
OpenSearch: The Basics and a Quick Tutorial


The Origins of OpenSearch
The OpenSearch project came into being following a controversy around Elastic, the company behind Elasticsearch. In early 2021, Elastic announced that they would change Elasticsearch’s license from Apache 2.0 to Server Side Public License (SSPL), which the Open Source Initiative does not recognize.
The switch from Apache 2.0 to SSPL was a response to Amazon providing a managed service on top of open-source Elasticsearch, which Elastic claimed was not a fair use of their open-source solution. Elastic sued Amazon and changed the license to one that allows free product use, but prohibits organizations like Amazon from using it to run managed services.
However, Elastic’s action was criticized by many in the open-source community as a shift away from open-source principles. Amazon decided to fork Elasticsearch and Kibana 7.10.2 and create OpenSearch, a “pure” open-source fork of Elasticsearch, which it could use to power its managed services.
OpenSearch vs. ElasticSearch: What Are the Differences?
While OpenSearch and Elasticsearch share a common ancestry, there are some key differences between the two. The most significant of these differences is the licensing. As mentioned earlier, Elasticsearch is now licensed under the SSPL, while OpenSearch remains under the Apache 2.0 license. This means that OpenSearch offers more flexibility and freedom for users, as the Apache 2.0 license allows for more liberal use, modification, and distribution of the software.
Another difference is the governance model. OpenSearch is community-led, meaning that its users and developers have a say in its direction and development. Elasticsearch, on the other hand, is controlled by Elastic, which has the final say on its development and future.
In terms of features, while OpenSearch has a similar feature set to Elasticsearch, it is likely to diverge from the main project over time. New innovations by Elastic and the almost 2,000 contributors to the Elasicsearch project will not be incorporated into OpenSearch, which has a far smaller community of around 200 contributors. However, the corporate sponsorship of Amazon will provide the project with the funding and energy to continue innovating.
Learn more in our detailed guide about OpenSearch vs Elasticsearch
What Is Amazon OpenSearch Service?
Amazon OpenSearch Service is a managed service that makes it easy to deploy, operate, and scale OpenSearch clusters (very similar to Elasticsearch clusters) in the AWS Cloud. The service offers a variety of features that simplify the process of setting up and managing OpenSearch clusters. These include automated backups, automated software patches, and automated scaling.
Amazon OpenSearch Service also offers integration with other AWS services. You can use OpenSearch with services like Amazon CloudWatch for monitoring, AWS Identity and Access Management (IAM) for access control, and AWS KMS for data encryption.
The service also provides tools and resources to help users get the most out of OpenSearch. These include comprehensive documentation, tutorials, and a community forum where users can ask questions and share experiences.
What Is Amazon OpenSearch Serverless?
Amazon OpenSearch Serverless is a new addition to the Amazon OpenSearch Service that offers a serverless runtime option. This means that you no longer need to provision, scale, and manage servers to run OpenSearch. Instead, Amazon manages all the infrastructure for you.
Amazon OpenSearch Serverless automatically scales to match your workload, so you only pay for the resources you actually use. This can result in significant cost savings, especially for unpredictable or fluctuating workloads throughout the day.
Learn more in our detailed guide to OpenSearch Serverless
OpenSearch Architecture and Components
Here are some of the key components that comprise the OpenSearch architecture. These are very similar to Elasticsearch.
Clusters and Nodes
A cluster is a collection of one or more nodes (servers) holding your entire data and providing indexing and search capabilities across all nodes. A node is a single server that is part of your cluster, capable of storing data, and participating in the cluster’s indexing and search capabilities.
Each node within a cluster has a specific role. For example, there are master-eligible nodes that can be elected to become the master node (the node in charge of the cluster’s health and stability), data nodes that store data and execute data-related operations, and ingest nodes that preprocess documents before indexing.
Indexes and Documents
An index is a collection of documents that have similar characteristics. Each index is identified by a name, which is used to refer to the index when performing indexing, search, update, and delete operations.
A document is a basic unit of information that can be indexed. For example, in an e-commerce website, a single product can be a document. Each document is expressed in JSON (JavaScript Object Notation), a widespread, easy-to-use file format that structures data in a way both humans and machines can understand.
Coordinating Nodes and Sharding
In OpenSearch, coordinating nodes are those that do not hold any data themselves but are responsible for routing requests from the client to the appropriate nodes in the cluster. They play a vital role in load balancing and are a key component in maintaining the system’s high performance.
