The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

In recent years, microservices have emerged as a popular architectural pattern. Although these self-contained services offer greater flexibility, scalability, and maintainability compared to monolithic applications, they can be difficult to manage without dedicated tools.
Kubernetes, a scalable platform for orchestrating containerized applications, can help navigate your microservices. In this article, we will explore the relationship between Kubernetes and microservices, key components and benefits of Kubernetes and best practices for deploying microservices on the platform.
Before we dive in, let’s take a moment to understand the concept of microservices and examine some of the challenges they present, such as log management.
What are microservices?
Microservices are an architectural style in software development where an application is built as a collection of small, loosely coupled, and independently deployable services.
Each service represents a specific business capability and operates as a separate unit, communicating with other services through well-defined APIs. These services are designed to perform a single task or function, following a single responsibility principle.
In contrast to traditional monolithic architectures, where the entire application is tightly integrated and deployed as a single unit, microservices break down the application into smaller, more manageable pieces.

Source: https://aws.amazon.com/compare/the-difference-between-monolithic-and-microservices-architecture/
Benefits of microservices
Adopting a microservice architecture has several benefits. The decentralized nature of microservices enables them to operate independently, allowing separate development, deployment, and scalability. This autonomy leads to decentralized decision-making, fostering an environment where teams can work autonomously.
Additionally, it allows developers to use different technologies and frameworks across microservices, as long as they adhere to standardized APIs and communication protocols.
The modular structure of microservices brings flexibility and agility to development, facilitating easy modifications and updates without disrupting the entire application.
This flexibility enables development teams to swiftly respond to changing requirements, accelerating time-to-market. It also means that a failure in one service does not cascade to affect others, resulting in a more robust overall system.
Lastly, microservices support horizontal scaling. Each service can replicate itself to handle varying workloads, ensuring optimal resource utilization and scalability as the application grows.
Challenges of microservices
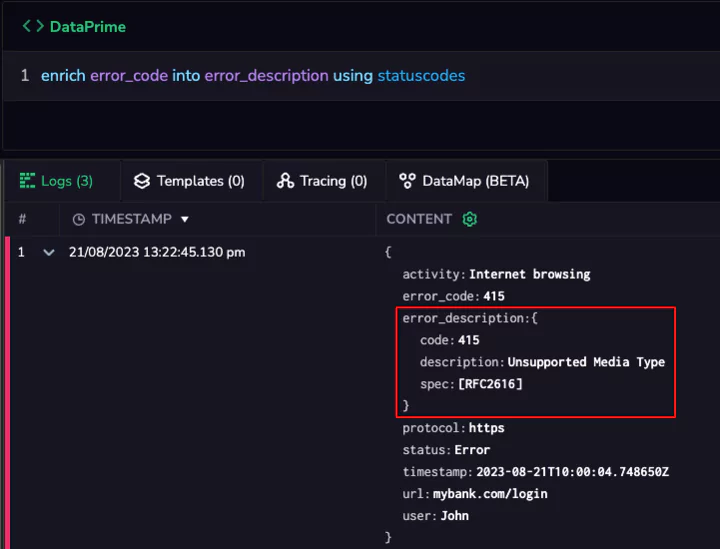
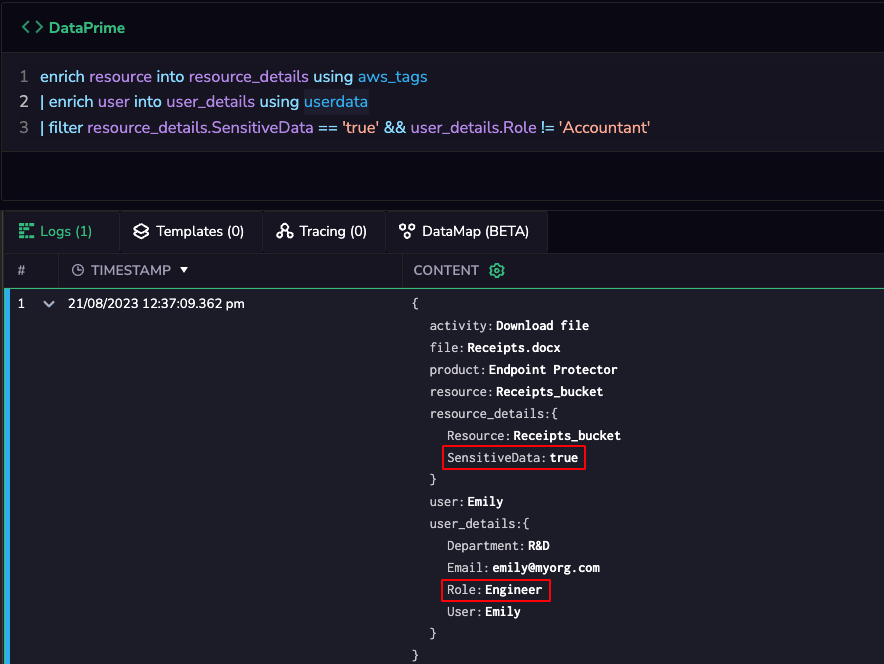
While microservices offer many advantages, they also introduce complexities in certain areas, such as observability. In a monolithic application, it is relatively easy to understand the system’s behavior and identify issues since everything is tightly coupled. As an application is divided into independent microservices, the complexity naturally rises, requiring a shift in how observability is employed within the system. This is especially true for log observability for microservices, since we now have independent services that generate an important amount of logs when interacting with each other and handling requests.
