
Introducing Dataspaces & Datasets


Govern, Organize, and Accelerate Your Observability Data
Observability data has a habit of outgrowing everything else. As telemetry volume, variety, and velocity increases, staying organized gets harder. Governance becomes messy, and the cost of digging through “everything” keeps rising.
Over the past year, Coralogix’s DataPrime engine has been addressing these challenges by laying a new foundation for observability at scale. That foundation is now live with Dataspaces and Datasets: a new architecture for organizing, governing, storing, and analyzing your telemetry and platform-usage events.
With this model, all data can be logically segmented to match your organization, by team, environment, region, or compliance domain, delivering clarity, control, and faster, more predictable analytics.
Why We Built Dataspaces and Datasets
Until now, observability data was funneled into broad buckets like logs and spans that are stored together inside one account-wide pool. That works fine early on, but at scale it creates friction:
- Everything lands in one place. It becomes difficult to isolate teams, environments, regions, or regulated domains.
- Governance is blunt. Overly broad retention, quota limits, and access policies mean organizations can’t enforce rules where they need to.
- Schemas collide. When many services share one dataset, data mappings fight each other and dashboards become fragile.
- Performance degrades. Even narrow questions require scanning huge volumes, slowing investigations and driving up storage query costs.
- System data needs separation. Audit logs and query history are valuable, but historically lived in separate accounts to avoid pollution and protect access.
- Customers created extra teams just for segmentation. Not because they wanted to, but because they had to.
As organizations scale, these small problems turn into monsters. Dataspaces and Datasets now address these limitations directly: they enable logical data segmentation within an account, letting teams isolate data based on the boundaries that matter to them.

Two New Core Concepts
Dataspaces: The Container
A Dataspace is the top-level container for data in Coralogix. Like a database that contains tables, a Dataspace groups Datasets under a set of policies and settings it instantiates for them like:
- Storage destination (S3 bucket or customer-defined bucket)
- Retention
- Access permissions (RBAC + PBAC)
- Quotas and limits
- Cost allocation boundaries
Every Dataset inside a Dataspace inherits these defaults automatically. That keeps governance consistent, reduces misconfiguration, and ensures new datasets are compliant. You can model Dataspaces however you like: production vs. staging, security vs. engineering, EU vs. US residency, or by product line.
Dataspaces are storage-aware. If you change a dataset’s bucket or region, DataPrime continues to query seamlessly across both old and new locations with no historical data migration required.
Datasets: The Data
Datasets are tightly scoped collections of events inside Dataspaces: think “database table.” Each dataset has its own schema, and is stored as Parquet partitions in your archive storage. Datasets can represent:
- Logs from a specific application or subsystem
- Traces from a specific service
- Data for a region (for example, $D.region)
- A department or team (security, backend, frontend)
- Any custom grouping defined through a DataPrime Expression Language (DPXL) rule
Datasets can be created manually, dynamically, or via routing rules. They can even write to their own dedicated bucket when needed for advanced multi-bucket architectures.
Datasets deliver both clarity and performance. Because Datasets are smaller and purpose-built, DataPrime scans fewer Parquet files. That means fewer S3 requests, lower compute overhead, and noticeably faster results.
Benefits at a Glance
Dataspaces and Datasets deliver four immediate wins.
Clear data ownership
Each team or function gets a clean, isolated data domain inside one account. No more juggling multiple Coralogix teams just to separate environments or departments. Independent schemas reduce noise and mapping collisions, so dashboards stay reliable.
Governance and compliance in the foundation
You can set access, retention, and quota boundaries where they actually matter — per Dataspace or dataset. That simplifies audits, prevents accidental exposure, and makes ownership explicit.
Faster, more efficient analytics
Instead of scanning one massive pool, DataPrime targets smaller datasets. Expect faster queries, fewer storage calls, and a smoother Explore and dashboard experience.
Granular cost visibility and control
Usage and quota assignment work at both Dataspace and Dataset levels, enabling true cost allocation by domain. System dataset usage also appears in Data Usage, giving admins a full view of both operational and user-driven activity.
