The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

Kubernetes monitoring (or “K8s”) is an open-source container orchestration tool developed by Google. In this tutorial, we will be leveraging the power of Kubernetes to look at how we can overcome some of the operational challenges of working with the Elastic Stack.
Since Elasticsearch (a core component of the Elastic Stack) is comprised of a cluster of nodes, it can be difficult to roll out updates, monitor and maintain nodes, and handle failovers. With Kubernetes, we can cover all of these points using built in features: the setup can be configured through code-based files (using a technology known as Helm), and the command line interface can be used to perform updates and rollbacks of the stack. Kubernetes also provides powerful and automatic monitoring capabilities that allows it to notify when failures occur and attempt to automatically recover from them.
This tutorial will walk through the setup from start to finish. It has been designed for working on a Mac, but the same can also be achieved on Windows and Linux (albeit with potential variation in commands and installation).
Prerequisites
Before we begin, there are a few things that you will need to make sure you have installed, and some more that we recommend you read up on. You can begin by ensuring the following applications have been installed on your local system.
While those applications are being installed, it is recommended you take the time to read through the following links to ensure you have a basic understanding before proceeding with this tutorial.
Let’s get started
As part of this tutorial, we will cover 2 approaches to cover the same problem. We will start by manually deploying individual components to Kubernetes and configuring them to achieve our desired setup. This will give us a good understanding of how everything works. Once this has been accomplished, we will then look at using Helm Charts. These will allow us to achieve the same setup but using YAML files that will define our configuration and can be deployed to Kubernetes with a single command.
The manual approach
Deploying Elasticsearch
First up, we need to deploy an Elasticsearch instance into our cluster. Normally, Elasticsearch would require 3 nodes to run within its own cluster. However, since we are using Minikube to act as a development environment, we will configure Elasticsearch to run in single node mode so that it can run on our single simulated Kubernetes node within Minikube.
So, from the terminal, enter the following command to deploy Elasticsearch into our cluster.
$ kubectl create deployment es-manual --image elasticsearch:7.8.0 [Output] deployment.apps/es-manual created
Note: I have used the name “es-manual” here for this deployment, but you can use whatever you like. Just be sure to remember what you have used.
Since we have not specified a full URL for a Docker registry, this command will pull the image from Docker Hub. We have used the image elasticsearch:7.8.0 – this will be the same version we use for Kibana and Logstash as well.
We should now have a Deployment and Pod created. The Deployment will describe what we have deployed and how many instances to deploy. It will also take care of monitoring those instances for failures and will restart them when they fail. The Pod will contain the Elasticsearch instance that we want to run. If you run the following commands, you can see those resources. You will also see that the instance is failing to start and is restarted continuously.
$ kubectl get deployments [Output] NAME READY UP-TO-DATE AVAILABLE AGE es-manual 1/1 1 1 8s $ kubectl get pods [Output] NAME READY STATUS RESTARTS AGE es-manual-d64d94fbc-dwwgz 1/1 Running 2 40s
Note: If you see a status of ContainerCreating on the Pod, then that is likely because Docker is pulling the image still and this may take a few minutes. Wait until that is complete before proceeding.
For more information on the status of the Deployment or Pod, use the kubectl describe or kubectl logs commands:
$ kubectl describe deployment es-manual $ kubectl describe pod es-manual-d64d94fbc-dwwgz $ kubectl logs –f deployments/es-manual
An explanation into these commands is outside of the scope of this tutorial, but you can read more about them in the official documentation: describe and logs.
In this scenario, the reason our Pod is being restarted in an infinite loop is because we need to set the environment variable to tell Elasticsearch to run in single node mode. We are unable to do this at the point of creating a Deployment, so we need to change the variable once the Deployment has been created. Applying this change will cause the Pod created by the Deployment to be terminated, so that another Pod can be created in its place with the new environment variable.
ERROR: [1] bootstrap checks failed [1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
The error taken from the deployment logs that describes the reason for the failure.
Unfortunately, the environment variable we need to change has the key “discovery.type”. The kubectl program does not accept “.” characters in the variable key, so we need to edit the Deployment manually in a text editor. By default, VIM will be used, but you can switch out your own editor (see here for instructions on how to do this). So, run the following command and add the following contents into the file:
$ kubectl edit deployment es-manual apiVersion: apps/v1 kind: Deployment ... containers: - name: elasticsearch env: - name: discovery.type value: single-node image: elasticsearch:7.8.0 imagePullPolicy: IfNotPresent ...