OpenSearch also introduces the concept of sharding—splitting your index into multiple parts, called shards. Each shard is a fully-functional and independent index that can be hosted on any node within a cluster.
Sharding your data makes it possible to distribute documents across multiple nodes and offers two main benefits: it allows you to horizontally split/scale your content volume. It also allows you to distribute and parallelize operations across shards (and nodes), thus increasing performance/throughput.
Search Engine and Data Store
OpenSearch acts as both a search engine and a data store. As a search engine, it searches through large amounts of data and brings back relevant results in near-real time. It utilizes a structure known as an inverted index, which is a kind of map that directs the search to the appropriate place in the data store, making the retrieval process incredibly fast.
As a data store, OpenSearch allows you to store a large amount of structured, semi-structured, and unstructured data. It’s capable of storing various types of data, from numerical and text data to geospatial and even binary data.
Visualization and User Interface
OpenSearch comes bundled with OpenSearch Dashboards, an analytics and visualization platform (derived from Kibana) that lets you visualize your OpenSearch data in a variety of charts, tables, and maps. It’s considered to be user-friendly, making it easy to create, share, and embed visualizations and dashboards for real-time insights into your data.
The user interface is intuitive, simplifying the process of managing your data, running complex queries, and visualizing the results. It’s designed with all levels of users in mind, making it accessible even to those with limited experience in data management or analysis.
Learn more in our detailed guide to OpenSearch Dashboards
Tutorial: Getting Started with OpenSearch
Let’s look at how you can start using OpenSearch and OpenSearch Dashboards by deploying Docker containers. The code below was shared in the official documentation.
Note: This tutorial shows how to get started with the OpenSearch project on your local machine, not with the Amazon OpenSearch service. For an Amazon OpenSearch tutorial, see our guide to Elasticsearch on AWS.
Prerequisites
First, ensure that Docker and Docker Compose are already installed on your local machine.
Next, deactivate memory paging and swapping on the host. This will improve performance and allow OpenSearch to access a larger memory volume:
# Turn off memory paging and swapping. sudo swapoff -a # Modify the sysctl config file to define the max map count for the host. sudo vi /etc/sysctl.conf # Assign max map count the suggested value of 262144. vm.max_map_count=262144 # Refresh the kernel settings. sudo sysctl -p
Refer to the documentation for more recommendations on system settings.
Creating your Cluster
To create an OpenSearch cluster, you need a Compose file, which Docker Compose can use to define and create the cluster’s containers. The OpenSearch Project offers a sample Compose file to get you started.
To create your first cluster using the sample Compose file:
- Download the compose file using curl or wget, or simply manually copy docker-compose.yml from the OpenSearch repository. Here is how to get the file using curl:
curl -O https://raw.githubusercontent.com/opensearch-project/documentation-website/2.11/assets/examples/docker-compose.yml
- Navigate to the directory into which you downloaded docker-compose.yml file. Run the following command to initiate and launch the cluster as a background process:
docker-compose up -d
- Make sure OpenSearch containers are running by executing:
docker-compose ps
- Ensure the service is running by querying the OpenSearch REST API. Use -k to turn off hostname validation (demo certificates are used in the default security configuration) and use -u for the default username and password (admin:admin).
curl https://localhost:9200 -ku admin:admin
Here is an example of the JSON output:
{
"name" : "opensearch-node1",
"cluster_name" : "opensearch-cluster",
"cluster_uuid" : "W0B8gPotTAajhMPbC9D4ww",
"version" : {
"distribution" : "opensearch",
"number" : "2.6.0",
"build_type" : "tar",
"build_hash" : "7203a5af21a8a009aece1474446b437a3c674db6",
"build_date" : "2023-02-24T18:58:37.352296474Z",
"build_snapshot" : false,
"lucene_version" : "9.5.0",
"minimum_wire_compatibility_version" : "7.10.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}
Create an Index and Field Mappings
The OpenSearch Project provides a sample eCommerce dataset, which you can download here.
