The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

One of the benefits of deploying software on the cloud is allocating a variable amount of resources to your platform as needed. To do this, your platform must be built in a scalable way. The platform must be able to detect when more resources are required and assign them. One method of doing this is the Elastic Load Balancer provided by AWS.
Elastic load balancing will distribute traffic in your platform to multiple, healthy targets. It can automatically scale according to changes in your traffic. To ensure scaling has appropriate settings and is being delivered cost-effectively, developers need to track metrics associated with the load balancers.
Available Elastic Load Balancers
AWS elastic load balancers work with several AWS services. AWS EC2, ECS, Global Accelerator, and Route 53 can all benefit from using elastic load balancers to route traffic. Monitoring can be provided by AWS CloudWatch or third-party analytics services such as Coralogix’s log analytics platform. Each load balancer available is used to route data at a different level of the Open Systems Interconnection (OSI) model. Where the routing needs to occur strongly determines which elastic load balancer is best-suited for your system.
Application Load Balancers
Application load balancers, route events at the application layer, the seventh and highest layer of the OSI model. The load balancer component becomes the only point of contact for clients so it can appropriately route traffic. Routing can occur across multiple targets and multiple availability zones. The listener checks for requests sent to the load balancer, and routes traffic to a target group based on user-defined rules. Each rule includes a priority, action, and one or more conditions. Target groups route requests to one or more targets. Targets can include computing tasks like EC2 instances or Fargate Tasks deployed using ECS.
Developers can configure checks for target health. If this is in place, the load balancer will only be able to send requests to healthy targets, further stabilizing your system when a sufficient number of registered targets are provided.
Classic Load Balancers
Classic load balancers distribute traffic for only EC2 instances working on the transport and application OSI layers. The load balancer component is the only point of contact for clients, just as it is in application load balancers. EC2 instances can be added and removed as needed without disrupting request flows. The listener checks for requests sent to the load balancer and sends them to registered instances using a user-configured protocol and port values.
Classic load balancers can also be configured to detect unhealthy EC2 instances. They can route traffic only to healthy instances, stabilizing your platform.
Network Load Balancers
Network load balancers route events at the transport layer, the fourth layer of the OSI model. It has a very high capacity to scale requests and allows millions of requests per second. The load balancer component receives connection requests and selects targets from the user-defined ruleset. It then will open connections to selected targets on the port specified. Network load balancers handle TCP and UDP traffic using flow hash algorithms to determine individual connections.
The load balancers may be enabled to work within a certain availability zone where targets can only be registered in the same zone as the load balancer. Load balancers may also be registered as cross-zone where traffic can be sent to targets in any enabled availability zone. Using the cross-zone feature adds more redundancy and fault tolerance to your system. If targets in a single zone are not healthy, traffic is automatically directed to a different, healthy zone. Health checks should be configured to monitor and ensure requests are sent to only healthy targets.
Gateway Load Balancers
Gateway load balancers, route events at the network layer, the third layer of the OSI model. These load balancers are used to deploy, manage and scale virtual services like deep packet inspection systems and firewalls. They can distribute traffic while scaling virtual appliances with load demands.
Gateway load balancers must send traffic across VPC boundaries.They use specific endpoints set up only for gateway load balancer to accomplish this securely. These endpoints are VPC endpoints that provide a private connection between the virtual appliances in the provider VPC and the application servers in the consumer VPCs. AWS provides a list of supported partners that offer security appliances, though users are free to configure using other partners.