Other challenges of microservices include managing inter-service communication, data consistency, and orchestrating deployments across multiple services. Thus Kubernetes can help you by offering a robust and efficient solution to handle these challenges and streamline the management of microservices.
Components of Kubernetes
Before delving into the advantages of using Kubernetes for microservices, let’s take a brief look at its key components.
A Kubernetes cluster is composed of a Control Plane and Worker Nodes. Each worker node is like a stage where your applications perform. Inside these nodes, you have small units called pods, which are like mini-containers for your applications.
These pods contain your application’s code and everything it needs to run. The control plane is like the mastermind, managing the entire show and keeping track of all the worker nodes and pods, making sure they work together harmoniously. The pods will also orchestrate the deployment, scaling, and health of your applications.

Source: https://kubernetes.io/docs/concepts/overview/components/
Kubernetes also provides other valuable features, including:
- Deployments
With Deployments, you can specify the desired state for pods, ensuring that the correct number of replicas is always running. It simplifies the process of managing updates and rollbacks, making application deployment a smooth process..
- Services
Kubernetes Services facilitate seamless communication and load balancing between pods. They abstract away the complexity of managing individual pod IP addresses and enable stable access to your application services.
- ConfigMaps and Secrets
ConfigMaps and Secrets offer a neat way to separate configuration data from container images. This decoupling allows you to modify configurations without altering the container itself and enables secure management of sensitive data.
- Horizontal Pod Autoscaling (HPA)
HPA is a powerful feature that automatically adjusts the number of pods based on resource utilization. It ensures that your applications can handle varying workloads efficiently, scaling up or down as needed.
Benefits of using Kubernetes for microservices
Kubernetes provides several advantages when it comes to managing microservices effectively.
- Scalability
Kubernetes excels at horizontal scaling, allowing you to scale individual microservices based on demand. This ensures that your applications can handle varying workloads effectively without over-provisioning resources.
- High availability
Kubernetes provides built-in self-healing capabilities. If a microservice or a node fails, Kubernetes automatically restarts the failed components or replaces them with new ones, ensuring high availability and minimizing downtime.
- Resource management
Kubernetes enables efficient resource allocation and utilization. You can define resource limits and requests for each microservice, ensuring fair distribution of resources and preventing resource starvation.
- Rolling updates and rollbacks
With Kubernetes Deployments, you can seamlessly perform rolling updates for your microservices, enabling you to release new versions without service disruption. In case of issues, you can quickly roll back to the previous stable version.