If you now look at the pods, you will see that the old Pod is being or has been terminated, and the new Pod (containing the new environment variable) will be created.
$ kubectl get pods [Output] NAME READY STATUS RESTARTS AGE es-manual-7d8bc4cf88-b2qr9 1/1 Running 0 7s es-manual-d64d94fbc-dwwgz 0/1 Terminating 8 21m
Exposing Elasticsearch
Now that we have Elasticsearch running in our cluster, we need to expose it so that we can connect other services to it. To do this, we will be using the
$ kubectl expose deployment es-manual --type NodePort --port 9200 [Output] service/es-manual exposed
This will have created a Kubernetes Service resource that exposes the port 9200 from our Elasticsearch Deployment resource: Elasticsearch’s HTTP port. This port will now be accessible through a port assigned in the cluster. To see this Service and the external port that has been assigned, run the following command:
$ kubectl get services [Output] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) es-manual NodePort 10.96.114.186 9200:30445/TCP kubernetes ClusterIP 10.96.0.1 443/TCP
As you can see, our Elasticsearch HTTP port has been mapped to external port 30445. Since we are running through Minikube, the external port will be for that virtual machine, so we will use the Minikube IP address and external port to check that our setup is working correctly.
$ curl https://$(minikube ip):30445
[Output]
{
"name" : "es-manual-7d8bc4cf88-b2qr9",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "1Sg_UWkBSAayesXMbZ0_DQ",
"version" : {
"number" : "7.8.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date" : "2020-06-14T19:35:50.234439Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Note: You may find that minikube ip returns the localhost IP address, which results in a failed command. If that happens, read this documentation and try to manually tunnel to the service(s) in question. You may need to open multiple terminals to keep these running, or launch each as background commands
There we have it – the expected JSON response from our Elasticsearch instance that tells us it is running correctly within Kubernetes.
Deploying Kibana
Now that we have an Elasticsearch instance running and accessible via the Minikube IP and assigned port number, we will spin up a Kibana instance and connect it to Elasticsearch. We will do this in the same way we have setup Elasticsearch: creating another Kubernetes Deployment resource.
$ kubectl create deployment kib-manual --image kibana:7.8.0 [Output] deployment.apps/kib-manual created
Like with the Elasticsearch instance, our Kibana instance isn’t going to work straight away. The reason for this is that it doesn’t know where the Elasticsearch instance is running. By default, it will be trying to connect using the URL https://elasticsearch:9200. You can see this by checking in the logs for the Kibana pod.
# Find the name of the pod
$ kubectl get pods
[Output]
NAME READY STATUS RESTARTS AGE
es-manual-7d8bc4cf88-b2qr9 1/1 Running 2 3d1h
kib-manual-5d6b5ffc5-qlc92 1/1 Running 0 86m
# Get the logs for the Kibana pod
$ kubectl logs pods/kib-manual-5d6b5ffc5-qlc92
[Output]
...
{"type":"log","@timestamp":"2020-07-17T14:15:18Z","tags":["warning","elasticsearch","admin"],"pid":11,"message":"Unable to revive connection: https://elasticsearch:9200/"}
...
The URL of the Elasticsearch instance is defined via an environment variable in the Kibana Docker Image, just like the mode for Elasticsearch. However, the actual key of the variable is ELASTICSEARCH_HOSTS, which contains all valid characters to use the kubectl command for changing an environment variable in a Deployment resource. Since we now know we can access Elasticsearch’s HTTP port via the host mapped port 30445 on the Minikube IP, we can update Kibana Logstash to point to the Elasticsearch instance.
$ kubectl set env deployments/kib-manual ELASTICSEARCH_HOSTS=https://$(minikube ip):30445 [Output] deployment.apps/kib-manual env updated
Note: We don’t actually need to use the Minikube IP to allow our components to talk to each other. Because they are living within the same Kubernetes cluster, we can actually use the Cluster IP assigned to each Service resource (run kubectl get services to see what the Cluster IP addresses are). This is particularly useful if your setup returns the localhost IP address for your Minikube installation. In this case, you will not need to use the Node Port, but instead use the actual container port
This will trigger a change in the deployment, which will result in the existing Kibana Pod being terminated, and a new Pod (with the new environment variable value) being spun up. If you run kubectl get pods again, you should be able to see this new Pod now. Again, if we check the logs of the new Pod, we should see that it has successfully connected to the Elasticsearch instance and is now hosting the web UI on port 5601.
