

OpenSearch Serverless: How It Works and Getting Started in 3 Steps


Primary Use Cases for OpenSearch Serverless
OpenSearch Serverless can be used for the following tasks.
Log Analytics
Amazon OpenSearch Serverless is designed to handle log analytics efficiently. This includes collecting, monitoring, and analyzing system and application logs at scale. By leveraging serverless technology, it automatically scales according to the volume of data, managing changing workloads without the need for manual intervention.
Organizations can ingest logs directly from various sources like AWS CloudTrail, Amazon VPC Flow Logs, and custom application logs. This process simplifies the management and analysis of large volumes of log data.
Full-Text Search
OpenSearch Serverless supports full-text search capabilities, allowing businesses to easily implement search functionality within their applications or websites. It enables complex search queries, including fuzzy matching, auto-completion, and synonym searching.
The serverless nature of the service ensures that it scales automatically to handle growth in data volumes without manual scaling or management. This feature significantly reduces the operational burden and costs associated with managing a large-scale search infrastructure.
How Amazon OpenSearch Serverless Works
Separating Ingest from Query Operations
Amazon OpenSearch Serverless utilizes a cloud-native architecture that differs from traditional OpenSearch clusters. In traditional setups, a single cluster of instances is responsible for both indexing data and performing search queries, with the data storage closely tied to the compute resources. This configuration can lead to inefficiencies, especially as the volume of data and the number of queries grow.
OpenSearch Serverless separates these functions into distinct components. The indexing (ingest) process is decoupled from the search (query) operations, with Amazon S3 serving as the primary storage repository for indexes. This separation allows each component to scale independently based on its specific needs, ensuring that resources are utilized efficiently.
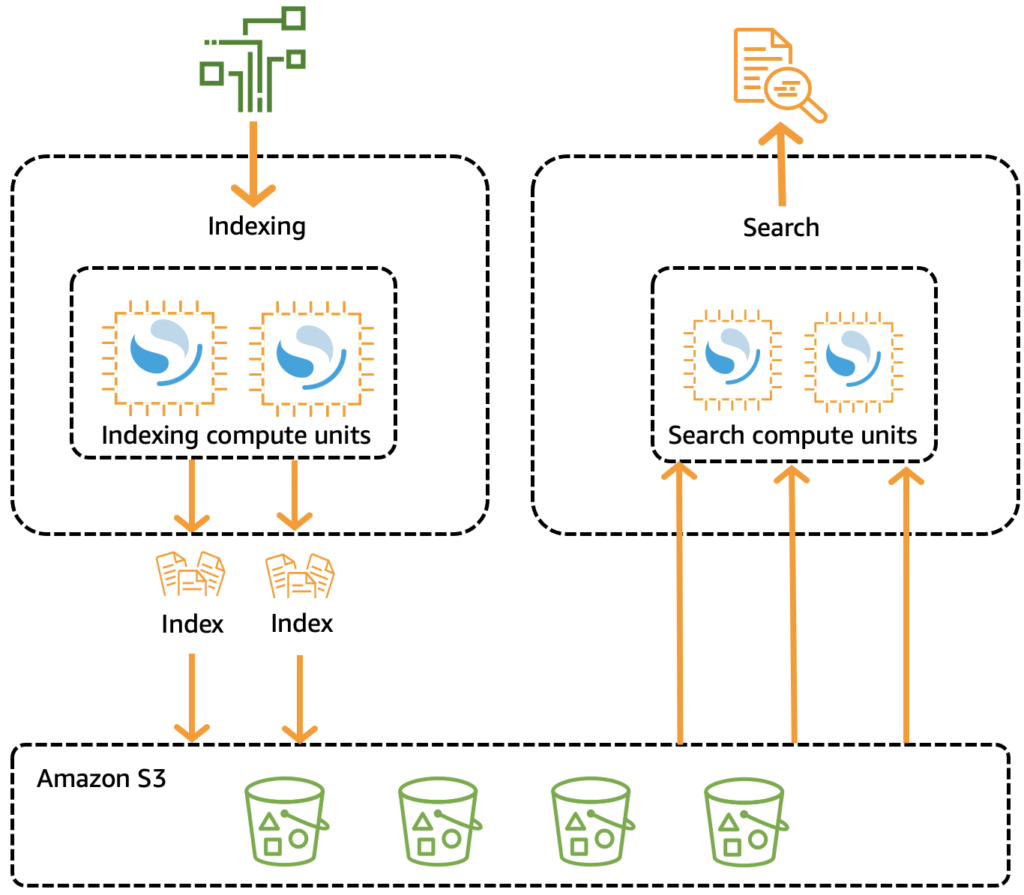
Source: AWS
OpenSearch Compute Units (OCUs)
When data is written to a collection in OpenSearch Serverless, it is distributed across indexing compute units designed for ingestion. These units process the incoming data, creating indices which are then stored in Amazon S3.
Upon receiving a search request, OpenSearch Serverless directs the query to dedicated search compute units. The units access the indexed data by retrieving it from S3 or locally cached copies, then execute the search operations and return results. This allows for high-performance querying and data analysis without the limitations imposed by traditional architecture.
OCUs are the basic measure of compute capacity for data ingestion and querying operations. Each OCU consists of 6 GiB of memory, an associated virtual CPU (vCPU), and includes data transfer capabilities to and from Amazon S3. Additionally, each OCU is provisioned with ephemeral storage sufficient for holding up to 120 GiB of index data.
As more collections are added within the same account, OpenSearch Serverless dynamically adjusts the number of OCUs to meet the demand, scaling up or down based on the workload.
Standby Replicas
Upon creating the first collection in an OpenSearch Serverless setup, two OCUs are initiated—one dedicated to indexing and another for search operations. To enhance reliability, OpenSearch Serverless also sets up standby nodes in an alternative Availability Zone, ensuring that operations can continue smoothly in case of a failure.
For development or testing environments, users have the option to disable these standby replicas to conserve resources. By default, however, these replicas are enabled, providing a redundant setup that ensures high availability and resilience.
OpenSearch Serverless Collection Types
OpenSearch Serverless can work with several types of data:
Time Series
Time series collection in OpenSearch Serverless is tailored for time-stamped data analysis, such as metrics, events, or logs. This enables efficient storage and querying of time-series data, supporting real-time monitoring and historical analysis. It’s designed to handle the high-volume, sequential nature of time series data, allowing organizations to track trends, patterns, or anomalies over time.
Search
