The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

“What is GitOps?” – a question which has seen increasing popularity on Google searches and blog posts in the last three years. If you want to know why then read on.
Quite simply, the coining of GitOps is credited to one individual, and pretty smart guy, Alexis Richardson. He’s so smart that he’s built a multi-award-winning consultancy, Weaveworks, and a bespoke product, Flux, around the GitOps concept.
Through the course of this post, we’re going to explore what GitOps is, its relevance today, why you should be aware of it (and maybe even implement it), and what GitOps and Observability mean together.
What is GitOps?
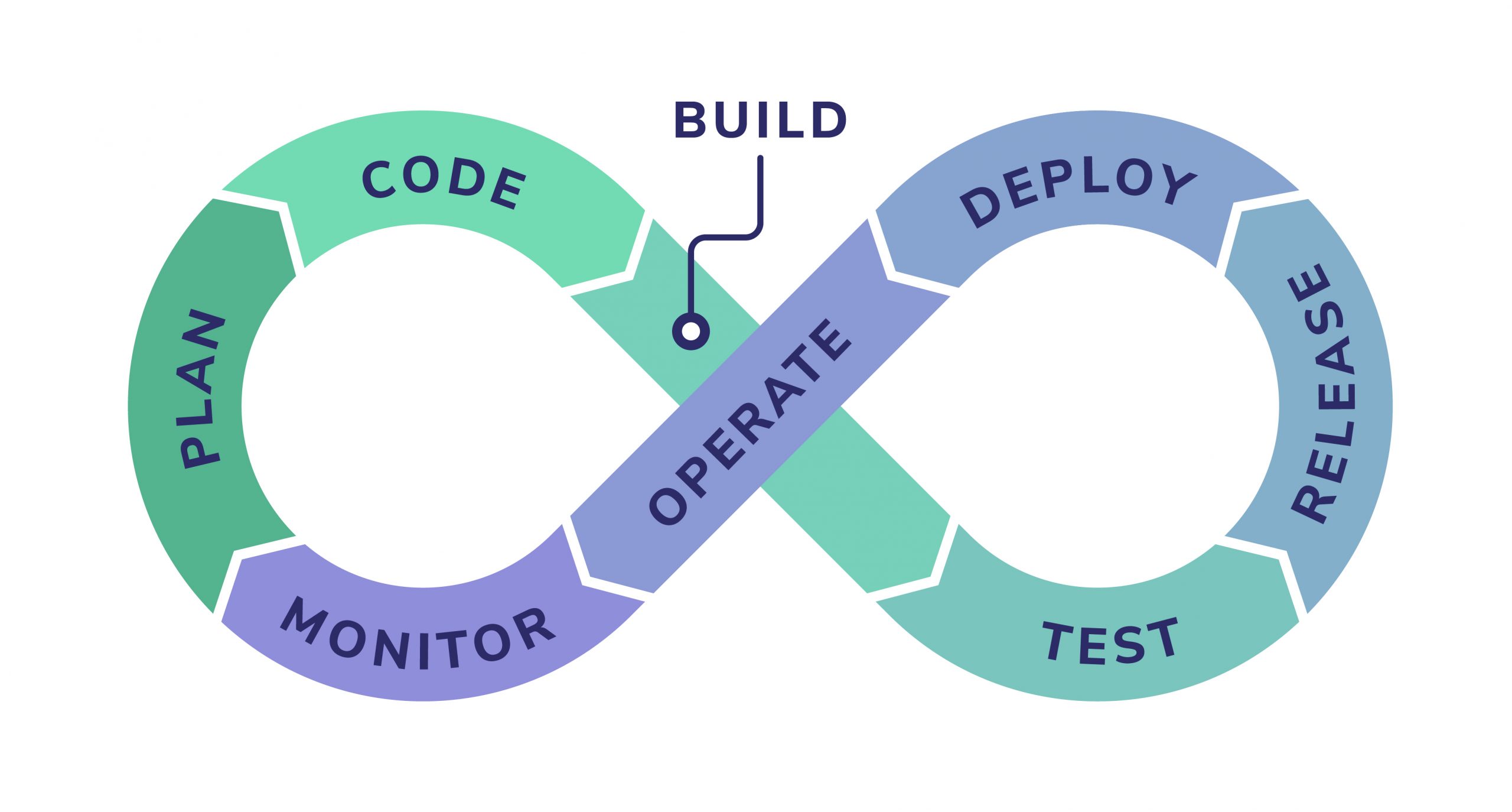
The concept is quite simple. A source control repository holds everything required for a deployment including code, descriptions, instructions, and more. Every time you change what’s in the repository, an engineer can pull the change to alter or update the deployment. This principle can also be applied for new deployments.
Of course, it’s a little more complex than that. GitOps relies on a single source of truth, automation, and software agents, to identify deltas between what is deployed and what is in source control. Then, through more automation, reconcilers, and a tool like Helm, clusters are updated or changes are rolled back, depending on a host of factors.
What’s crucial to understand is that GitOps and containerization, specifically with Kubernetes for orchestration and management, are symbiotic. GitOps has huge relevance for other cloud-native technologies but is revolutionary for Kubernetes.