$ kubectl logs –f pods/kib-manual-7c7f848654-z5f9c
[Output]
...
{"type":"log","@timestamp":"2020-07-17T14:45:41Z","tags":["listening","info"],"pid":6,"message":"Server running at https://0:5601"}
{"type":"log","@timestamp":"2020-07-17T14:45:41Z","tags":["info","http","server","Kibana"],"pid":6,"message":"http server running at https://0:5601"}
Note: It is often worth using the –follow=true, or just –f, command option when viewing the logs here, as Kibana may take a few minutes to start up.
Accessing the Kibana UI
Now that we have Kibana running and communicating with Elasticsearch, we need to access the web UI to allow us to configure and view logs. We have already seen that it is running on port 5601, but like with the Elasticsearch HTTP port, this is internal to the container running inside of the Pod. As such, we need to also expose this Deployment resource via a Service.
$ kubectl expose deployment kib-manual --type NodePort --port 5601 [Output] service/kib-manual exposed
That’s it! We should now be able to view the web UI using the same Minikube IP as before and the newly mapped port. Look at the new service to get the mapped port.
$ kubectl get services [Output] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) es-manual NodePort 10.96.114.186 9200:30445/TCP kib-manual NodePort 10.96.112.148 5601:31112/TCP kubernetes ClusterIP 10.96.0.1 443/TCP
Now navigate in the browser to the URL: https://192.168.99.102:31112/status to check that the web UI is running and Elasticsearch is connected properly.
Note: The IP address 192.168.99.102 is the value returned when running the command minikube ip on its own.
Deploying Logstash
The next step is to get Logstash running within our setup. Logstash will operate as the tool that will collect logs from our application and send them through to Elasticsearch. It provides various benefits for filtering and re-formatting log messages, as well as collecting from various sources and outputting to various destinations. For this tutorial, we are only interested in using it as a pass-through log collector and forwarder.
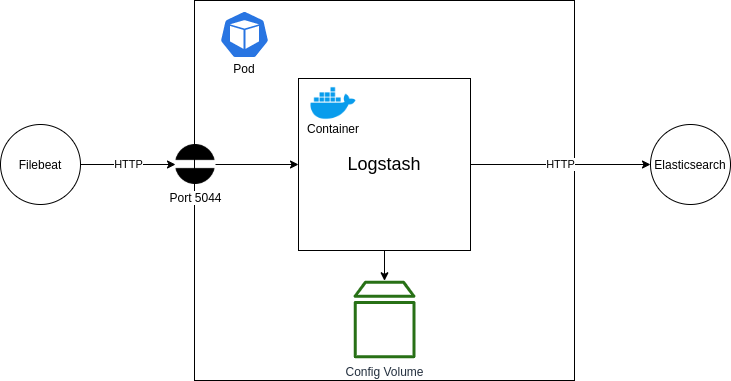
In the above diagram, you can see our desired setup. We are aiming to deploy a Logstash container into a new Pod. This container will be configured to listen on port 5044 for log entries being sent from a Filebeat application (more on this later). Those log messages will then be forwarded straight onto our Elasticsearch Kibana Logstash instance that we setup earlier, via the HTTP port that we have exposed.
To achieve this setup, we are going to have to leverage the Kubernetes YAML files. This is a more verbose way of creating deployments and can be used to describe various resources (such as Deployments, Services, etc) and create them through a single command. The reason we need to use this here is that we need to configure a volume for our Logstash container to access, which is not possible through the CLI commands. Similarly, we could have also used this approach to reduce the number of steps required for the earlier setup of Elasticsearch and Kibana; namely the configuration of environment variables and separate steps to create Service resources to expose the ports into the containers.
So, let’s begin – create a file called logstash.conf and enter the following:
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["https://192.168.99.102:30445"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
Note: The IP and port combination used for the Elasticsearch hosts parameter come from the Minikube IP and exposed NodePort number of the Elasticsearch Service resource in Kubernetes.
Next, we need to create a new file called deployment.yml. Enter the following Kubernetes Deployment resource YAML contents to describe our Logstash Deployment.
