The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

Amazon Web Services (AWS) introduced a preview of Timestream in November 2018 before releasing the full version in October 2020. AWS Timestream is a time series database that can process trillions of events daily. It is faster and less costly than relational databases offered by AWS for processing time-series information.
In this article, we will look at what Timestream can do compared to some other AWS observability tools, and how to use Timestream to help monitor the health of your system.
What Can Timestream Do?
AWS Timestream comes stocked with many benefits for its users. The significant benefits include:
High Performance
Time-series data is commonly used for real-time processing, meaning it needs to be fast. AWS Timestream offers queries claimed to be 1000x faster than relational databases.
Low Cost
Since Timestream is bound to have more events than other types of tracking, it was crucial to keep the cost low. AWS Timestream can cost as little as 1/10th of what a relational database could cost.
Automatic Scaling
Like other AWS services, Timestream is serverless. Users do not need to configure capacity requirements or manage servers. The Timestream database will automatically scale up and down as your capacity changes.
Use SQL Queries with Built-In Functions
Timestream allows users to query data using SQL queries. It comes with some built-in analytics capabilities as well. Users can smooth, interpolate, or approximate data while querying. Timestream also includes more advanced models like aggregation.
Automatic Data Lifecycle Management
AWS Timestream uses two tiers of memory storage: a memory store and a magnetic store. The memory store is faster to access, and Timestream uses it for recent data. The magnetic store is slower to access and used for historical data.
Simple Data Access
AWS Timestream uses two data stores based on the age of the event. The queries used on the Timestream database will access both data stores without users needing to specify the data’s location.
Automatic Encryption
AWS automatically encrypts Timestream data. Users can choose to manage their encryption keys or use an AWS managed key. Encryption is applied both for data at rest and in transit.
When should you choose Timestream?
AWS offers many database types, including relational and key-value database options. Whether or not to choose Timestream over these other options depends on your use case. AWS designed Timestream for time series data. It can provide less cost, higher efficiency, and more features than other database types when dealing with time series data.
Time series use cases include:
- Recording weather patterns over time
- Logging IoT sensor data from devices over time
- Monitoring analytics from an app or webpage over time
AWS Timestream stores continuous data for a given measure, logging a time with each event. Each event is also associated with metadata which is available in SQL queries. Events cannot be updated or deleted once written to Timestream since it is an append-only database.
Timestream vs. DynamoDB
AWS DynamoDB tables store data according to key-value pairs. Users can insert and update information based on timestamps. Each entry into the database can have any number of attributes, and those attributes could even be different for different documents.
Amazon designed Dynamo’s data structure for fast querying, which Timestream does not match. However, Timestream comes with built-in analytics like interpolation, which can be especially useful for time-series analyses.
Timestream vs. Aurora
Amazon’s Relational Database Services (RDS) databases are a series of tools to set up relational databases like PostgreSQL, MySQL, or Amazon Aurora. Aurora databases are managed by AWS, reaching 128TB in size. Data is replicated multiple times across multiple zones to ensure availability and durability. Users can update and delete information from tables if needed.
Relational databases have limited capabilities for time-series analysis due to the fact that they cannot store and query data using time intervals. Also, Aurora will back up data to S3 after reaching its size limit, making it unavailable to query using the same SQL commands used for acquiring contents of the table.
Using AWS Timestream to Monitor System Health
Amazon designed AWS Timestream to ingest trillions of time-series events daily. This capacity, along with its built-in analytical functions, positions Timestream as a superior database for collecting system health data.
