
Finding Your Way: Using Metrics to Explore Organizational Architecture


Imagine being the new developer in a bustling tech company. Everyone is rushing to meet deadlines, and no one has time to explain the tangled web of services, databases, and messaging systems that make up the organization’s architecture. You search high and low for documentation, but the few diagrams you find are outdated or incomplete. Feeling lost?
This is where metrics can come to the rescue. By leveraging metrics, you can uncover the architecture of a complex system without relying on scarce documentation or unavailable colleagues. Let’s explore how you, the intrepid newcomer, can use metrics to navigate the labyrinth of your organization’s infrastructure.
A Journey Through the Maze with Metrics
Understanding the connections, dependencies, and flows between services is crucial but often challenging. Luckily, metrics provide a map. By analyzing these metrics, you can reveal patterns, identify service dependencies, and spot potential bottlenecks. Tools like Prometheus, an open-source monitoring solution, offer a way to collect, store, and query these metrics, helping you to quickly make sense of the system’s architecture.
Exploring Service Interactions with Mesh Metrics
Imagine you’ve started your journey by wanting to know which services talk to each other. You suspect some of them might be crucial hubs in your architecture, but who are they, and what do they do? Enter Istio, a popular service mesh that provides rich telemetry data, offering insights into the communication patterns between microservices.
Istio metrics can tell you who’s chatting with whom and how often. Let’s start by peeking into the conversations happening across your system:
Identifying Service Interactions
To illustrate, consider the following Prometheus query to identify service interactions within an Istio environment:
group by (source_workload, destination_workload)
(rate(istio_requests_total[5m]))
This query aggregates the rate of requests over the past five minutes, grouped by source and destination workloads. Imagine it like overhearing a conversation in a crowded room—except you have a perfect memory and can track every single chat.
Example results of query above:
{destination_workload="service-a",source_workload="service-b"}
{destination_workload="service-a",source_workload="service-c"}
{destination_workload="service-c",source_workload="service-d"}
Look at that! You’ve discovered that service-b and service-c both communicate with service-a, while service-d chats with service-c. This insight gives you a snapshot of the organization’s architecture—like discovering the key stations in a sprawling subway map. Now you have a clearer understanding of which services are central players and where data might be flowing.
Following the Data Trail: Analyzing Kafka Metrics
Next, let’s follow the data trail. In your new role, you quickly notice that Kafka, a distributed streaming platform, is the lifeblood of many of your organization’s data flows. Kafka serves as a central hub for asynchronous communication between services, and its metrics can offer a wealth of information about the data flows and the roles different services play.
Monitoring Kafka Consumer Group
To start your Kafka exploration, begin with a generic query that allows you to identify which consumer groups are associated with which topics. This query groups the consumer lag by both the topic and the consumer group, giving you a high-level overview of the consumption landscape:
group by (topic, group) (kafka_consumergroup_group_lag_seconds{})
This query provides a snapshot of all the consumer groups and the topics they are consuming from. Think of it as a bird’s-eye view of the data flow within Kafka—an initial map that shows you where to start your deeper dive.
Drilling Down into Specific Groups and Topics
From this high-level overview, you can choose a specific topic, group pair that catches your eye. Maybe there’s a particular topic with a high lag or an unusually high number of consumer groups. Let’s say you spot a group called service-A-consumer consuming from the topic user_events. Now, you want to dig deeper to understand their relationship.
Use a more focused query to drill down into the consumption rate or lag for this specific pair:
group by (topic, client_id) (kafka_consumer_bytes_consumed_rate{group="service-A-consumer", topic="user_events"}[5m])
This query helps you understand how quickly service-A-consumer is processing messages from the user_events topic. Similarly, you can query the consumer lag to see how far behind it is:
group by (topic, group) (kafka_consumergroup_group_lag_seconds{group="service-A-consumer", topic="user_events"})
These insights are crucial for mapping out which services (like service-A mentioned earlier in the Istio section) are consuming from which data streams, helping you piece together the broader architecture. The specific numbers-like the rate or lag-are less important here. What truly matters is understanding the relationships and dependencies between services and data flows.
Correlating with Service Information
Remember, the name service-A-consumer hints that it might be associated with service-A identified earlier in your exploration using Istio metrics. By correlating Kafka consumer groups with service names from Istio metrics, you can build a more comprehensive picture of how services interact through data streams. This approach enables you to see not just who is talking to whom but also who is consuming data from which sources, adding another layer to your understanding of the system architecture.
Unveiling Kafka Producers: Mapping Out Data Production
Just as you explored the Kafka consumer landscape, you can uncover which producers are generating data for which topics. Kafka doesn’t provide built-in Prometheus metrics directly for tracking this, but you can still explore the relationships using JMX metrics or third-party tools like Kafka Exporter.
Start by getting an overview of which producers are active and what topics they are writing to:
sum by (client_id, topic) ****(kafka_producer_byte_rate{})
This query shows the rate at which messages are being sent by different producer clients to various topics. It gives you a starting point for understanding which services are producing data and to where.