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: log-manual
spec:
replicas: 1
selector:
matchLabels:
name: log-manual
template:
metadata:
labels:
name: log-manual
spec:
hostname: log-manual
containers:
- name: log-manual
ports:
- containerPort: 5044
name: filebeat
image: logstash:7.8.0
volumeMounts:
- name: log-manual-pipeline
mountPath: /usr/share/logstash/pipeline/
command:
- logstash
volumes:
- name: log-manual-pipeline
configMap:
name: log-manual-pipeline
items:
- key: logstash.conf
path: logstash.conf
---
You may notice that this Deployment file references a ConfigMap volume. Before we create the Deployment resource from this file, we need to create this ConfigMap. This volume will contain the logstash.conf file we have created, which will be mapped to the pipeline configuration folder within the Logstash container. This will be used to configure our required pass-through pipeline. So, run the following command:
$ kubectl create configmap log-manual-pipeline --from-file ./logstash.conf [Output] configmap/log-manual-pipeline created
We can now create the Deployment resource from our deployment.yml file.
$ kubectl create –f ./deployment.yml [Output] deployment.apps/log-manual created
To check that our Logstash instance is running properly, follow the logs from the newly created Pod.
$ kubectl get pods
[Output]
NAME READY STATUS RESTARTS AGE
es-manual-7d8bc4cf88-b2qr9 1/1 Running 3 7d2h
kib-manual-7c7f848654-z5f9c 1/1 Running 1 3d23h
log-manual-5c95bd7497-ldblg 1/1 Running 0 4s
$ kubectl logs –f log-manual-5c95bd7497-ldblg
[Output]
...
... Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"}
... Pipeline started {"pipeline.id"=>"main"}
... Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
... Starting server on port: 5044
... Successfully started Logstash API endpoint {:port=>9600}
Note: You may notice errors stating there are “No Available Connections” to the Elasticsearch instance endpoint with the URL https://elasticsearch:9200/. This comes from some default configuration within the Docker Image, but does not affect our pipeline, so can be ignored in this case.
Expose the Logstash Filebeats port
Now that Logstash is running and listening on container port 5044 for Filebeats log message entries, we need to make sure this port is mapped through to the host so that we can configure a Filebeats instance in the next section. To achieve this, we need another Service resource to expose the port on the Minikube host. We could have done this inside the same deployment.yml file, but it’s worth using the same approach as before to show how the resource descriptor and CLI commands can be used in conjunction.
As with the earlier steps, run the following command to expose the Logstash Deployment through a Service resource.
$ kubectl expose deployment log-manual --type NodePort --port 5044 [Output] service/log-manual exposed
Now check that the Service has been created and the port has been mapped properly.
$ kubectl get services [Output] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) es-manual NodePort 10.96.114.186 9200:30445/TCP kib-manual NodePort 10.96.112.148 5601:31112/TCP kubernetes ClusterIP 10.96.0.1 443/TCP log-manual NodePort 10.96.254.84 5044:31010/TCP
As you can see, the container port 5044 has been mapped to port 31010 on the host. Now we can move onto the final step: configuring our application and a Sidecar Filebeats container to pump out log messages to be routed through our Logstash instance into Elasticsearch.
Application
Right, it’s time to setup the final component: our application. As I mentioned in the previous section, we will be using another Elastic Stack component called Filebeats, which will be used to monitor the log entries written by our application into a log file and then forward them onto Logstash.
There are a number of different ways we could structure this, but the approach I am going to walk through is by deploying both our application and the Filebeat instance as separate containers within the same Pod. We will then use a Kubernetes volume known as an Empty Directory to share access to the log file that the application will write to and Filebeats will read from. The reason for using this type of volume is that its lifecycle will be directly linked to the Pod. If you wish to persist the log data outside of the Pod, so that if the Pod is terminated and re-created the volume remains, then I would suggest looking at another volume type, such as the Local volume.
