
Elasticsearch: The Basics and a Quick Tutorial


Elasticsearch Architecture and Components
Elasticsearch’s architecture is designed around a few core concepts: nodes, clusters, indices and types, documents and fields, and shards and replicas.
Nodes
In Elasticsearch, a node is a running instance of the software. Each node in the Elasticsearch cluster has a unique identifier and a role (or roles), such as a data node, master node, or ingest node. Each of these roles defines the responsibilities and tasks of the node within the cluster.
Data nodes store the data and participate in the cluster’s indexing and search capabilities, while master nodes are responsible for cluster-wide actions like creating or deleting an index, tracking nodes, and deciding which shards to allocate to which nodes. Ingest nodes are used for pre-processing documents before indexing.
Clusters
A cluster, in Elasticsearch terminology, is a collection of one or more nodes that together hold all your data and provide federated indexing and search capabilities across all nodes. A cluster is identified by a unique name, which by default is “elasticsearch.”
If your cluster consists of multiple nodes, Elasticsearch automatically elects one of the nodes as a master node. The master node controls the overall operations of the cluster. Clustering allows Elasticsearch to scale out to hundreds of nodes and handle petabytes of data.
Indices
Indices are a way to logically divide your data. An index in Elasticsearch is similar to a database in the realm of relational databases. Each index has a name that is used as a reference while performing indexing, searching, updating, and deleting operations against the documents stored in it.
In older versions of Elasticsearch, there was the concept of Types, which were logical categories of your data within an index. But with recent updates, Types have been deprecated, and it is recommended to use a separate index for each type of data.
Documents and Fields
In Elasticsearch, a document is a basic unit of information that can be indexed. It’s expressed in JSON, which is a ubiquitous internet data interchange format. Each document is a collection of fields, which are the key-value pairs that contain your data. The keys are strings, and the values can be various types such as text, numeric, boolean, and date.
Fields are the smallest individual unit of data in Elasticsearch. Each field represents a specific type of data, such as a string, date, or array. Fields are indexed in a way that facilitates quick retrieval, making them suitable for search operations.
Shards and Replicas
Sharding is a feature of Elasticsearch that sets it apart from many other search engines. An index can potentially store a large amount of data, which can exceed the hardware limits of a single node. To solve this problem, Elasticsearch can subdivide your index into multiple pieces called shards.
A replica is a copy of a shard. Replicas provide redundancy and high availability and are crucial for disaster recovery. They also allow you to scale out your search volume since searches can be executed on all replicas in parallel.
Elasticsearch Benefits
Let’s look at some of the advantages of using Elasticsearch.
High Performance
Elasticsearch offers high performance, primarily due to its distributed nature and the ability to perform complex queries in near-real time. With Elasticsearch, you can store, search, and analyze large volumes of data quickly (usually in milliseconds), which makes it useful for time-sensitive tasks.
It’s also capable of handling petabytes of data while still ensuring optimum performance. The platform’s speed and scalability are powered by an inverted index data structure, based on Apache Lucene, a high-performance text search engine library. This combination of speed, scalability, and the ability to index many types of content means that Elasticsearch can handle use cases ranging from real-time data analytics to business intelligence.
Near-Real Time Operations
Fast operations are crucial for applications where you need to analyze and visualize data as it comes in, like application performance monitoring, security event management, or real-time business analytics.
Elasticsearch achieves this with a refresh mechanism that makes newly indexed data searchable almost immediately (usually in one second). This allows for real-time interaction with your data.
Complimentary Tooling and Plugins
Another significant benefit of Elasticsearch is the ecosystem of complementary tools and plugins that surround it. These tools make it more powerful and easier to use. Kibana, for example, is a visualization tool that allows you to create dashboards presenting your data stored in Elasticsearch. It provides advanced data analysis and helps you to understand complex data insights by visualizing your data in various types of charts, tables, and maps.
There are also various plugins available for Elasticsearch that extend its capabilities. For instance, plugins for language analysis add more languages to Elasticsearch. Others provide new ways of processing and analyzing your data. This ecosystem of tools and plugins means that Elasticsearch can be easily tailored to the needs of your project.
Easy Application Development
Elasticsearch also makes application development easier. Its RESTful API and JSON data format make building applications in multiple programming languages simple. There’s a range of client libraries for languages like Java, Python, .NET, and SQL.
Built-in features like data sharding and replication help to manage data growth and ensure resilience. Elasticsearch also supports complex queries, allowing you to filter and rank results by multiple criteria. This makes it suitable for building complex, data-driven applications.
Elasticsearch Use Cases
There are several ways that Elasticsearch can be used, including to manage application performance, security, and searches.