The popularity of GitOps is closely linked to some of the key emerging trends in technology today: rapid deployment, containerization with Kubernetes, and DevOps.
Is GitOps Better Than DevOps?
GitOps and DevOps aren’t necessarily mutually exclusive. GitOps is a mechanism for developers to be far more immersed in the operations workflow, therefore making DevOps work more effectively.
On top of that, because it relies on a central repository from which everything can be monitored and logged, it brings security and compliance to the heart of development and operations. Therefore, GitOps is also an enabler of good DevSecOps practices.
The Four Principles of GitOps
Like any methodology, GitOps has some basic principles which define best practice. These four principles, defined by Alexis Richardson, capture the essence of ‘GitOps best practices’:
1. The Entire System Can Be Described Declaratively
This is a simple principle. It means that your whole system can be described or treated through declarative commands. Therefore, applications, infrastructure, and containers are not only defined in code, but are also declared with code as well. All of this is version controlled within your central repository.
2. The Canonical Desired System State Versioned in Git
Building on the first principle, as your system is wholly defined within a single source of truth, like Git, you have one place where all changes and declarations are stored. ‘Git Revert’ makes rollbacks, upgrades, and new deployments seamless. You can make your entire workflow more secure by using an SSH key to certify changes that enforce your organization’s security requirements.
3. Approved Changes Can Be Automatically Applied
CI/CD with Kubernetes can be difficult. This is largely attributed to the complexity of Kubectl, and the need to have your cluster credentials allocated to each system alteration. With the principles of GitOps above, the definition of your system is kept in a closed environment. That closed environment can be permissioned so pulled changes are automatically applied to the system.
4. Software Agents for Correctness and Convergence
Once the three above principles are applied, this final principle ensures that you’re aware of the delta (or divergence) between what is in your source control repository and what is deployed. When a change is declared, as described in the first principle, these software agents will automatically pick up on any changes in your repository and reconcile your cluster to match.
When used with your repository, software agents can perform a vast array of functions. They ensure that there are automated fixes in place for outages, act as a QA process for your operations workflow, protect against human error or manual intervention, and can even take self-healing to another level.
GitOps and Scalability
So far, we have examined the foundational aspects of GitOps. These in themselves go some of the way in showing the inherent benefits GitOps has to offer. It brings additional advantages to organizations seeking simple scalability, in more than one way.
Traditionally, monolithic applications with multiple staging environments can take a while to spin up. If this causes delays, scaling horizontally and providing elasticity for critical services becomes very difficult. Deployment pipelines can also be single-use, wasting DevOps engineers’ time.
Migrating to a Kubernetes-based architecture is a great step in the right direction, but this poses two problems. First, you have to build all-new deployment pipelines, which is time consuming. Second, you have to get the bulk of your DevOps engineers up to speed on Kubernetes administration.
Scaling Deployment
In a traditional environment, adding a new application means a new deployment pipeline, creating new repositories, and being responsible for brand new workflows.
What GitOps brings to the table is simplicity in scalability. All you need to do is write some declarative code in your central repository, and let your software agents take care of the rest.
GitOps gives engineers, and developers in particular, the ability to self-serve when it comes to CI/CD. This means that engineers can employ both automation and scalability in their continuous delivery in much less time and without waiting for operational resources (human or technical).
Scaling Your Team
Because the principles of GitOps rely on a central repository and a pull-to-deploy mentality, it empowers your developers to act as DevOps engineers.
Whereas you may have previously needed a whole host of Kubernetes administrators, that isn’t the case with GitOps. Version controlled configs for Kubernetes mean it’s possible for a skilled developer to roll out changes instantaneously.
They can even roll them back again with a simple Git command. Thus, GitOps helps to create true “t-shaped” engineers, which is particularly valuable as your team or organization grows.
GitOps and Observability
If you’ve read and understood the principles of GitOps above, then it should come as no surprise that observability is a huge consideration when it comes to adopting GitOps. But how does having a truly observable system relate to your GitOps adoption?
GitOps requires you to detail the state of the system that you want, and therefore your system has to be designed in a way that allows it to be truly understood. For example, when changes to a Kubernetes cluster are committed to your central repository, it’s imperative that that cluster remains understood at all times. This ensures that the divergence between the observed and desired cluster state can be measured and acted upon.
This really requires a purpose-built, cloud-native, and fully-wrapped SaaS observability platform. Coralogix’s Kubernetes Operator provides a simple interface between the end-user and a cluster, automatically acknowledging and monitoring the creation and cessation of resources via your code repository. With its ability to map, manage, and monitor a wide variety of individual services, Coralogix is the natural observability partner for an organization anywhere on its GitOps journey.
Summary
Hopefully, you can now answer the question posited at the start of this article. GitOps requires your system to be code-defined, stored in a central repository, and to be cloud-native to allow its pull-to-deploy functionality.
In return, you get a highly scalable, highly elastic, system that empowers your engineers to spend more time developing releases and less time deploying them. With built-in considerations for security and compliance, there’s no doubt that it’s worth adopting.
However, be mindful that with such free-flowing spinning up and down of resources, an observability tool like Coralogix is a must-have companion to your GitOps endeavor.