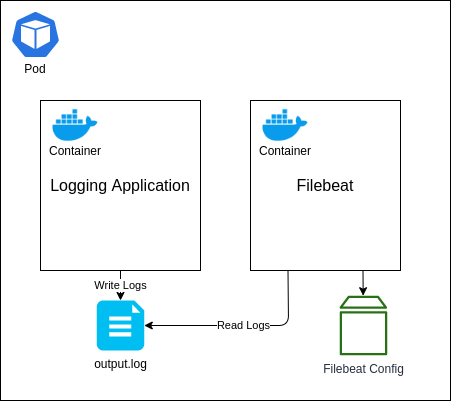
To begin with, we are going to create the configuration file for the Filebeats instance to use. Create a file named filebeat.yml and enter the following contents.
filebeat.inputs:
- type: log
paths:
- /tmp/output.log
output:
logstash:
hosts: [ "192.168.99.102:31010" ]
This will tell Filebeat to monitor the file /tmp/output.log (which will be located within the shared volume) and then output all log messages to our Logstash instance (notice how we have used the IP address and port number for Minikube here).
Now we need to create a ConfigMap volume from this file.
$ kubectl create configmap beat-manual-config --from-file ./filebeat.yml [Output] configmap/beat-manual-config created
Next, we need to create our Pod with the double container setup. For this, similar to the last section, we are going to create a deployment.yml file. This file will describe our complete setup so we can build both containers together using a single command. Create the file with the following contents:
kind: Deployment
apiVersion: apps/v1
metadata:
name: logging-app-manual
spec:
replicas: 1
selector:
matchLabels:
name: logging-app-manual
template:
metadata:
labels:
name: logging-app-manual
spec:
hostname: logging-app-manual
containers:
- name: beat-manual
image: elastic/filebeat:7.8.0
args: [
"-c", "/etc/filebeat/filebeat.yml",
"-e"
]
volumeMounts:
- name: beat-manual-config
mountPath: /etc/filebeat/
- name: manual-log-directory
mountPath: /tmp/
- name: logging-app-manual
image: sladesoftware/log-application:latest
volumeMounts:
- name: manual-log-directory
mountPath: /tmp/
volumes:
- name: beat-manual-config
configMap:
name: beat-manual-config
items:
- key: filebeat.yml
path: filebeat.yml
- name: manual-log-directory
emptyDir: {}
I won’t go into too much detail here about how this works, but to give a brief overview this will create both of our containers within a single Pod. Both containers will share a folder mapped to the /tmp path, which is where the log file will be written to and read from. The Filebeat container will also use the ConfigMap volume that we have just created, which we have specified for the Filebeat instance to read the configuration file from; overwriting the default configuration.