Enterprise Search
Elasticsearch is commonly used for enterprise search. This involves creating a searchable index of an organization’s data, whether in documents, emails, databases, or something else.
Elasticsearch can index many types of content and perform complex searches. It allows you to create a search experience that is tailored to your needs, whether that’s a simple text search, a search-by-image feature, or a voice-activated search. Its relevance scoring and full-text search capabilities allow for accurate and efficient searches, improving productivity within an organization.
Application Performance Management
Elasticsearch’s ability to handle large volumes of data makes it useful for application performance management (APM). APM is the process of monitoring and managing the performance and availability of software applications.
Elasticsearch is used in APM to collect, index, and analyze performance data in real-time. This lets you quickly identify performance issues and anomalies, understand their impact, and act before they affect users. APM tools like Elastic APM use Elasticsearch to store APM data and Kibana to visualize it.
SIEM
Security information and event management (SIEM) is another popular use case for Elasticsearch. SIEM tools collect and analyze security data across an organization’s IT environment.
Elasticsearch’s real-time analysis capabilities are crucial for SIEM. They enable security teams to quickly detect and respond to security incidents, minimizing their impact. The ability to perform complex queries allows for advanced threat hunting and anomaly detection.
Quick Tutorial: Getting Started with Elasticsearch
Installing Elasticsearch
Elasticsearch is compatible with multiple operating systems including Windows, Linux, and MacOS. The installation process varies depending on your operating system.
To install Elasticsearch, follow these steps:
- Download the Elasticsearch distribution from the official website. Choose the version that matches your system.
- Extract the files to your desired location.
- To verify the installation, open a command prompt or terminal window, navigate to the bin directory inside your Elasticsearch installation, and run the command ./elasticsearch (for Linux/Mac) or elasticsearch.bat (for Windows).
The Elasticsearch server should start, and you can interact with it through the RESTful API using the default port (9200).
Configuring Elasticsearch
After installing Elasticsearch, you need to configure it to suit your needs. The main configuration file for Elasticsearch is the elasticsearch.yml file, located in the config directory of your Elasticsearch installation.
The elasticsearch.yml file is written in YAML format, and it contains settings that control most aspects of Elasticsearch’s behavior. On Ubuntu the default path is /etc/elasticsearch/. Here are some of the key settings you might want to configure:
- cluster.name: The name of your Elasticsearch cluster. This is important if you’re running multiple Elasticsearch clusters in the same network, as it allows them to discover each other and prevent data leakage.
- node.name: The name of the current node. This is displayed in the logs and the API responses.
- network.host: The network interface that Elasticsearch binds to. This is usually set to localhost for development and to the specific IP of your server for production.
- http.port: The HTTP port that Elasticsearch listens on. The default is 9200.
After making changes to the elasticsearch.yml file, you need to restart Elasticsearch for the changes to take effect.
Note: If you get the message error: curl: (52) Empty from the server, turn off security in elasticsearch.yml by setting xpack.security.enabled: false. This is not recommended for production environments.
Running Elasticsearch
You can run Elasticsearch from the command line by navigating to the bin directory of your Elasticsearch installation and running the ./elasticsearch or elasticsearch.bat command, depending on your system.
Elasticsearch runs as a standalone server in your system, and it listens for RESTful requests on port 9200 by default. You can interact with Elasticsearch through this API using any HTTP client, such as curl or Postman, or you can use one of the many client libraries available for different programming languages.
When Elasticsearch is running, you can send commands to perform various actions, such as creating an index, adding documents, searching for documents, etc.
Creating an Elasticsearch Index
An index in Elasticsearch is similar to a database in a traditional relational database system. It’s a place where you can store and retrieve documents. To create an index in Elasticsearch, you can use the PUT method of the RESTful API.
For example, to create an index named “my_index,” you would send a PUT request to http://localhost:9200/my_index. The request might look something like this:
curl -X PUT "localhost:9200/my_index" -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_shards" : 1,
"number_of_replicas" : 1
}
}'
The output should look like this:
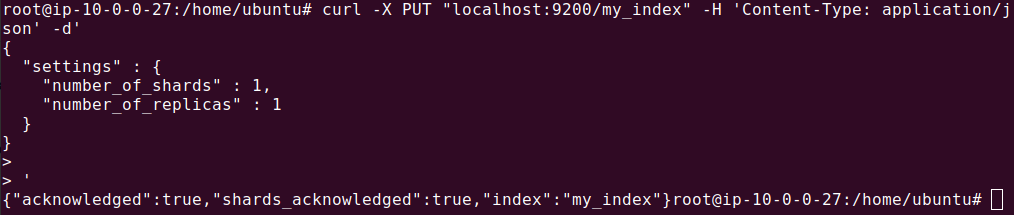
The response from Elasticsearch should confirm that the index has been created.
