 The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 
Network Security: The Journey from Chewiness to Zero Trust Networking

Network security has changed a lot over the years, it had to. From wide open infrastructures to tightly controlled environments, the standard practices of network security have grown more and more sophisticated.
This post will take us back in time to look at the journey that a typical network has been on over the past 15+ years. From a wide open, “chewy” network, all the way to zero trust networking.
Let’s get started.
Network Security in the Beginning…
Let’s say we work at a company that’s running a simple three-tiered web architecture. We have a frontend service, a backend service, and a database. It’s 2005, and we run each of our services and the database on a separate machine.
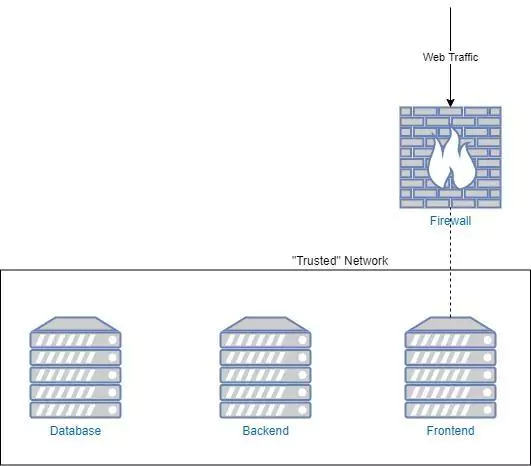
The Problem? Our Network is Wide Open to Attack
An attacker gaining any sort of access to our network will be able to move throughout the entire network, exfiltrating data and causing havoc. Basically, our network is wide open to attack. Luckily for us, the fix is quite straightforward. At least, for now.
So, We Introduce Network Segmentation
Word reaches us about the new and improved security best practices, and we segment our network based on the “least privilege” principle.
The Principle of Least Privilege
The principle of “least privilege” has become a staple of security thinking over the years. Its arguments are common sense. A service should have only the permissions that it needs to complete its function and nothing more. This sounds obvious, but from an engineering perspective, it is often easier to give something wide powers. This helps to avoid the need to revisit application permissions for every new feature change.
From a networking perspective, the principle of least privilege argues that each server should only have the permissions and network access that it needs to run. Simple, right?
Applying the Principle of Least Privilege to our Network Security
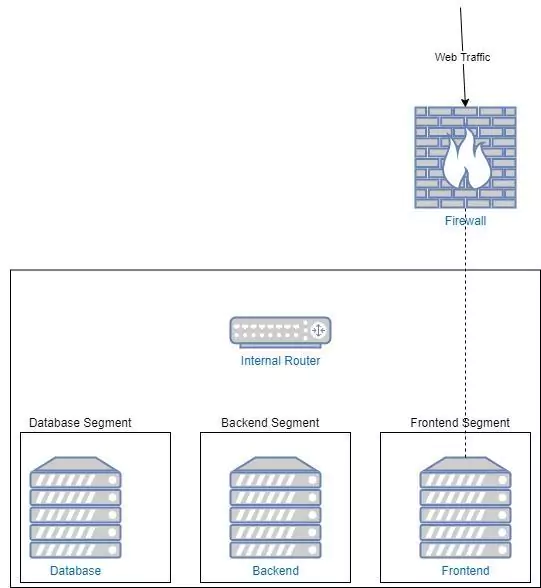
We split each of our servers into its own network. This router makes sure that services can only communicate with their appropriate databases. This is important. It means that if an attacker manages to compromise one of the backend segments, they can not laterally move to the other segments. They can only visit the nodes that we have allowed. This limits the blast radius of an attack and makes for a much more difficult system to hack.
The Problem? Scale!
If we need to add any servers, or run additional services on these servers, the number of rules grows very quickly, as each rule needs to be duplicated by the number of machines. This poses a bit of an issue for us, but as long as the server count remains low, we should be alright.
Unfortunately, over the past few years, architectural patterns like microservices have massively increased the number of virtual machines that we use. This increase makes this model far less viable, but we’ll get to that.
Moving to the Cloud
Our company, being savvy and technologically forward-thinking, decides to move to an early cloud offering.
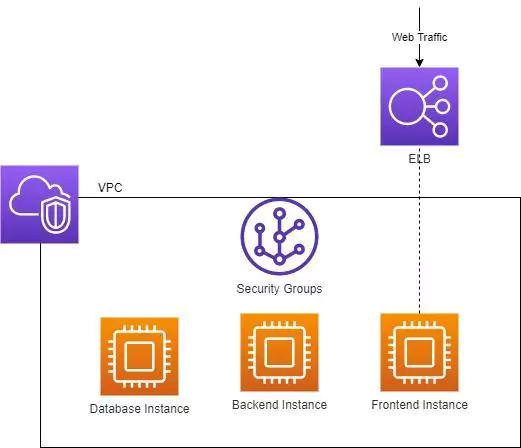
So far, so good! We’ve taken the lessons of our physical network segmentation and applied them here. Our instances are segmented from each other using security groups, which are basically firewall rules enforced by a virtual appliance.
