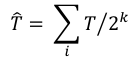The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

AI-powered platforms like Coralogix also have built-in technology that determines your enterprise monitoring system‘s “baseline” and reports anomalies that are difficult to identify in real-time. When combined with comprehensive vulnerability scans, these platforms provide you with a robust security system for your company.
Picture this: Your on-call engineer gets an alert at 2 AM about a system outage, which requires the entire team to work hours into the night.
Even worse, your engineering team has no context of where the issue lies because your systems are too distributed. Solving the problem requires them to have data from resources that live in another timezone and aren’t responsive.
All the while, your customers cannot access or interact with your application, which, as you can imagine, is damaging.
This hypothetical situation happens way too often in software companies. And that’s precisely the problem that application performance log monitoring solves. It enables your team to quickly get to the root cause of any issues, remediate them quickly, and maintain a high level of service for the end-users. So, let’s first understand how application performance monitoring works.
What is Application Performance Monitoring?
Application performance monitoring refers to collecting data and metrics on your application and the underlying infrastructure to determine overall system health. Typically, APM tools collect metrics such as transaction times, resource consumption, transaction volumes, error rates, and system responses. This data is derived from various sources such as log files, real-time application monitoring, and predictive analysis based on logs.
As a continuous, intelligent process, APM uses this data to detect anomalies in real-time. Then, it sends alerts to the response teams, who can then fix the issue before it becomes a serious outage.
APM has become a crucial part of many organizations, especially those with customer-facing applications. Let’s dive into how implementing an APM might benefit your organization.
Why is application performance monitoring important?
System Observability
Observability is a critical concept in software development as it helps cross-functional teams analyze and understand complex systems and the state of each component in that system. In addition, it allows engineers to actively monitor how the application behaves in production and find any shortcomings.
Application performance monitoring is a core element of observability. Using an APM like Coralogix, you contextualize data and seamlessly correlate them with system metrics. Thus, the exact systems acting up can be isolated by software. This translates to a lower mean time to detect and resolve incidents and defects.
Furthermore, Coralogix’s centralized dashboard and live real-time reporting help you achieve end-to-end coverage for your applications and develop a proactive approach to managing incidents. Cross-functional teams can effectively collaborate to evolve the application through seamless visualization of log data and enterprise-grade security practices for compliance.
Being cross-functional is especially important as your organization grows, which brings us to the next point.
Scaling Your Business
Scaling your organization brings its set of growing pains. Systems become more complicated, architectures become distributed, and at one point, you can hardly keep track of your data sources. Along with that, there is an increased pressure to keep up release velocity and maintain quality. In cases such as these, it’s easy to miss tracking points of failures manually or even with in-house tracking software. Homegrown solutions don’t always scale well and have rigid limitations.
With Coralogix, you can reduce the overhead of maintaining different systems and visualize data through a single dashboard. In addition, advanced filtering systems and ML-powered analytics systems cut down the noise that inevitably comes with scaling, allowing you to focus on the issue at hand.
Business Continuity
You’re not alone if you’ve ever been woken up in the middle of the night because your application server is down. Time is crucial when a system fails, and application performance monitoring is critical in such cases.
24/7 monitoring and predictive analysis often help curb the negative impacts of an outage. In many cases, good APM software can prevent outages as well. With time, intelligent APM software iterates and improves system baselines and can predict anomalies more accurately. This leads to fewer and shorter outages, complete business continuity, and minimal impact on the end users. Speaking of end users…
Team Productivity
We want to fix defects – said no developer ever. With log data and monitoring, engineering teams can pinpoint the problem that caused the defect and fix it quickly. Your software teams would thus have fewer headaches and late nights. This leads to improved team morale, freeing up their time to innovate or create new features for the application instead. Tracking automation software like RPA and custom scripts is also a great use case for APMs that directly increase productivity.
Customer Experience
End users want applications to be fast, responsive, and reliable across all devices, be it their phone, tablet, laptop, etc. Your website doesn’t even have to be down for them to form a negative impression — they will switch over to a competitor if your website doesn’t load within seconds.
Systems rarely fail without giving some kind of indication first. With APM, you can track these issues in real-time. For instance, you could set up alerts to trigger when a webpage becomes non-responsive. Higher traffic load or router issues can also be monitored. Combined with detailed monitoring data through application and Cloudflare logs, your team can then jump in before the end user’s experience is disrupted.
Along with user experience, application performance monitoring software also plays a crucial role in cybersecurity. No matter the size of your organization, hackers actively look for security loopholes to breach sensitive data. Here’s how APM helps deal with that.
Reduce Cybersecurity Risk
Hackers are everywhere. Although a good firewall, VPNs, and other cybersecurity measures help block a lot of unwanted traffic, sophisticated attacks can sometimes still breach that level of security. With cybersecurity hacks sometimes resulting in millions of dollars in losses for a business, APM software can be the solution you need to be cyber secure.
By monitoring your applications constantly and looking at usage patterns, you’ll be able to identify these intrusions as they happen. Threshold levels can trigger alerts when the system detects unusual activity through traces. Thus, this can function as an early warning system, especially during DDoS attacks. APMs can also be used to track authentication applications to ensure they are keeping APIs functional while keeping the hackers at bay.