) | You manage and secure | Cloud provider manages |
| Worker Nodes | You manage | You manage |
| Network & Access | You enforce policies and segmentation | You enforce policies and segmentation |
| Logging & Observability | You implement collectors | You enable and forward logs |
| Runtime & Workload Security | You protect workloads | You protect workloads |
Key takeaway: Cloud providers reduce operational overhead but do not eliminate your security responsibility. Visibility gaps often emerge when teams assume that managed services automatically log or secure everything – they don’t.
Securing Self-Managed Kubernetes
When you run your own Kubernetes clusters, you have full control – and full accountability.
This freedom brings flexibility but also the burden of securing every layer of the stack.
Best Practices
- Control Plane Protection: Restrict API server access, enforce mTLS, and patch frequently.
- Secrets Management: Encrypt secrets in etcd and use Sealed Secrets or Vault for sensitive data.
- Network Security: Apply NetworkPolicies to limit pod-to-pod communication and use mTLS.
- Runtime Defense: Employ runtime anomaly detection to flag abnormal container behavior.
- Audit & Compliance: Centralize audit logs for investigations and regulatory proof.
- Disaster Recovery: Automate etcd and persistent volume backups.
Because all components are under your control, log collection must be deliberate. Aggregate logs from:
- API server
- Authentication service
- Controller manager
- Scheduler
- Audit pipeline
A centralized observability solution allows correlation across these layers – essential for detecting malicious API calls or policy drift before it becomes an incident.
Securing Managed Kubernetes
Managed Kubernetes services simplify cluster management by outsourcing the control plane, but your workloads remain your responsibility. Cloud providers secure the API server, etcd, and certificates – yet customers must secure workloads, IAM/identity roles, node configurations, and observability.
Best Practices
- Cluster Configuration: Enable audit logging, restrict public API access, and prefer private endpoints.
- Access Control: Use cloud provider identity integration (IAM Roles for Service Accounts, Workload Identity, or Azure AD Pod Identity) with least privilege.
- Networking: Deploy clusters in private networks and enforce segmentation using security groups/firewall rules and NetworkPolicies.
- Node & Pod Security: Avoid privileged containers and host-level access.
- Observability: Forward API server, audit, and authenticator logs to your observability or SIEM platform.
- Image & Registry Security: Use trusted registries, scan images continuously, and block unverified builds.
- Backups & Updates: Automate snapshots and stay on the latest Kubernetes versions.
- Compliance Integration: Leverage cloud-native security services (GuardDuty, Security Center, Security Command Center) and audit trails for unified visibility.
Critical Telemetry: What to Monitor
Borrowing from database monitoring principles, Kubernetes monitoring also depends on ingesting the right signals.
Below are the foundational log sources that together provide a full picture of your cluster’s health and security posture.
| Log Source | Purpose | Key Insight |
| Cloud Audit Logs | Records cloud platform API calls | Detect IAM misuse or privilege escalation |
| kube-apiserver | Captures all Kubernetes API requests | Identify unauthorized or high-risk actions |
| Authentication Logs | Track successful and failed access attempts | Spot brute-force or credential replay |
| Audit Logs | Chronicle cluster changes | Trace who modified what, when |
| Controller Manager | Manage state reconciliations | Detect unauthorized scaling or misconfigurations |
| Scheduler Logs | Show pod placement logic | Identify anomalies or resource drift |
Example Threat Scenarios
- Unauthorized API Access: Unexpected DELETE /pods by a non-admin user.
- Privilege Escalation: IAM role elevation followed by RBAC modification.
- Data Exfiltration: Repeated GET /secrets requests with abnormal egress traffic.
- Runtime Abuse: Container spawns interactive shells or connects to external IPs.
- Policy Drift: NetworkPolicy deleted or replaced unexpectedly.
These are the same detection concepts database security teams apply to DML anomalies or privilege grants – but in Kubernetes, they span multiple telemetry sources.
Correlating Data: Real-World Use Cases
Like database monitoring, value emerges when you correlate events across systems.
Use Case 1: Identity Role Change + Kubernetes RoleBinding
A DevOps user assumes a new cloud identity role (cloud audit log) and immediately modifies an RBAC RoleBinding (Kubernetes audit log). This combination often signals privilege escalation.
Use Case 2: Suspicious Pod Execution
A container starts executing binaries not typically present in the image (runtime log), while the scheduler places it on an unusual node. This can indicate lateral movement or a compromised workload.
Use Case 3: Config Drift + Unauthorized Access
The controller manager logs show a new Deployment, while the API server logs multiple failed authentications from the same IP. Together, this may indicate automated exploitation or misused credentials.
Centralizing Observability
Fragmented logs are the biggest obstacle to Kubernetes security.
Control plane, identity, network, and runtime data often live in silos – making correlation difficult and delaying response.
Best Practices for Unified Visibility
- Ingest logs into a single platform – such as Coralogix.
- Correlate across layers: link Kubernetes audit data with cloud audit trails and runtime events.
- Visualize risk: build dashboards for RBAC changes, failed authentications, and abnormal API calls.