Our new infrastructure enables our company to handle more traffic and, ultimately, make more money. Soon, however, even our shiny cloud infrastructure needs some work.
Introducing the Cluster
To deal with scale, our company containerizes its services. The services move to a managed Kubernetes cluster, and the database moves to a managed cloud database.
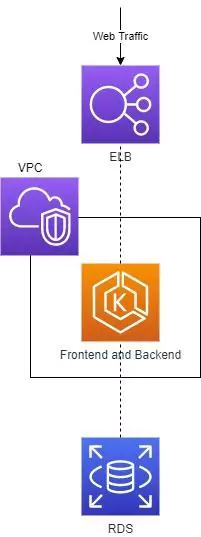
Very clean and elegant! (Yes, it’s oversimplified, but bear with me). Our services are now managed and leveraging auto-scale.
The Problem? Still, Scale…
Our previous network setup relied on some pretty basic assumptions. We had a “Database server” and that server would host our database. We had a “Backend Server” and we could rely, 100% of the time, on our backend server hosting our backend application.
Now, however, there are no dedicated server roles. We find ourselves in a completely different paradigm. Our servers are simply agnostic hosts of docker containers and don’t know a great deal about the internals of these containers. So how do we set up rules to ensure a principle of least privilege?
The Solution? An Entirely New Approach
Before, we were thinking about servers in terms of their networking identity. For example, an IP address. This was adequate, but there is no longer a consistent mapping between IP address and service. We need to stop identifying services by some proxy variable, such as IP, and start identifying services directly. How do we do that, and how do we manage relationships between these identities?
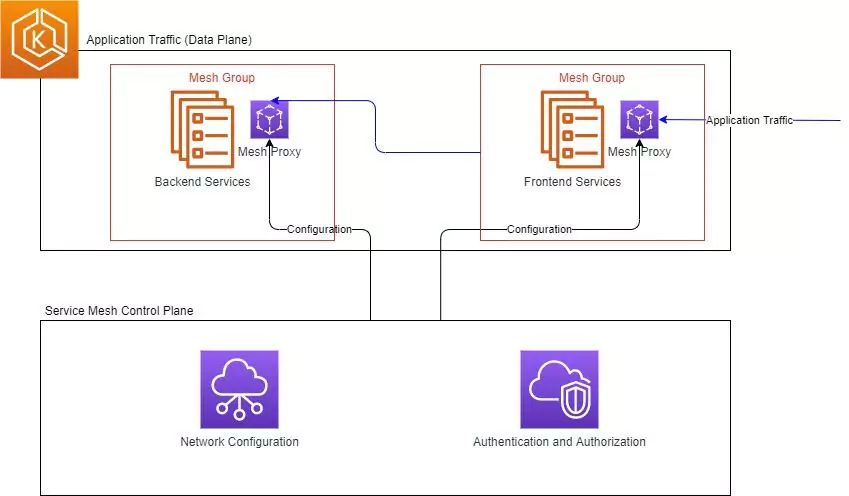
The Service Mesh
A service mesh is a relatively new entry into the networking scene. It operates at a much higher level than traditional networking does. Rather than worrying about the underlying switches, routes and such, it registers itself with each application in your system and processes rules about application to application communication. The service mesh has some specific differences from a traditional set up that must be understood.
Intention-Based Security
Intention-based security refers to a style of declaring security rules. Rather than having obscure networking rules that directly configure underlying switches, we declare the intention of each service, at the service level. For example, Service A wishes to communicate with Service B.
This abstracts the underlying server and means that we no longer have to rely on assumptions about IP addresses. We can declare our intentions directly.
The Mesh Proxy (Sometimes Called Sidecar)
The service mesh is made up of a control plane and a network of proxies. The control plane configures the proxies, based on the intentions declared by the user. The proxies then intercept all traffic moving in and out of the service and, if the rules apply, will transform, reroute or block the traffic entirely. This network of proxies makes up the service mesh.
The Problem? Risk of System Disruptions
The most obvious drawback of this architecture is that there are many, many proxies. At least one per service. This means that a single broken proxy can disrupt all traffic for a service. We need to be able to monitor the health and configuration for each of these proxies, otherwise we will quickly lose the ability to track down problems.
The Solution? A Powerful Observability Platform
Observability is the answer here. You need a powerful platform, through which you can interrogate your infrastructure. You can find out about memory, CPU and networking status of your proxies and services, and ensure that your entire service mesh is running optimally.
Coralogix provides world class observability and regularly processes over 500,000 events, every second. If you need to level up your insights and gain new control over your system, check out how we can help.
Our Journey
We began with simple networking rules that blocked traffic from server to server. As we can see, the arms race between security and sophisticated software techniques continues. We have arrived at a point where we can directly declare services, by their human readable names, and control traffic through a network of distributed proxies.
Wherever you find yourself on this journey, the most exciting thing is that there is always somewhere new to go!