Metrics Available
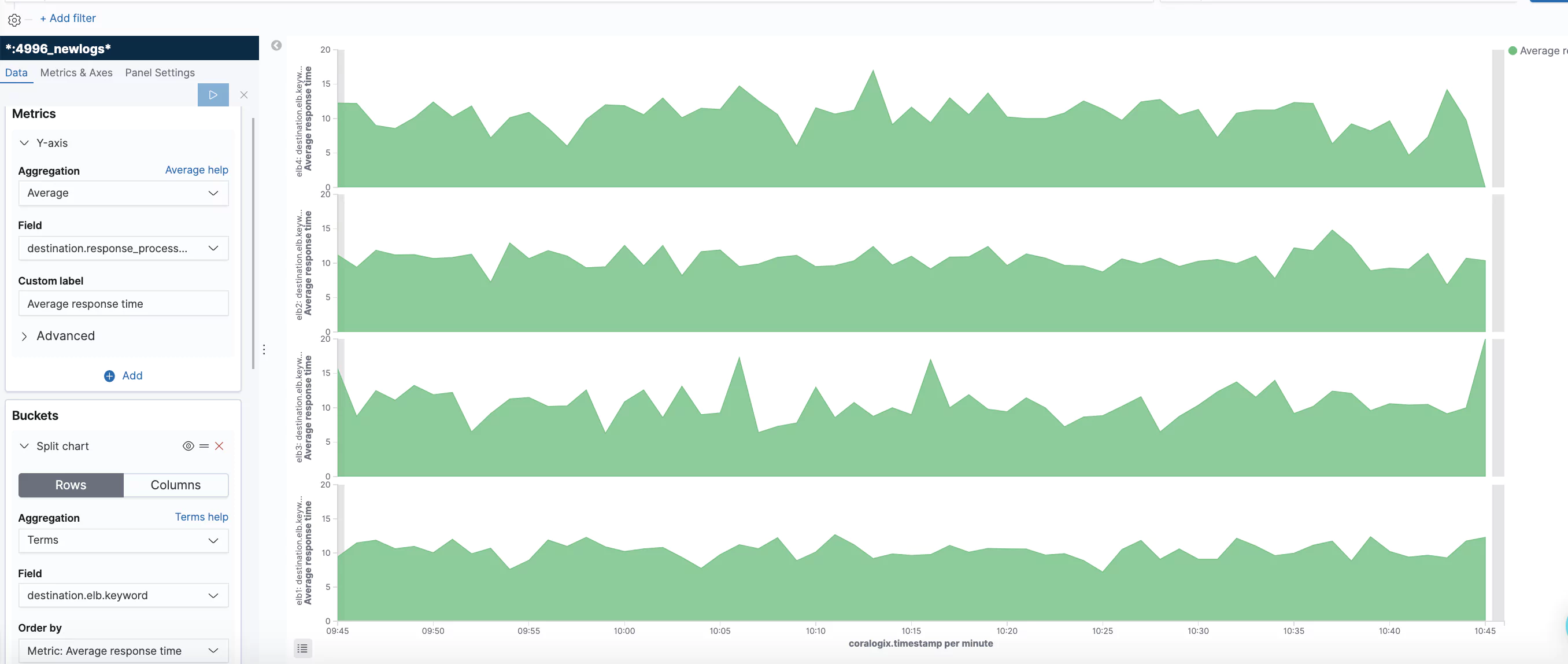
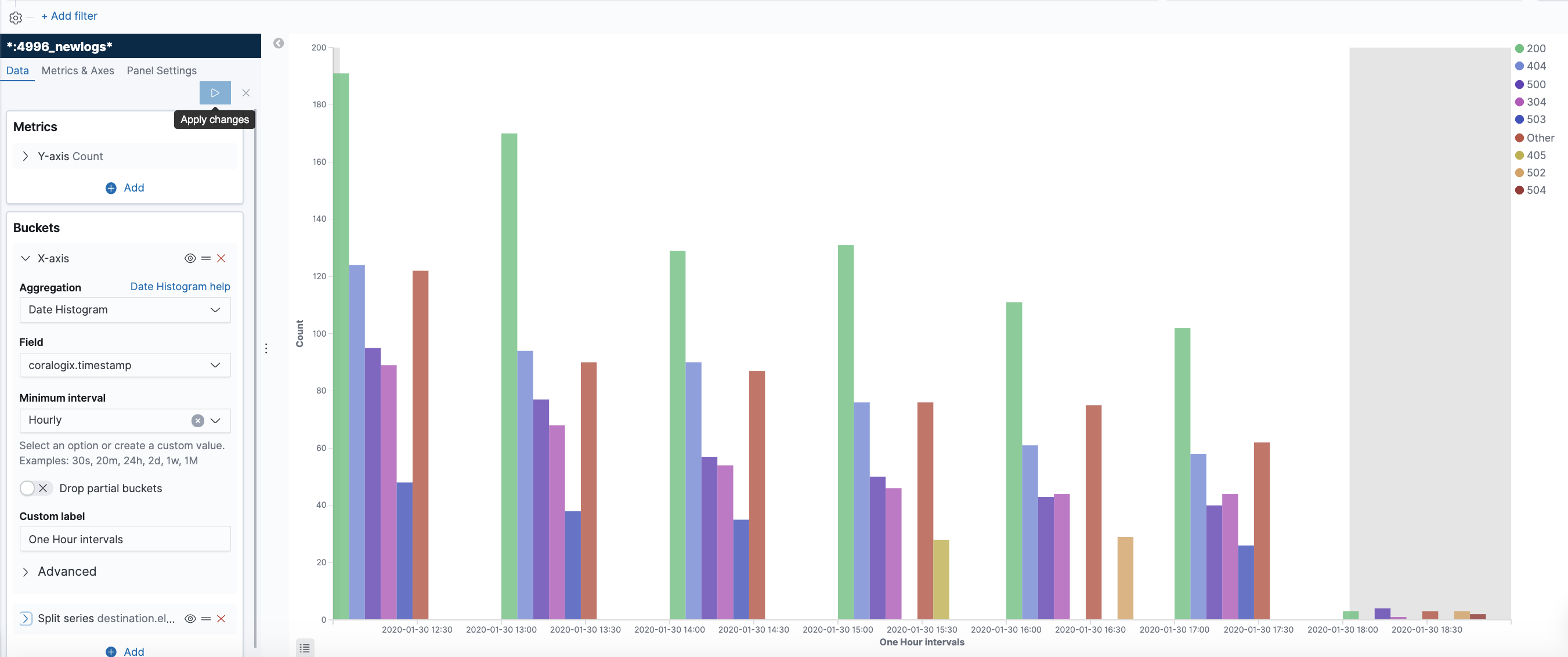
Metrics are measured on AWS every 60 seconds when requests flow through the load balancer. No metrics will be seen if the load balancer is not receiving traffic. CloudWatch intercepts and logs the metrics. You can create manual alarms in AWS or send the data to third-party services like Coralogix, where machine learning algorithms can provide insights into the health of your endpoints.
Metrics are provided for different components of the elastic load balancers. The load balancer, target, and authorization components have their own metrics. This list is not exhaustive but contains some of the metrics considered especially useful in observing the health of your load balancer network.
Load Balancer Metrics
These metrics are all for statistics originating from the load balancers directly and do not include responses generated from targets which are provided separately.
Statistical Metrics
Load balancer metrics show how the load balancer endpoint component is functioning.
- ActiveConnectionCount: The number of active TCP connections at any given time. These include connections between the client and load balancer as well as between load balancer and target. This metric should be watched to make sure your load balancer is scaling to meet your needs at any given time.
- ConsumedLCUs: The number of load balancer capacity units used at any given time. This determines the cost of the load balancer and should be watched closely to track associated costs.
- ProcessedBytes: The number of bytes the load balancer has processed over a period of time. This includes traffic over both IPv4 and IPv6 and includes traffic between the load balancer and clients, identity providers, and AWS Lambda functions.
HTTP Metrics
AWS provides several HTTP-specific metrics for each load balancer. Developers configure rules that determine how the load balancer will respond to incoming actions. Some of these rules will generate unique metrics so teams can count the number of events that trigger each rule type. The numbered HTTP metrics are also available from targets.
- HTTP_Fixed_Response_Count: Fixed response actions return custom HTTP response codes and can include a message optionally. This metric is the number of successful fixed-response actions over a given period of time.
- HTTP_Redirect_Count: Redirect actions will redirect client requests from the input URL to another. These can be temporary or permanent, depending on the setup. This metric is the number of successful redirect actions over a period of time.
- HTTP_Redirect_Url_Limit_Exceeded_Count: The redirect response location is returned in the response’s header data and has a maximum size of 8K Bytes. This error metric will log the number of redirect events that failed because the URL exceeded this size limit.