Once you’ve created an index, you can add documents to it. A document in Elasticsearch is a basic unit of information that can be indexed. It’s expressed in JSON format and consists of fields, which are the keys and values that make up the data.
Documents can be indexed using a POST or PUT request. Here’s an example of how to add a document to the my_index index:
curl -X POST "localhost:9200/my_index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Elasticsearch Basics",
"description": "Introduction to Elasticsearch",
"date": "2023-01-01"
}
'
The output should look like this:

This example indexes a document with a title, description, and date into my_index.
Elasticsearch Querying
Querying allows you to search for documents in your indices using a flexible and expressive query language. There are two types of queries in Elasticsearch:
- The Query DSL is a rich, flexible, and expressive query language that allows you to define complex queries using JSON. It supports a wide range of search options, including full-text search, phrase matching, range matching, and boolean logic.
- The Simple Query String is a simpler query language that’s easier to use but less powerful. It’s designed for ad-hoc queries and user input, and it supports a limited set of search options.
To perform a search, you can use the GET method of the RESTful API and specify the index you want to search in the URL. For example, to search for all documents in the my_index index, you would send a GET request to http://localhost:9200/my_index/_search.
Here is how to use the Query DSL to execute a simple search query:
curl -X GET "localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"description": "Elasticsearch"
}
}
}
'
The output should look like this:
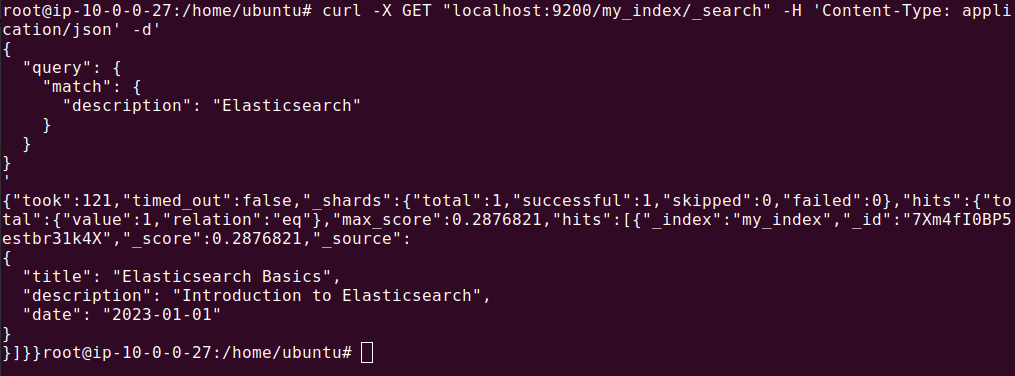
This query searches for documents in my_index where the description field contains the word “Elasticsearch.” For a more complex query, such as a boolean query combining multiple search criteria, you could use:
curl -X GET "localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Elasticsearch" }},
{ "match": { "description": "Introduction" }}
],
"filter": [
{ "range": { "date": { "gte": "2024-01-01" }}}
]
}
}
}
'
The output should look like this:
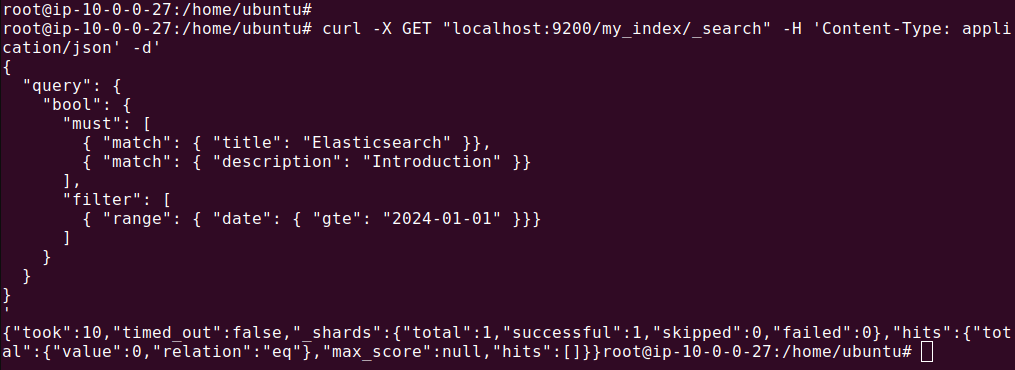
This query looks for documents where the title field contains the word “Elasticsearch” and the description field contains the word “Introduction,” and the date field is on or after “2024-01-01.”
Learn more in our detailed guide to Elasticsearch query examples