The search collection in OpenSearch Serverless supports a range of search applications, from simple text searches to advanced queries. It is designed to provide rapid and relevant results, enhancing the user experience in applications requiring search functionality. This collection type incorporates features like keyword and phrase search, ranking, filtering, and faceted search, allowing for a customized search experience.
Vector Search
Vector search collections in OpenSearch Serverless are designed for high-performance similarity searches in machine learning (ML) and artificial intelligence (AI) applications. This type of search allows users to find similar items by comparing vector embeddings, which are dense representations of objects, such as images, text, or audio.
This collection type is useful for recommendation systems, image recognition, and natural language processing applications. The serverless nature of OpenSearch provides the flexibility and scalability essential for handling the computationally intensive tasks associated with vector search.
Quick Tutorial: Getting Started with Amazon OpenSearch Serverless
Here is a walkthrough of the process of using OpenSearch Serverless. The code and tutorial steps were adapted from the AWS documentation.
Step 1: Configuring Permissions
Start by setting up the necessary IAM permissions. This is crucial for performing operations such as creating collections, uploading, and searching data. The permissions required are encapsulated in an identity-based policy that must be attached to your user or role. Below is an example policy that grants the minimum permissions needed:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"aoss:CreateCollection",
"aoss:ListCollections",
"aoss:BatchGetCollection",
"aoss:DeleteCollection",
"aoss:CreateAccessPolicy",
"aoss:ListAccessPolicies",
"aoss:UpdateAccessPolicy",
"aoss:CreateSecurityPolicy",
"aoss:GetSecurityPolicy",
"aoss:UpdateSecurityPolicy",
"iam:ListUsers",
"iam:ListRoles"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
This policy enables actions such as creating, listing, and deleting collections, as well as managing access and security policies related to OpenSearch Serverless.
Step 2: Creating a Collection
A collection in Amazon OpenSearch Serverless groups together OpenSearch indices to support specific workloads or use cases. Here’s how you can create a collection called Movies which will be used for search purposes:
- Navigate to the Amazon OpenSearch Service console and select Collections from the left navigation pane.
- Click on Create collection and select the following options:
- Enter Books as the collection name.
- Select Search as the collection type.
- Under Encryption, choose Use AWS owned key for data encryption.
- Configure the network settings and select Public as the access type.
- Enable access to OpenSearch Dashboards and OpenSearch endpoints.
- Set up data access settings to allow users and roles to access data within the collection.
- Create a rule named Books collection access and add the principal (user or role) with permissions to index and search data in the collection.
- Opt to Create a new data access policy named Books.
- Review your settings and click Submit to create the collection.
- Wait until the collection status becomes Active. Copy the OpenSearch Dashboards URL for use in the next steps.
Step 3: Uploading and Searching Data
To upload and search data in your Books collection, you can use tools like Postman or curl. However, for simplicity, the following steps use the Dev Tools within the OpenSearch Dashboards console:
- Access the OpenSearch Dashboards URL for your collection.
- Navigate to Dev Tools.
- To index a document in the books-index, use the following PUT request:
PUT books-index/_doc/1
{
"title": "Lord of the Rings",
"genre": "Fantasy",
"year": 1954
}
- This request creates a new index named books-index and adds a document representing the book Lord of the Rings.
- To configure an index pattern for searching, go to Stack Management > Index Patterns and create a new pattern named books. This pattern will help OpenSearch to identify which indexes to analyze.
- To search the data, navigate to Discover in the OpenSearch Dashboards, or use the search API within Dev Tools. Here’s an example of how to search for documents in your books-index:
GET books-index/_search
{
"query": {
"match": {
"genre": "Fantasy"
}
}
}
This search request looks for documents in the books-index where the genre is Fantasy.
That’s it! You created a managed instance of OpenSearch with OpenSearch Serverless, uploaded your own data and searched for it.
Related content: Read our guide to OpenSearch Dashboards
From OpenSearch to Coralogix
Explore the benefits of Coralogix and how easy it is to migrate from OpenSearch to Coralogix.


{kind=link}