- Service discovery and load balancing
Kubernetes provides a built-in service discovery mechanism that allows microservices to find and communicate with each other. Additionally, Kubernetes automatically load-balances incoming traffic across multiple replicas of a service.
- Automated deployment
Kubernetes enables the automation of microservices deployment. By integrating CI/CD pipelines with Kubernetes, you can automate the entire deployment process, reducing the risk of human errors and speeding up the delivery cycle.
- Declarative configuration
Kubernetes follows a declarative approach, where you specify the desired state of your microservices in YAML manifests. Kubernetes then ensures that the actual state matches the desired state, handling the complexities of deployment and orchestration.
- Version compatibility
Kubernetes supports various container runtimes, such as Docker and containerd, allowing you to run containers built with different versions of the runtime. This makes it easier to migrate and manage microservices developed with diverse technology stacks.
- Community and ecosystem
Kubernetes has a vibrant and active open-source community, leading to continuous development, innovation, and support. Additionally, an extensive ecosystem of tools, plugins, and add-ons complements Kubernetes, enriching the overall user experience.
- Observability and monitoring
Kubernetes integrates well with various monitoring and observability tools, providing insights into the performance and health of microservices.
12 tips for using microservices on Kubernetes
Creating and deploying microservices on Kubernetes involves several steps, from containerizing your microservices to defining Kubernetes resources for their deployment. Here’s a step-by-step guide, featuring our Kubernetes tips, to help you get started:
1. Containerize your microservices
Containerize each microservice and Include all dependencies and configurations required for the service to run.
2. Set up Kubernetes cluster
Install and set up Kubernetes. Depending on your requirements, you can use a managed Kubernetes service (e.g., GKE, AKS, EKS) or set up your own Kubernetes cluster using tools like kubeadm, kops, or k3s.
3. Create Kubernetes deployment manifest
Write a Kubernetes Deployment YAML manifest for each microservice: Define the desired state of the microservice, including the container image, resource limits, number of replicas, and any environment variables or ConfigMaps needed.
4. Create Kubernetes service manifest
If your microservices require external access or communication between services, define a Service resource to expose the microservice internally or externally with a Kubernetes Service YAML manifest.
5. Apply the manifests
Use the kubectl apply command to apply the Deployment and Service manifests to your Kubernetes cluster. This will create the necessary resources and start the microservices.
6. Monitor and scale
Observability is especially important in microservices due to the challenges posed by the distributed and decentralized nature of microservices architecture. To ensure the best user experience, it is essential to have robust tools and observability practices in place. .
Once your observability tools are up and running, consider setting up Horizontal Pod Autoscaler (HPA) to automatically scale the number of replicas based on the metrics you gather on resource utilization.
7. Continuous integration and continuous deployment
Integrate your Kubernetes deployments into your CI/CD pipeline to enable automated testing, building, and deployment of microservices.
8. Service discovery and load balancing
Leverage Kubernetes’ built-in service discovery and load balancing mechanisms to allow communication between microservices. Services abstract the underlying Pods and provide a stable IP address and DNS name for accessing them.
9. Configure ingress controllers
If you need to expose your microservices to the external world, set up an Ingress Controller. This will manage external access and enable features like SSL termination and URL-based routing.
10. Manage configurations and secrets
Use ConfigMaps and Secrets to manage configurations and sensitive data separately from your container images. This allows you to change settings without redeploying the microservices.
11. Rolling updates and rollbacks
Utilize Kubernetes Deployments to perform rolling updates and rollbacks seamlessly. This allows you to release new versions of microservices without service disruption and easily revert to a previous stable version if needed.
12. Security best practices
Implement Kubernetes security best practices, such as Role-Based Access Control (RBAC), Network Policies, and Pod Security Policies, to protect your microservices and the cluster from potential threats.
What to find out more? Check out our introduction to Kubernetes observability for best observability practices with Kubernetes.