Built-In Foundations: Default and System Dataspaces
To make the model feel natural on day one, every account includes two built-in Dataspaces: Default and System.
The Default Dataspace: your ingested data
The Default Dataspace is the familiar home for what you send to Coralogix. It includes:
- logs
- spans
From a query perspective, nothing changes. When you run: source logs DataPrime automatically targets source default/logs (the logs dataset inside the Default Dataspace). Same for spans.
The System Dataspace: data about your account
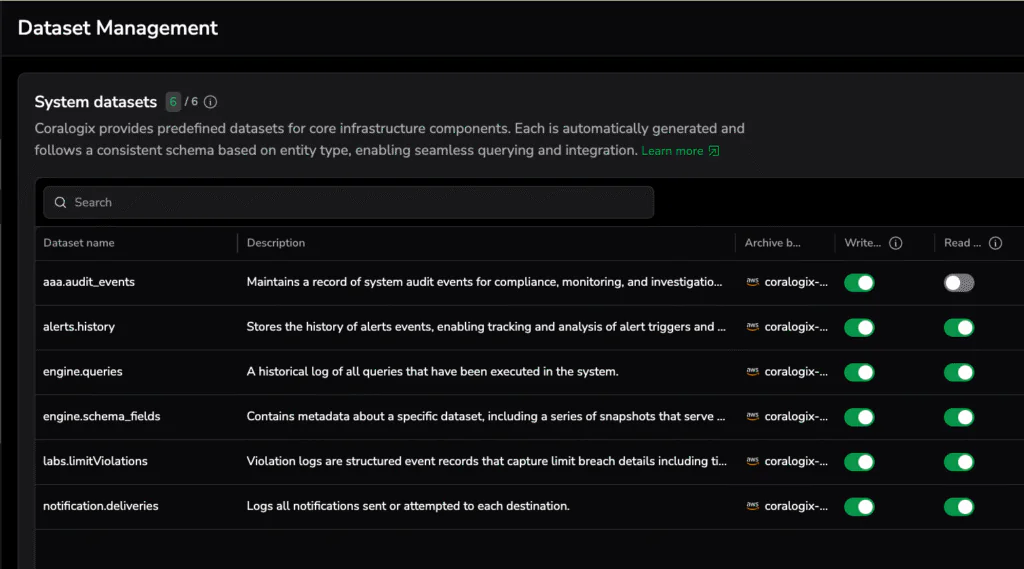
The System Dataspace holds Coralogix-generated datasets that describe activity in your account. In the past, audit logs and similar data lived in a separate “audit account” to avoid quota impact and keep access tight. Useful, but clunky. Now this data is available directly in your account, still isolated from production telemetry. System datasets that you can enable and start collecting include:
- aaa.audit_events
A full record of account audit activity for compliance and investigation. - engine.queries
A historical log of every Explore/API/dashboard query, including performance and execution context. - alerts.history
The complete lifecycle of triggered alerts, acknowledging, and resolution flow. - notification.deliveries
Delivery logs for Notification Center destinations (email, PagerDuty, Slack, etc.). - engine.schema_fields
Schema evolution and field-tracking over time. - labs.limitViolations
Structured events capturing quota or limit breaches.
More System Datasets will keep rolling out regularly. Once enabled, system datasets can be used just like your own telemetry sources to power Explore investigations, dashboards, and alerting on account activity:
In practice, admins can now self-serve what used to require support exports: adoption trends, heavy queries, audit reviews, delivery validation, and schema drift, all without leaving the account.
Example: Understand how teams use Coralogix with engine.queries
After enabling the engine.queries dataset in the System Dataspace, every query executed in your account becomes observable. Each record tells you where the query originated inside Coralogix, whether it came from Explore Logs, dashboards, the public API, sidebar statistics, filters, or other internal system calls.