- Download the file field mapping for the sample eCommerce file. Here is how to do it with curl:
curl -O https://raw.githubusercontent.com/opensearch-project/documentation-website/2.11/assets/examples/ecommerce-field_mappings.json
- Fetch the file ecommerce.json file, which holds the OpenSearch index data. Here is how to do it with curl:
curl -O https://raw.githubusercontent.com/opensearch-project/documentation-website/2.11/assets/examples/ecommerce.json
- Create OpenSearch field mappings using the mapping file you downloaded:
curl -H "Content-Type: application/x-ndjson" -X PUT "https://localhost:9200/ecommerce" -ku admin:admin --data-binary "@ecommerce-field_mappings.json"
- Now, use the following curl command to upload the index via the bulk API:
curl -H "Content-Type: application/x-ndjson" -X PUT "https://localhost:9200/ecommerce/_bulk" -ku admin:admin --data-binary "@ecommerce.json"
- Now you can query your data with the search API. Use this command to return documents where the customer_first_name is Sonya:
curl -H 'Content-Type: application/json' -X GET "https://localhost:9200/ecommerce/_search?pretty=true" -ku admin:admin -d' {"query":{"match":{"customer_first_name":"Sonya"}}}'
- Access OpenSearch Dashboards by typing http://localhost:5601/ in a web browser, on the same host where your OpenSearch cluster is running. The default credentials are admin:admin.
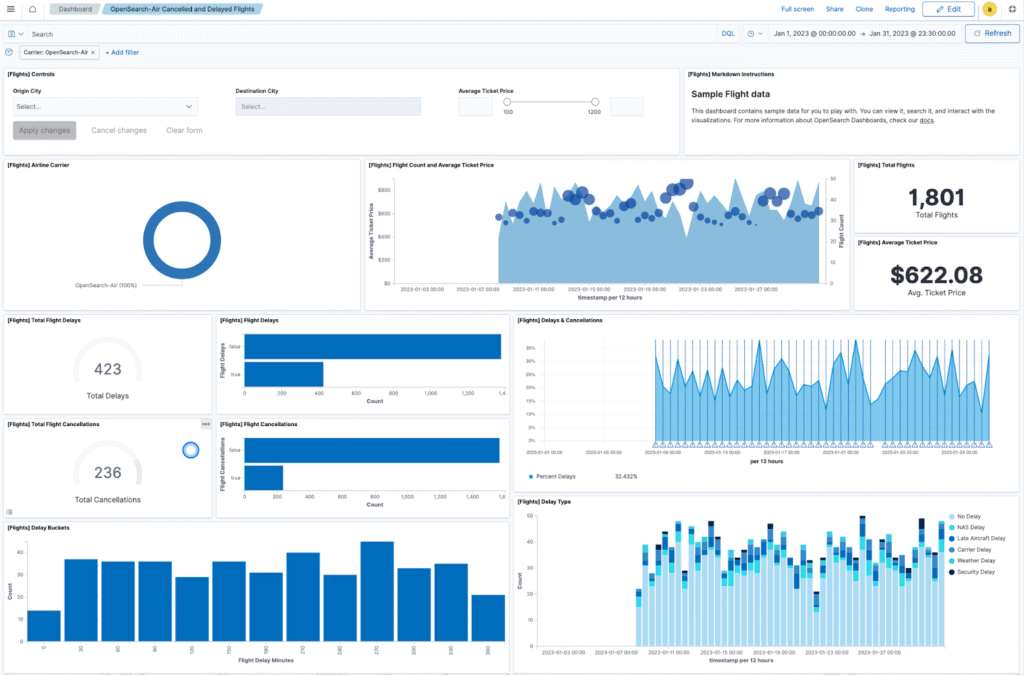
Source: OpenSearch
- In the dashboard, navigate to Management > Dev Tools. Enter the following in the console’s left pane:
GET ecommerce/_search
{
"query": {
"match": {
"customer_first_name": "Sonya"
}
}
}
- Submit the query by clicking on the triangle-shaped icon, or pressing Ctrl+Enter. Learn more on how to run queries in OpenSearch Dashboards in the documentation.
Learn about additional OpenSearch capabilities in our OpenSearch tutorial
From OpenSearch to Coralogix
Explore the benefits of Coralogix and how easy it is to migrate from OpenSearch to Coralogix.
See Additional Guides on Key Open Source Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of open source.
OpenTelemetry
Authored by Coralogix
- Quick Guide to OpenTelemetry: Concepts, Tutorial, and Best Practices
- OpenTelemetry Collector: The Basics and a Quick Tutorial
- OpenTelemetry Java: The Basics and a Quick Tutorial
Kubernetes Architecture
Authored by Run.AI
- Kubeflow Pipelines: The Basics and a Quick Tutorial
- Securing your AI/ML Kubernetes Environment
- Kubeflow Pipelines: The Basics and a Quick Tutorial
Apache Spark
Authored by Granulate
- Apache Spark: Architecture, Best Practices, and Alternatives
- Apache Spark: Quick Start and Tutorial
- Spark Streaming (Structured Streaming): Basics & Quick Tutorial


{kind=link}