- Suppress noise: use baselines to filter expected patterns, highlighting only deviations.
Executive value: Centralized observability enables governance – turning logs into measurable assurance for compliance, resilience, and audit readiness.
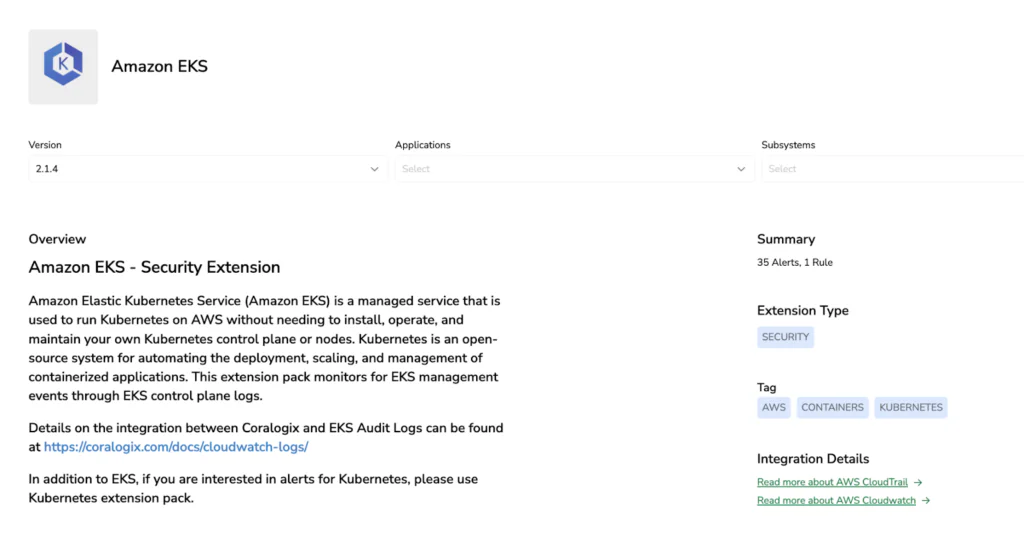
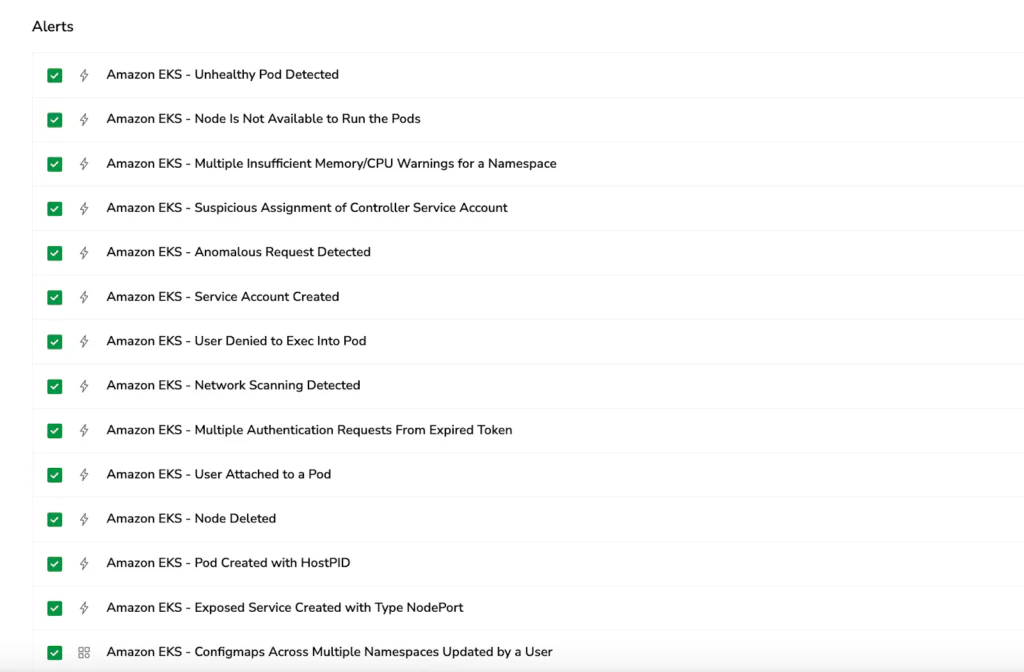
From Zero to Full Visibility: Coralogix Kubernetes Extension
The Coralogix Kubernetes extension delivers instant security monitoring with pre-built alerts for common threat scenarios and comprehensive dashboards that visualize your cluster’s security posture. No complex configuration required – start detecting anomalies and tracking compliance within minutes.

Conclusion
Kubernetes security isn’t just a technical checklist – it’s a visibility and governance challenge.
Self-managed clusters give full control but full accountability; managed Kubernetes services offload control plane operations but not responsibility. By aligning preventive controls, continuous monitoring, and centralized observability, organizations gain true operational resilience. For CISOs, that means shifting from reactive to proactive – transforming Kubernetes from a potential blind spot into a measurable pillar of enterprise security posture.