You will also notice that our application container is using the Docker Image
To create this Deployment resource, run the following command:
$ kubectl create –f ./deployment.yml [Output] deployment.apps/logging-app-manual created
And that’s it! You should now be able to browse to the Kibana dashboard in your web browser to view the logs coming in. Make sure you first create an Index Pattern to read these logs – you should need a format like filebeat*.
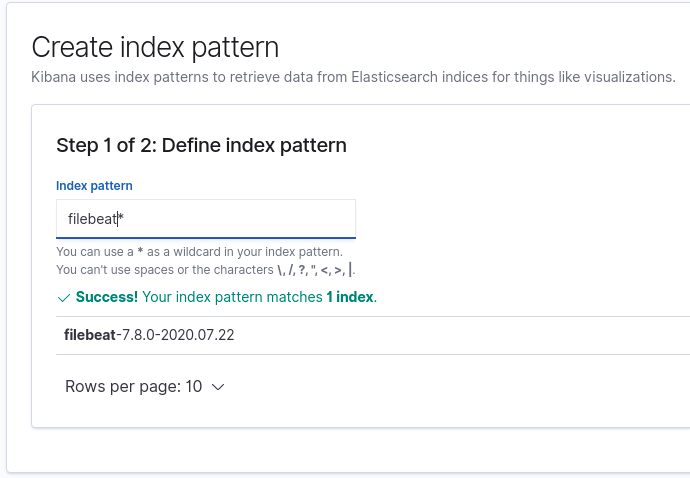
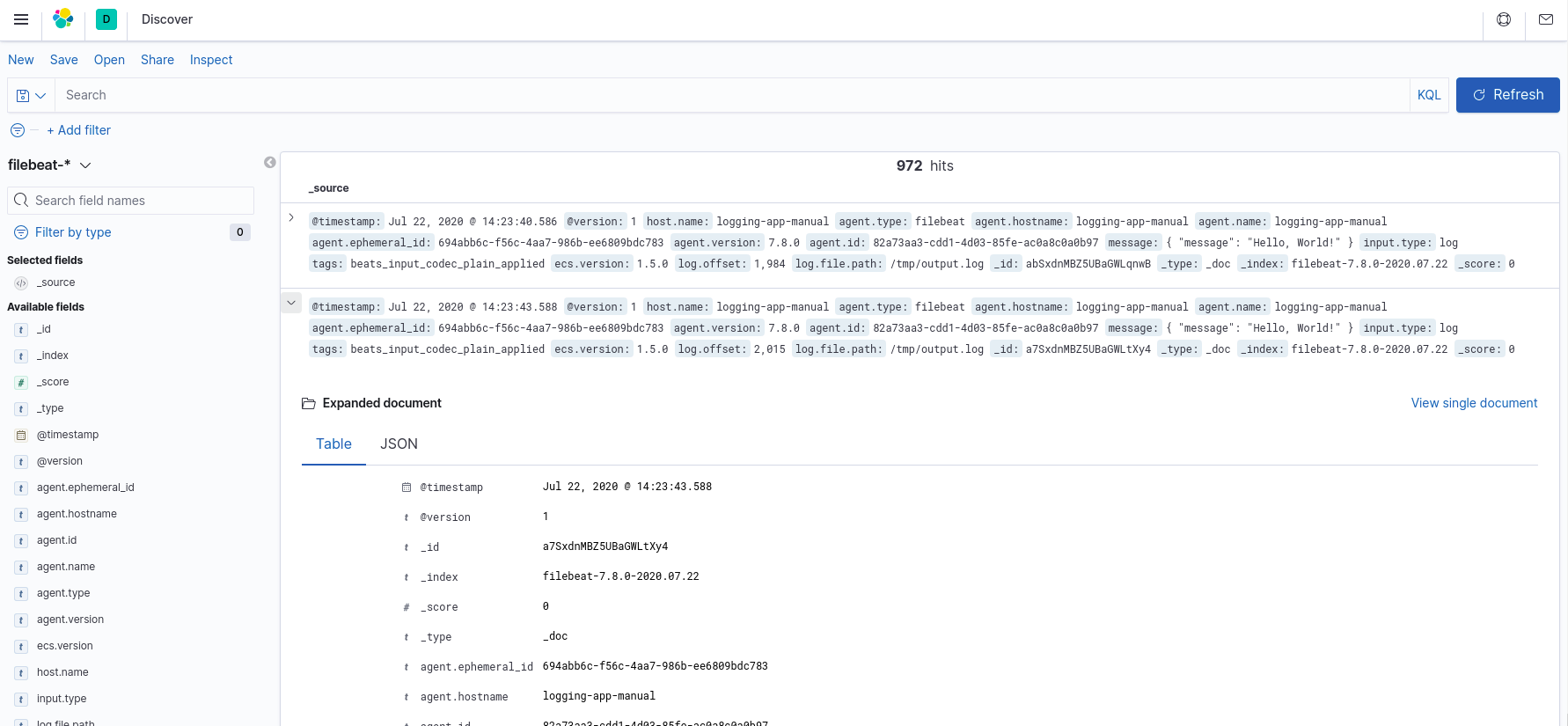
Once you have created this Index Pattern, you should be able to view the log messages as they come into Elasticsearch over on the Discover page of Kibana.
Using Helm charts
If you have gone through the manual tutorial, you should now have a working Elastic Stack setup with an application outputting log messages that are collected and stored in Elasticsearch and viewable in Kibana. However, all of that was done through a series of commands using the Kubernetes CLI, and Kubernetes resource description files written in YAML. Which is all a bit tedious.
The aim of this section is to achieve the exact same Elastic Stack setup as before, only this time we will be using something called Helm. This is a technology built for making it easier to setup applications within a Kubernetes cluster. Using this approach, we will configure our setup configuration as a package known as a Helm Chart, and deploy our entire setup into Kubernetes with a single command!
I won’t go into a lot of detail here, as most of what will be included has already been discussed in the previous section. One point to mention is that Helm Charts are comprised of Templates. These templates are the same YAML files used to describe Kubernetes resources, with one exception: they can include the Helm template syntax, which allows us to pass through values from another file, and apply special conditions. We will only be using the syntax for value substitution here, but if you want more information about how this works, you can find more in the official documentation.