Drilling Down into Specific Producers and Topics
From this broader view, select a specific (client_id, topic) pair that appears particularly interesting—maybe a high data throughput or an unexpected topic association. For example, you notice that service-B-producer is writing heavily to the transaction_events topic. Now, you want to investigate this further.
Use a focused query to drill down and analyze more specific metrics, such as the throughput in terms of bytes:
rate(kafka_producer_byte_rate{client_id="service-B-producer", topic="transaction_events"}[5m])
The goal here is not so much about the actual data rates or volumes but rather about uncovering the relationships—like which service (e.g., service-B) is actively producing data and where that data is going.
Tying Producers to Service Interactions
Just like with consumers, linking Kafka producer metrics to service information from Istio or other mesh metrics can help you understand which services are acting as data sources. If service-B was identified earlier as an important node in service-to-service communications, confirming its role as a key data producer adds a vital piece to your architectural puzzle.
By stitching together these insights, you can visualize both the communication pathways and the data flows across your organization’s architecture, leading to a much clearer understanding of how everything connects.
Putting Kafka metrics together
When you pair information from Kafka consumers with that from Kafka producers, you can gain comprehensive insights into your system architecture and interconnected services. This allows for a deeper understanding of how different components interact and depend on each other.
Correlating Istio and Kafka Metrics: The Full Picture
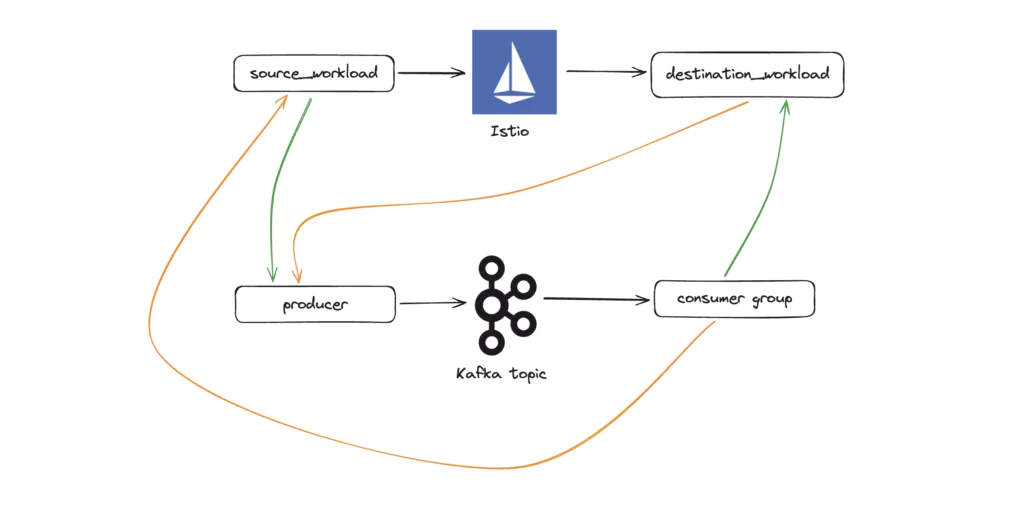
Now, the real magic happens when you correlate the insights from both Istio and Kafka. Imagine you’ve discovered, through Istio, that service-A talks frequently to service-B. Then, using Kafka metrics, you notice that service-A is a producer for a topic that service-B consumes. Bingo! You’ve just confirmed that service-A is not only a service in the architecture but also a producer in the data pipeline, while service-B plays the role of a consumer.
Example Scenario
- Service Discovery: Find
service-Acommunicating withservice-Busing Istio metrics. - Data Flow Analysis: Confirm
service-Ais producing to a Kafka topic consumed byservice-B. - Validation: Check if the service names and data flows match up, giving you confidence in your understanding of the architecture.
The Secret to Success: Homogeneous Labeling Across Metrics
Let’s pause for a moment. While you’re well on your way to becoming the architecture explorer extraordinaire, there’s a crucial factor that makes this whole exercise possible: consistent labeling across metrics.
Without consistent labels (like service_name, environment, or team), you would be left guessing which metric belongs to which service. Imagine trying to read a map where every street is labeled differently by different cartographers—you’d be lost in no time! The same goes for metrics. Consistency in labels allows you to correlate data from different sources accurately, ensuring your exploration is based on solid ground rather than educated guesses.
Conclusion: The Adventure Awaits
Welcome to the world of metrics-driven exploration! By using tools like Prometheus, Istio, and Kafka, you can uncover the hidden architecture of your organization and quickly get up to speed – even when documentation is lacking and everyone is too busy to onboard you properly. Keep your wits about you, and remember: the more consistent your labeling, the clearer the path will be.
So, go ahead! Start with a simple query, uncover a service dependency, follow the Kafka trails, and piece together the architecture bit by bit. Your journey into the unknown is just beginning, and every metric is a clue waiting to be uncovered.