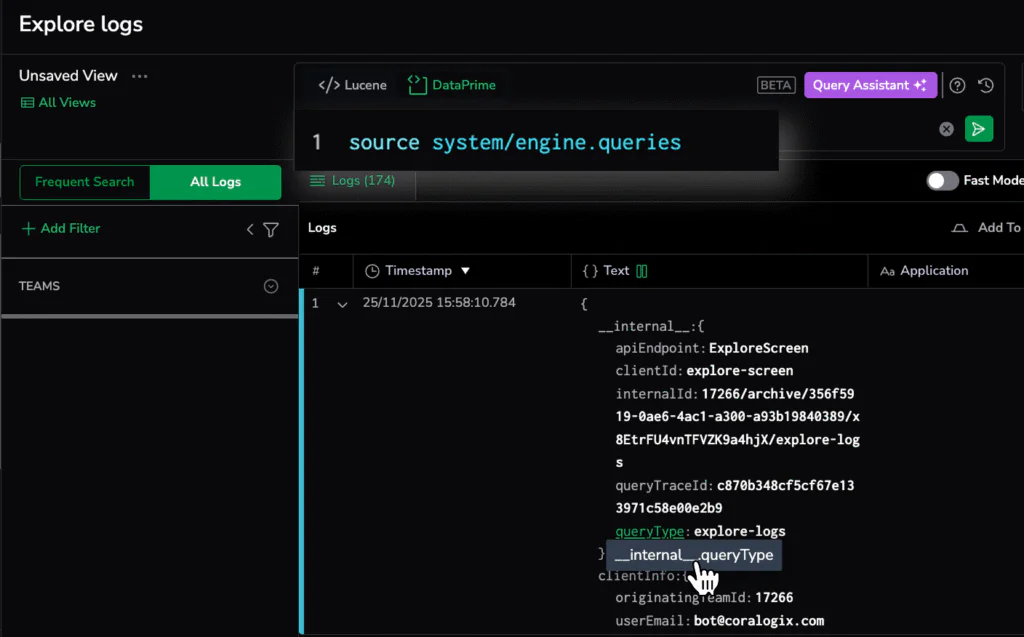
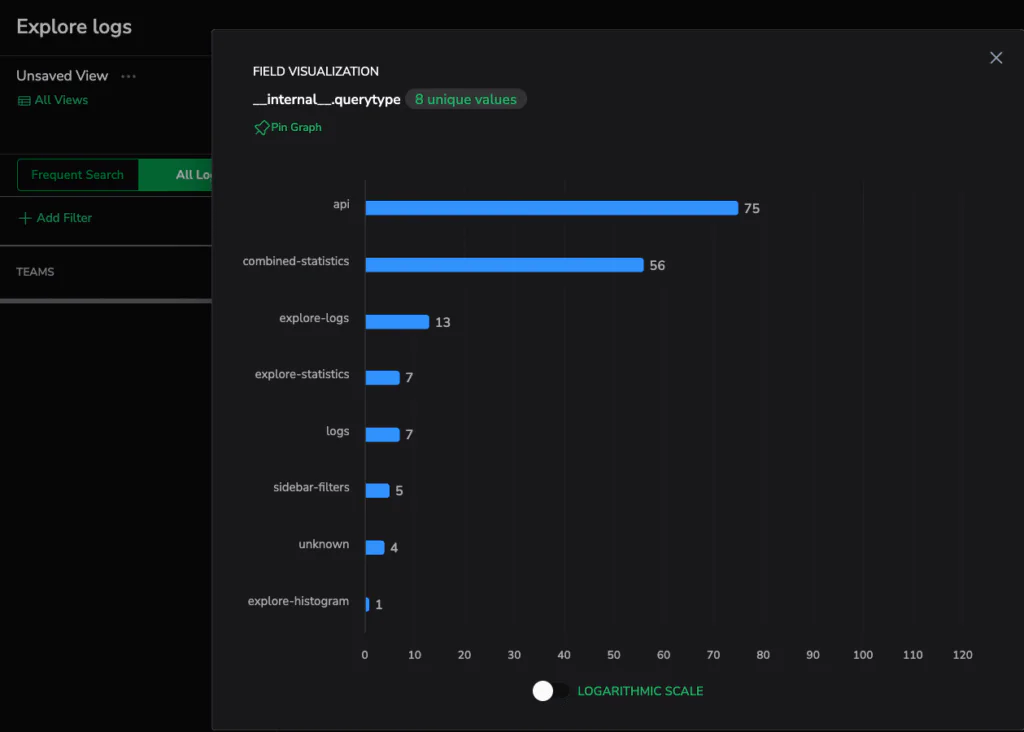
Break down queries by their origin to see which Coralogix experiences drive usage.