Let’s begin. Helm Charts take a specific folder structure. You can either use the Helm CLI to create a new Chart for you (by running the command helm create <NAME>), or you can set this up manually. Since the creation command also creates a load of example files that we aren’t going to need, we will go with the manual approach for now. As such, simply create the following file structure:
. ├── Chart.yaml ├── filebeat.yml ├── logstash.conf ├── templates │ ├── elasticsearch.yaml │ ├── kibana.yaml │ ├── logging-app-and-filebeat.yaml │ └── logstash.yaml └── values.yaml
Now, follow through each of the following files, entering in the contents given. You should see that the YAML files under the templates/ folder are very familiar, except that they now contain the Service and ConfigMap definitions that we previously created using the Kubernetes CLI.
Chart.yaml
apiVersion: v2 name: elk-auto description: A Helm chart for Kubernetes type: application version: 0.1.0
This file defines the metadata for the Chart. You can see that it indicates which version of the Kubernetes API it is using. It also names and describes the application. This is similar to a package.json file in a Node.js project in that it defines metadata used when packaging the Chart into a redistributable and publishable format. When installing Charts from a repository, it is this metadata that is used to find and describe said Charts. For now, though, what we enter here isn’t very important as we won’t be packaging or publishing the Chart.
filebeat.yml
filebeat.inputs:
- type: log
paths:
- /tmp/output.log
output:
logstash:
hosts: [ "${LOGSTASH_HOSTS}" ]
This is the same Filebeat configuration file we used in the previous section. The only difference is that we have replaced the previously hard-coded Logstash URL with the environment variable: LOGSTASH_HOSTS. This will be set within the Filebeat template and resolved during Chart installation.
logstash.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["${ELASTICSEARCH_HOSTS}"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
This is the same Logstash configuration file we used previously. The only modification, is that we have replaced the previously hard-coded Elasticsearch URL with the environment variable: ELASTICSEARCH_HOSTS. This variable is set within the template file and will be resolved during Chart installation.
templates/elasticsearch.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: es-auto
labels:
name: es-auto
spec:
replicas: 1
selector:
matchLabels:
name: es-auto
template:
metadata:
labels:
name: es-auto
spec:
containers:
- name: es-auto
image: elasticsearch:7.8.0
ports:
- containerPort: 9200
name: http
env:
- name: discovery.type
value: single-node
---
apiVersion: v1
kind: Service
metadata:
labels:
name: es-auto
name: es-auto
spec:
selector:
name: es-auto
type: NodePort
ports:
- nodePort: {{ .Values.ports.elasticsearch }}
port: 9200
protocol: TCP
targetPort: 9200
Here, we are creating 2 Kubernetes resources:
- A Deployment that spins up 1 Pod containing the Elasticsearch container
- A Service that exposes the Elasticsearch port 9200 on the host (Minikube) that both Logstash and Kibana will use to communicate with Elasticsearch via HTTP
templates/kibana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kib-auto
labels:
name: kib-auto
spec:
replicas: 1
selector:
matchLabels:
name: kib-auto
template:
metadata:
labels:
name: kib-auto
spec:
containers:
- name: kib-auto
image: kibana:7.8.0
ports:
- containerPort: 5601
name: http
env:
- name: ELASTICSEARCH_HOSTS
value: https://{{ .Values.global.hostIp }}:{{ .Values.ports.elasticsearch }}
---
apiVersion: v1
kind: Service
metadata:
name: kib-auto
labels:
name: kib-auto
spec:
selector:
name: kib-auto
type: NodePort
ports:
- nodePort: {{ .Values.ports.kibana }}
port: 5601
protocol: TCP
targetPort: 5601
Here, we are creating 2 Kubernetes resources:
- A Deployment that spins up 1 Pod containing the Kibana container; configured to point to our exposed Elasticsearch instance
- A Service that exposes the Kibana port 5601 on the host (Minikube) so that we can view the Kibana Dashboard via the web browser
templates/logging-app-and-filebeat.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-auto
labels:
name: app-auto
spec:
replicas: 1
selector:
matchLabels:
name: app-auto
template:
metadata:
labels:
name: app-auto
spec:
containers:
- name: app-auto
image: sladesoftware/log-application:latest
volumeMounts:
- name: log-output
mountPath: /tmp/
- name: beat-auto
image: elastic/filebeat:7.8.0
env:
- name: LOGSTASH_HOSTS
value: {{ .Values.global.hostIp }}:{{ .Values.ports.logstash }}
args: [
"-c", "/etc/filebeat/filebeat.yml",
"-e"
]
volumeMounts:
- name: log-output
mountPath: /tmp/
- name: beat-config
mountPath: /etc/filebeat/
volumes:
- name: log-output
emptyDir: {}
- name: beat-config
configMap:
name: beat-config
items:
- key: filebeat.yml
path: filebeat.yml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: beat-config
data:
filebeat.yml: |
{{ .Files.Get "filebeat.yml" | indent 4 }}
Here, we are creating 2 Kubernetes resources:
- A Deployment, which spins up 1 Pod containing 2 containers: 1 for our application and another for Filebeat; the latter of which is configured to point to our exposed Logstash instance
- A ConfigMap containing the Filebeat configuration file
We can also see that a Pod-level empty directory volume has been configured to allow both containers to access the same /tmp directory. This is where the output.log file will be written to from our application, and read from by Filebeat.