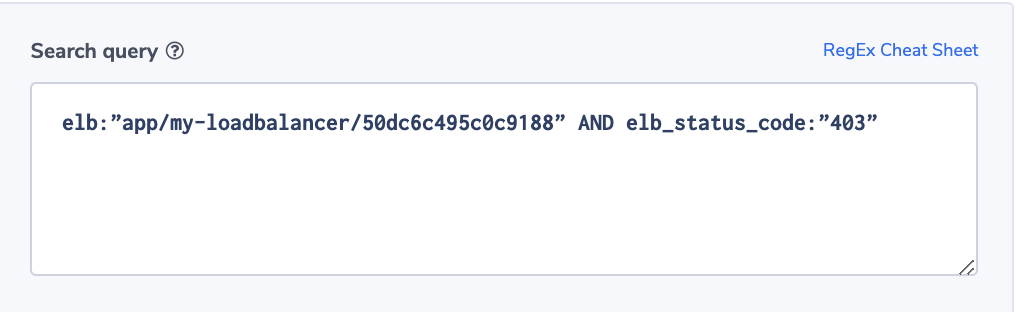
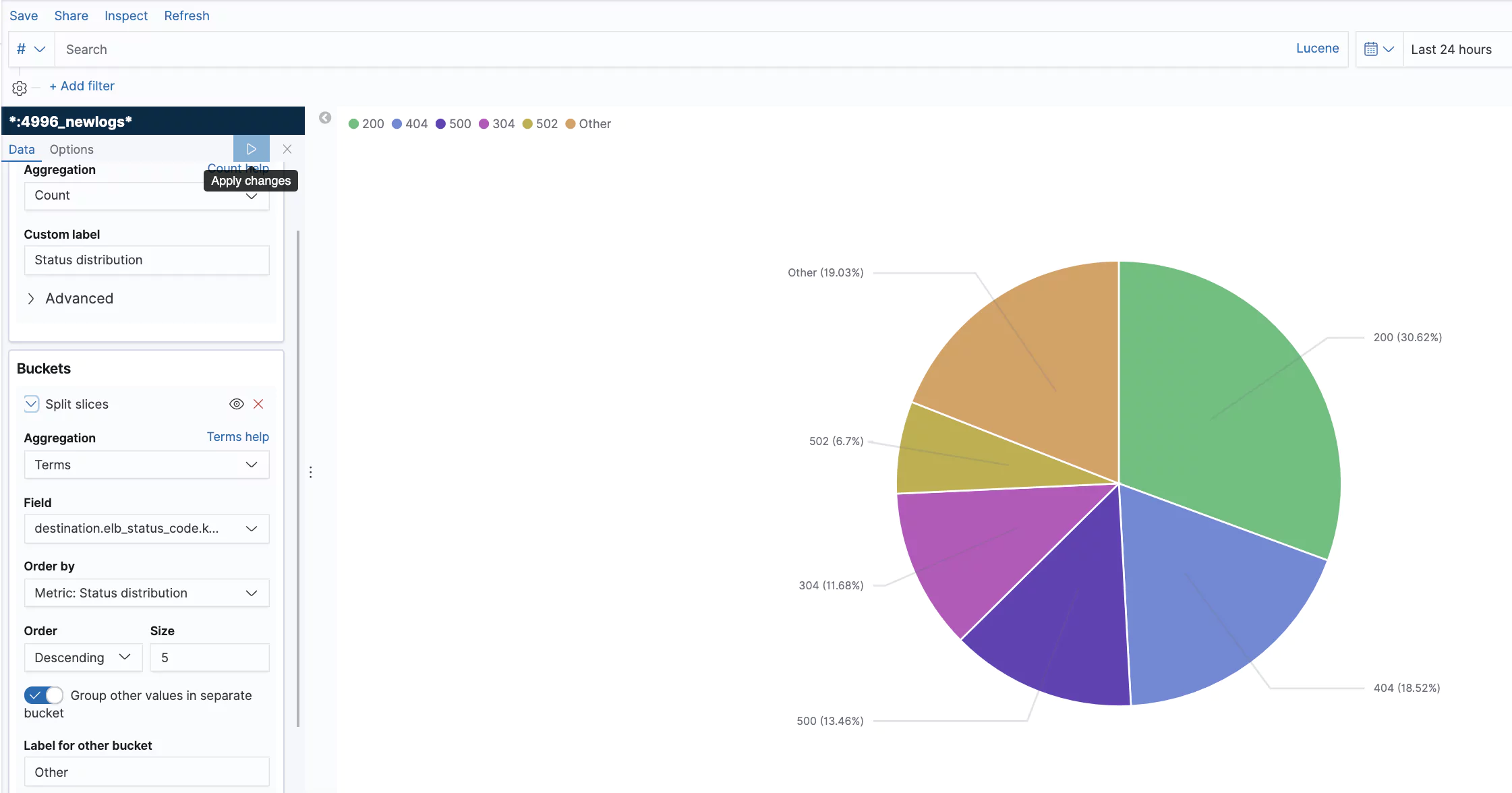
- HTTPCode_ELB_3XX_Count: The number of redirect codes originating from the load balancer.