This gives admins a simple way to understand real platform usage:
- What screens are most used across the org?
- Are certain teams under-adopting the platform?
- Which dashboards or Explore workflows generate the heaviest queries?
- Are long or inefficient queries coming from a specific UI surface or API client?
Background Query Results as Datasets (Reusable Summaries)
Datasets aren’t only for raw telemetry. They’re also the future of background queries and large-scale aggregation.
Today, Background Queries let you preview results and download TSV. With Dataspaces and Datasets, Background Query results can be saved as first-class Datasets, with long-term retention and full DataPrime access. In the coming weeks, full Background Query workflows, including writeTo and scheduling , will roll out to make this native, automatic, and repeatable. This means you’ll be able to:
- Run a query once and save the results as a Dataset
so transformed data becomes queryable like any other source. - Jump straight from results into Explore or dashboards
to continue analysis without downloading anything - Schedule background queries to continuously build summary datasets
enabling long-term trend analysis without scanning months or years of raw data. - Store results for as long as needed
with retention controlled by the destination Dataspace/Dataset policies.
This unlocks long-term, pre-aggregated analysis (similar to Splunk Summary Indexing) without re-scanning years of raw data. In short: generate once, reuse forever — with full governance baked in.
User-Defined Dataspaces & Datasets: Model Your Data Like Your Organization
The most powerful part of this architecture is what happens when you define the structure yourself.
Instead of Coralogix forcing a single universal layout, you’ll be able to design your data foundation around real organizational boundaries. Segment by team, product line, environment, region, or compliance zone. Each domain gets its own governed home, schema, limits, and access rules, all inside one account.
Admins will be able to:
- Create Dataspaces for teams, environments, products, regions, or compliance zones
- Add Datasets under each Dataspace for a single entity type (logs or spans)
- Route data into Datasets manually or dynamically using DPXL
(e.g., route by $d.team, $d.environment, $d.region, or any field) - Apply PBAC access policies per Dataspace/Dataset
so only the right groups can read or manage sensitive domains - Assign quotas and retention at both the Dataspace and Dataset level
preventing accidental floods and enabling cost boundaries by domain - Choose whether data lives in one Dataset or fans out into several
(for example, keep auth logs in production and route a copy into security)
Two quick examples:
One-account enterprise model
A large organization can replace a maze of Coralogix teams with a single account, using Dataspaces to isolate production, staging, security, and regional domains. Each space carries the right retention, quotas, and access policies, while users still query across spaces when needed.

Security fan-out without duplication
Keep all logs routed to production datasets, but fan-out only authentication and access logs into a security Dataspace. Security teams get clean, isolated visibility without storing every event twice.
User-defined Dataspaces and Datasets are the next major expansion of this foundation, and will be rolling out over the coming months.
What This Means for You
Dataspaces and Datasets are a foundational leap: they extend DataPrime beyond querying into data governance, control, and lifecycle management that scales with you:
- Clarity through logical ownership
- Compliance-ready governance
- Faster analytics on smaller scopes
- Cost control and allocation by domain
- One unified account instead of many
If you want help designing a Dataspace/Dataset strategy—routing rules, organizational boundaries, or governance models—reach out to your Coralogix team. We’re excited to see how you reshape observability at scale with this new foundation.
Welcome to a cleaner, faster, governed Coralogix.
See it live at AWS re:Invent
Come see DataPrime in action and experience how Coralogix is redefining modern observability. Visit us at booth #1739 at AWS re:Invent.