templates/logstash.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: log-auto
labels:
name: log-auto
spec:
replicas: 1
selector:
matchLabels:
name: log-auto
template:
metadata:
labels:
name: log-auto
spec:
containers:
- name: log-auto
image: logstash:7.8.0
ports:
- containerPort: 5044
name: filebeat
env:
- name: ELASTICSEARCH_HOSTS
value: https://{{ .Values.global.hostIp }}:{{ .Values.ports.elasticsearch }}
volumeMounts:
- name: log-auto-pipeline
mountPath: /usr/share/logstash/pipeline/
command:
- logstash
volumes:
- name: log-auto-pipeline
configMap:
name: log-auto-pipeline
items:
- key: logstash.conf
path: logstash.conf
---
apiVersion: v1
kind: ConfigMap
metadata:
name: log-auto-pipeline
data:
logstash.conf: |
{{ .Files.Get "logstash.conf" | indent 4 }}
---
apiVersion: v1
kind: Service
metadata:
name: log-auto
labels:
name: log-auto
spec:
selector:
name: log-auto
type: NodePort
ports:
- nodePort: {{ .Values.ports.logstash }}
port: 5044
protocol: TCP
targetPort: 5044
Here, we can see that we have created 3 Kubernetes resources:
- A Deployment, which spins up 1 Pod containing the Logstash container; configured to point to our exposed Elasticsearch instance
- A ConfigMap containing the Logstash configuration file
- A Service to expose the Logstash port 5044 on the host so that Filebeat can access it via HTTP
values.yaml
global: hostIp: 127.0.0.1 ports: elasticsearch: 31996 kibana: 31997 logstash: 31998
This file contains the default values for all of the variables that are accessed in each of the template files. You can see that we have explicitly defined the ports we wish to map the container ports to on the host (I.e. Minikube). The hostIp variable allows us to inject the Minikube IP when we install the Chart. You may take a different approach in production, but this satisfies the aim of this tutorial.
Now that you have created each of those files in the aforementioned folder structure, run the following Helm command to install this Chart into your Kubernetes cluster.
$ helm install elk-auto . --set global.hostIp=$(minikube ip) [Output] NAME: elk-auto LAST DEPLOYED: Fri Jul 24 12:40:21 2020 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None
Give it a few minutes for all of the components fully start up (you can check the container logs through the Kubernetes CLI if you want to watch it start up) and then navigate to the URL https://<MINIKUBE IP>:31997 to view the Kibana dashboard. Go through the same steps as before with creating an Index Pattern and you should now see your logs coming through the same as before.
That’s it! We have managed to setup the Elastic Stack within a Kubernetes cluster. We achieved this in two ways: manually by running individual Kubernetes CLI commands and writing some resource descriptor files, and sort of automatically by creating a Helm Chart; describing each resource and then installing the Chart using a single command to setup the entire infrastructure. One of the biggest benefits of using a Helm Chart approach is that all resources are properly configured (such as with environment variables) from the start, rather than the manual approach we took where we had to spin up Pods and containers first in an erroring state, then reconfigure the environment variables, and wait for them to be terminated and re-spun up.
What’s next?
Now we have seen how to set up the Elastic Stack within a Kubernetes cluster, where do we go with it next? The Elastic Stack is a great tool to use when setting up a centralized logging approach. You can delve more into this by reading this article that describes how to use a similar setup but covers a few different logging techniques. Beyond this, there is a wealth of information out there to help take this setup to production environments and also explore further options regarding packaging and publishing Helm Charts and building your resources as a set of reusable Charts.