- HTTPCode_ELB_4XX_Count: The number of 4xx HTTP errors originating from the load balancer. These are malformed or incomplete requests that the load balancer could not forward to the target.
- HTTPCode_ELB_5XX_Count: The number of 5xx HTTP errors originating from the load balancer. Internal errors in the load balancer cause these. Metrics are also available for some specific 5XX errors (500, 502, 503, and 504).
Error Metrics
- ClientTLSNegotiationErrorCount: The number of connection requests initiated by the client did not connect to the load balancer due to a TLS protocol error. Issues like an invalid server certificate could cause this.
- DesyncMitigationMode_NonCompliant_Request_Count: The number of requests that fail to comply with HTTP protocols
Target Metrics
Target metrics are logged for each target sent traffic from the load balancer. Targets provide all the listed HTTP code metrics provided for load balancers and those listed below.
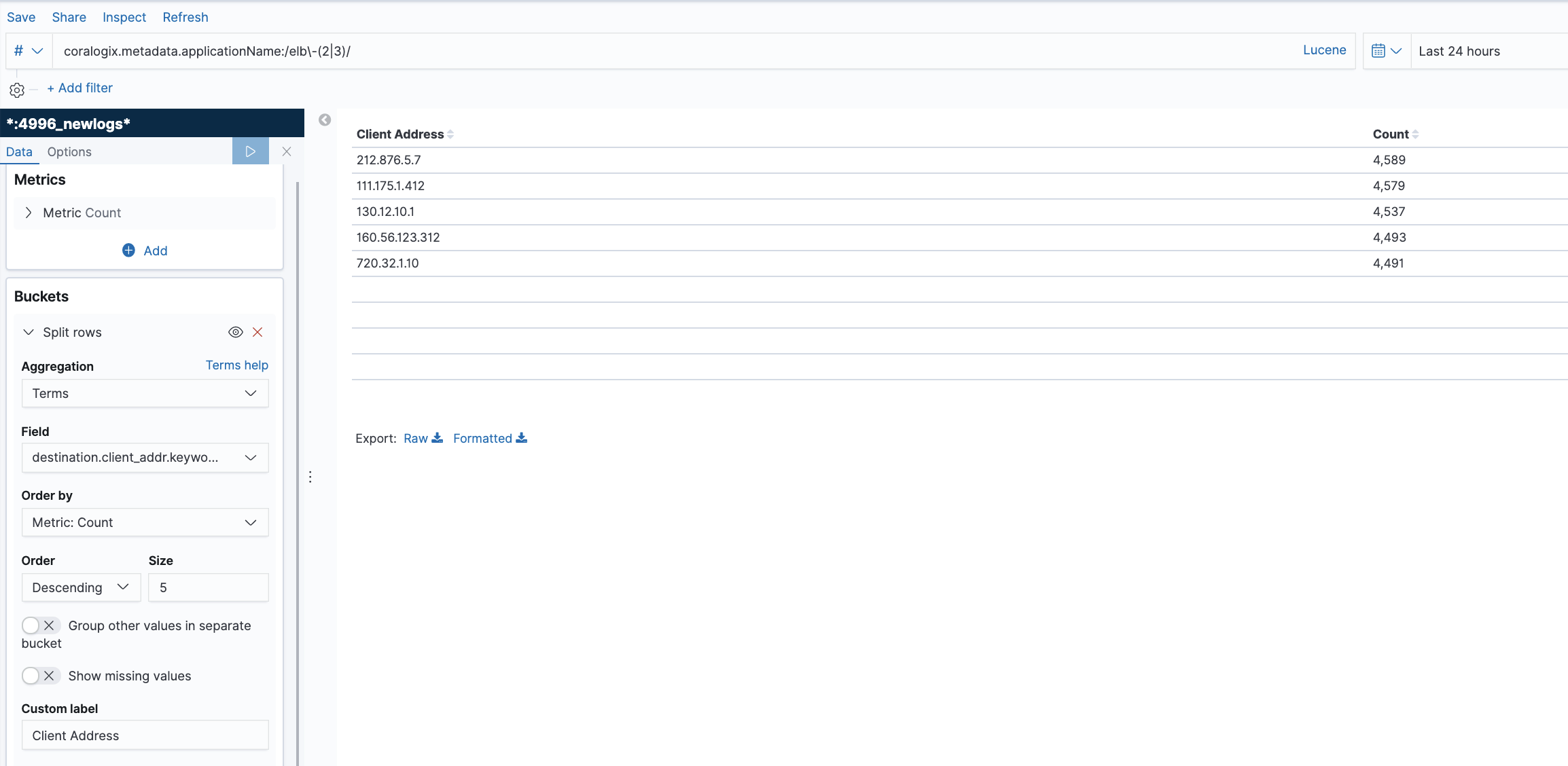
- HealthHostCount: The number of healthy targets linked to a load balancer.
- RequestCountPerTarget: The average number of requests sent to a specific target in a target group. This metric applies to any target type connected to the load balancer except AWS Lambda.
- TargetResponseTime: The number of seconds between when the request leaves the load balancer to when the target receives the request.
Authorization Metrics
Authorization metrics are essential for detecting potential attacks on your system. Many error metrics especially can show that nefarious calls are made against your endpoints. These metrics are critical to observe and set alarms when using Elastic load balancers.
Statistical Metrics
Some Authorization metrics are used to track the usage of the elastic load balancer. These include the following metrics
