
DevOps Security: Challenges and Best Practices
With the shift from traditional monolithic applications to the distributed microservices of DevOps, there is a need for a similar change in operational security policies. For…

It was a cloudy winter morning when I had arrived at the office and found, to our horror, that a Kubernetes cluster was suffering from extremely high CPU and network usage and had become almost completely non-functional.
To make things worse, restarting the nodes (the go-to DevOp solution), seemed to have absolutely no effect on the issue. Something was poisoning the network and we had to find out what it was and fast.
The first thing we did was look at the logs and sure enough, we discovered an out of memory message:

Now, before resorting to any dark and perhaps satanic rituals that involve sacrificing children, we decided to run “top” (the Linux tool) on one of the nodes to understand it better.
The result really knocked us off our feet: a process named “protokube” which usually behaves nicely all of a sudden went berserk and started consuming between 200% to 300% of CPU usage. We also ran “netstat -plan | grep <protokube_pid>” to see which ports it was listening to or communicating on and found out it was port 3999/TCP.
That was suspicious indeed but we wanted to be certain that we found the real culprit, so we ran tcpdump to capture some traffic from one of the nodes on port 3999/TCP and then used Wireshark to understand how much of the total traffic was generated by Protokube.
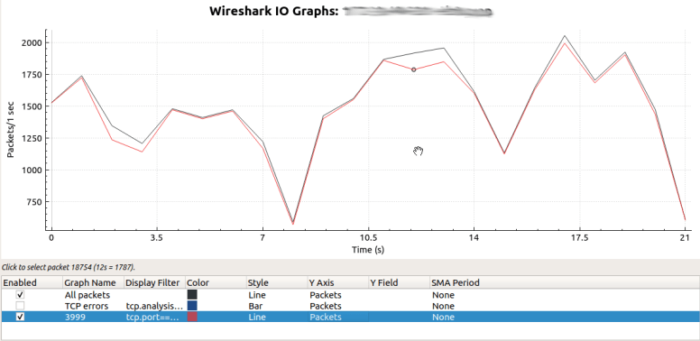
From the chart above it’s evident that most of the node’s traffic actually goes through port 3999, which means that it’s being sent and received by the Protokube process. So, we knew that this process was responsible for the issue, but what does the process do in the first place?
A quick google search and we could clearly see the list of Protokube’s tasks:
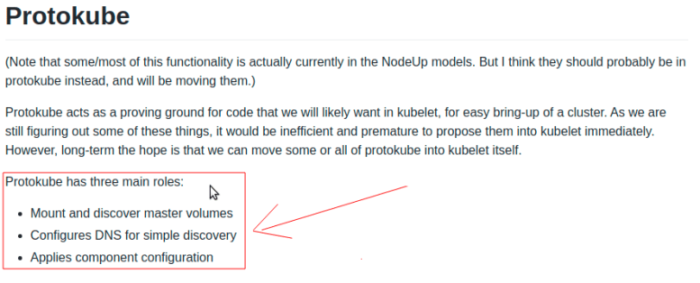
It soon became clear that we could rule out the first and last tasks as they’re most likely not related to our case. This left us with “Configures DNS for simple discovery” but how does it actually work?
Our next step was to find out what useful information we could get from the traffic data to better understand how Protokube configures DNS for simple discovery.
While reviewing the raw traffic in Wireshark and looking for clues, we noticed the following communication:

As you can see above, the communication starts with the text “weave..weave”. After searching we found that this type of Protokube traffic uses the Weave library internally.
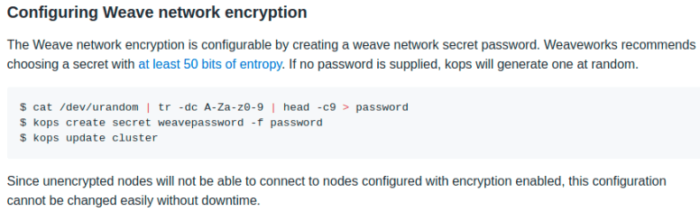
So now we understand why we couldn’t decipher the raw traffic (i.e. due to the Weave network encryption), but we’re still left with the original question of how Protokube configures the DNS for simple discovery?
A few more searches and a few cups of tea later we found that Protokube uses Gossip DNS encrypted with Weave and runs on port 3999/TCP and 3998/TCP. For those who aren’t familiar, Gossip is designed to handle name resolution in a decentralized manner to keep up with fast-changing containerized environments.
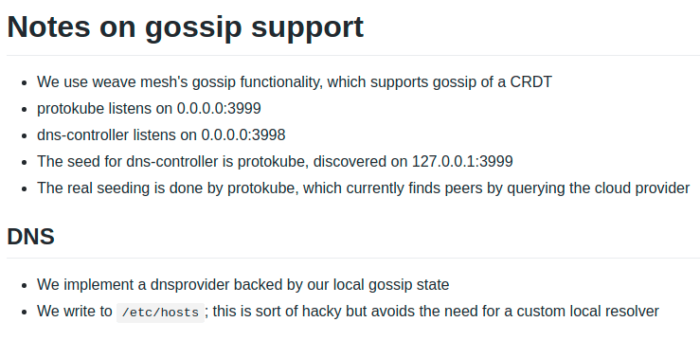
Now that we finally knew what the Protokube process actually did and how it related to the traffic we saw on port 3999/TCP, there was still the original question we needed to answer: why was the Protokube process behaving so badly and how to address it?
To find the answer, we had to look deeper and analyze the actual communication between the nodes on port 3999/TCP. Here’s an example of communication we found:
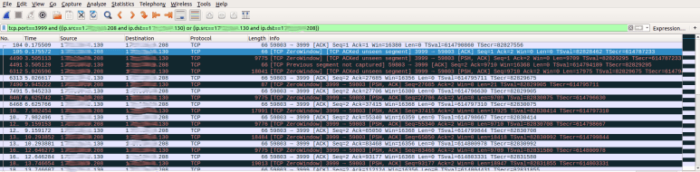
As you can see from the above screenshot, the communication starts with the node 1xx.xx.xx.130 that tries to connect to the node at 1xx.xx.xx.208 on port 3999/TCP at packet no. 6313 and as soon as it’s ready to send Gossip DNS data, the node at 1xx.xx.xx.208 responds with a zero-length TCP Window Size.
What exactly is a TCP window size? The TCP window size is a throttling mechanism built into the TCP protocol to avoid overloading the recipient. In order to demonstrate this, let’s consider the following example. Computer A wants to send data to computer B over TCP port 3999. Here’s how the communication will typically look like:
But what happens if, for example, computer B cannot handle the incoming traffic at that particular moment (e.g. due to temporary server overload)?
This is exactly what the TCP Window Size aims to solve. In every packet that is sent by the client or server, it specifies a Window Size that is set by the packet sender to indicate how many bytes the sender is willing to accept in return.
When the TCP window size reaches zero (due to overload or hacking), the recipient of the packet will periodically poll the sender of the packet to see if it has become available again (i.e. if the Window Size has since grown) and if it has, the sender will finally send the requested data.
It’s absolutely normal for computers to become busy at times and use this mechanism to throttle their communications.
However, in our case, since the Protokube Gossip DNS uses a mesh topology, things can look very different and that’s exactly what happened in our case:
In our mesh topology, if computer B becomes temporarily busy for any reason, it will immediately overload all connections in its DNS Gossip network because all nodes that try to publish their DNS cache to computer B will become overloaded by other nodes trying to poll it at the same time. This resulted in a cascade of overloads that was made worse as more nodes got added to the network. More nodes meant exponentially more connections.
Due to the constant polling as a consequence of even a small initial overload, a small issue eventually spiraled to a point where the window size reached 0 and the network would come to a halt.
The solution I discovered was to run a script that loops through all nodes in a cluster, connects to them and kills the Protokube Daemon to force Kubernetes to restart every Protokub pod. The script ran pretty fast allowing for more nodes to become available and respond to the Gossip requests. After all nodes on the cluster went through this process, the cluster was back online and the extremely heavy load diminished.
We also reduced the number of servers by using more powerful ones. This reduced the overall node count and possible connections on the Gossip mesh thereby lowering the risk of overloading it.
Fewer nodes means less gossip which means less chance of failure.
Although this indeed solved the problem, the real long-term solution for production environments is to abandon Gossip DNS completely and switch to better techniques such as the AWS Route53 service.
Just as a side note, the very same throttling mechanism can and is being used by hackers to attack servers and services by causing a DoS attack. The idea is by sending multiple request packets to a server and setting the TCP window size to zero or to a low value, it forces the server to hold the connection open for long periods of time. Such attacks are known as Socketstress. A similar attack that operates in higher layers of the communication is the Slowloris attack. This works by requesting a resource but doesn’t allow the server to return it properly – causing a large number of connections to be left open and idle.
To summarize, we initially thought we needed to increase nodes to handle our growing needs, but this caused the network to come to a halt. After investigating, we found the culprit to be the way Gossip DNS is implemented in Protokube. Counter-intuitively, by reducing the number of nodes and forcing K8s to restart all Protokube pods in a cluster, we were able to scale without sacrificing performance (or any children). However, even this was a short-term solution and we eventually abandoned Gossip DNS for a dedicated DNS server.
With the shift from traditional monolithic applications to the distributed microservices of DevOps, there is a need for a similar change in operational security policies. For…

Like all programming, scripting is a way of providing instructions to a computer so you can tell it what to do and when to do it….

With progressive delivery, DevOps, scrum, and agile methodologies, the software delivery process has become faster and more collaborative than ever before. Scrum has emerged as a…