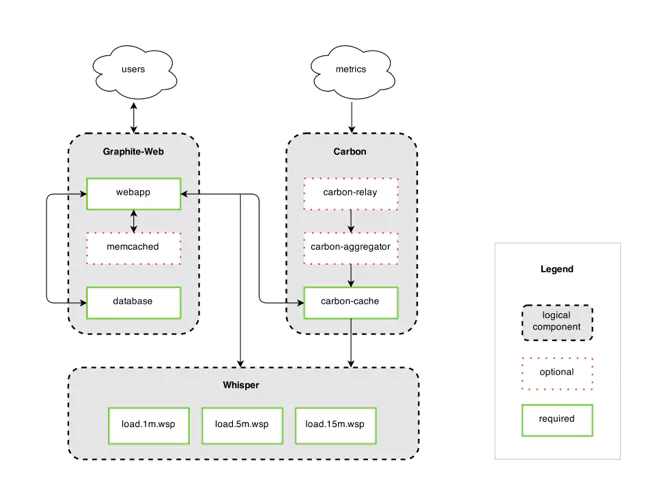
AWS Timestream Configuration
Timestream configuration includes databases and tables. Databases are a top-level container for data. Users create tables within a database and inject events from one or more related time series into a given table. For system health metrics, create a database for any discrete system (staging, production, development).
Table definitions are simple since Timestream is serverless and does not require capacity definitions on creation. Users must configure data retention duration for each of the two memory stores: memory store and magnetic store.
AWS Timestream Data Retention and Memory
Memory store is the short-term data store. AWS also ensures the durability of data by replicating it across multiple availability zones. The duration of the memory store must be at least as much as the time between the event’s timestamp and Timestream ingestion time.
Loading older data into Timestream can be done, but data timestamps must conform to the memory store limit. Since the memory store retention maximum is one year, only data with timestamps dating back one year may be loaded into Timestream.
The magnetic store is the long-term, low-cost data store. AWS will automatically move data from the memory store to the magnetic store based on your configuration. Data is automatically backed up into S3 to ensure durability.
Queries on Timestream tables will access both memory types automatically without any extra settings from users.
Data Analysis
Loaded data may vary based on the monitored aspect of system health. Users can monitor many aspects by adding more tables to their Timestream. Having a Timestream setup with data in place, users can begin to assess their system’s health. Data may include web page load times, memory utilization, AWS Lambda function durations, or app analytics. Each data set can assign dimensions, or metadata, with the Timestream event for better analytical capabilities.
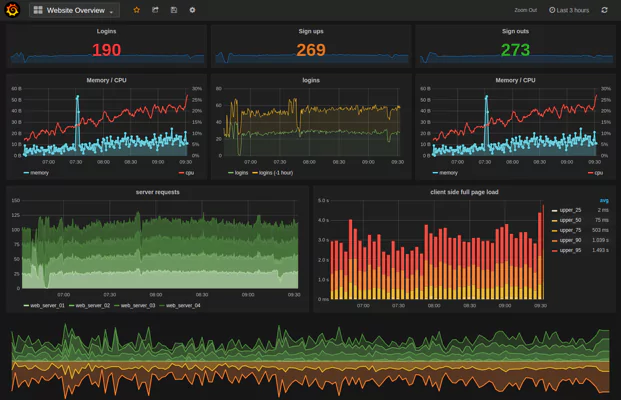
Queries use SQL formatting and can include some built-in analysis. Timestream allows users to run interpolations, smoothing functions, and approximation functions. Timestream also added join capabilities to Timestream some months after its general release. Users can choose to export data to a visualization tool such as AWS Managed Grafana.
While Timestream allows straightforward analytics, further analysis may be needed to gain insights into potential service issues. Users can choose to export Timestream data to third-party services like Coralogix’s scalable metrics analytics service to automatically gain insight from gathered data.
Coralogix uses machine learning algorithms to further analyze your Timestream data for deeper insights from your collected metrics than what is available with built-in Timestream functions.
Summary
Timestream is a generally available, serverless database configured for efficient, cost-effective, and scalable time-series logging and analysis. Timestream uses SQL queries with built-in analysis tools to help users monitor system health metrics and other time-series data.
Users can export Timestream data to other services that can provide further insights into your data. Coralogix’s ingestion tools for AWS can be used to send Timestream data to Coralogix via AWS Kinesis or AWS Lambda for more complex analyses.