- ELBAuthLatency: The time taken to query the identity provider for user information and the ID token. This latency will either be the time to return the token when successful or the time to fail.
- ELBAuthRefreshTokenStatus: The number of times a refresh token is successfully used to provide a new ID token.
Error Metrics
There are three error metrics associated with authorization on elastic load balancers. Exact errors can be read in AWS Cloudwatch logs in the error_reason parameter.
- ELBAuthError: This metric is used for errors such as malformed authentication actions when a connection cannot be established with the identity provider, or another internal authentication error occurred.
- ELBAuthFailure: Authentication failures occur when identity provider access is denied to the user, or an authorization code is used multiple times.
- ELBAuthUserClaimsSizeExceeded: This metric shows how many times the identity provider returned user claims larger than 11K Bytes. Most browsers limit cookie sizes to 4K Bytes. When a cookie is more significant than 4K, AWS ELB logs will use separate shards to handle the size. Anything up to 11K is allowed, but larger cannot be handled and will throw a 500 error.
Summary
AWS elastic load balancers scale traffic from endpoints into your platform. It allows companies to truly scale their backend and ensure the needs of their customers are always met by providing the resources needed to support those customers are available. Elastic load balancers are available for scaling at different levels of the OSI networking model.
Developers can use all or some of the available metrics to analyze the traffic flowing through and the health of their elastic load balancer setup and its targets. Separate metrics are available for the load balancer, its targets, and authorization setup. Metrics can be manually checked using AWS CloudWatch. They can also be sent to external analytics tools to alert development teams when there may be problems with the system.