The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

Logging solutions are a must-have for any company with software systems. They are necessary to monitor your software solution’s health, prevent issues before they happen, and troubleshoot existing problems.
The market has many solutions which all focus on different aspects of the log monitoring problem. These solutions include both open source and proprietary software and tools built into cloud provider platforms, and give a variety of different features to meet your specific needs. Grafana Loki is a relatively new industry solution so let’s take a closer look at what it is, where it came from, and if it might meet your logging needs.
What is Grafana Loki, and Where Did it Come From?
Grafana Loki based its architecture on Prometheus’s use of labels to index data. Doing this allows Loki to store indexes in less space. Further, Loki’s design directly plugs into Prometheus, meaning developers can use the same label criteria with both tools.
Prometheus is open source and has become the defacto standard for time-series metrics monitoring solutions. Being a cloud-native solution, developers primarily use Prometheus when software is built with Kubernetes or other cloud-native solutions.
Prometheus is unique in its capabilities of collecting multi-dimensional data from multiple sources, making it an attractive solution for companies running microservices on the cloud. It has an alerting system for metrics, but developers often augment it with other logging solutions. Other logging solutions tend to give more observability into software systems and add a visualization component to the logs.
Prometheus created a new query language (PromQL), making it challenging to visualize logging for troubleshooting and monitoring. Many of the available logging solutions were built before Prometheus came to the logging scene in 2012 and did not support linking to Prometheus.
What Need does Grafana Loki Fill?
Grafana Loki was born out of a desire to have an open source tool that could quickly select and search time-series logs where the logs are stored stably. Discerning system issues may include log visualization tools with a querying ability, log aggregation, and distributed log tracing.
Existing open source tools do not easily plug into Prometheus for troubleshooting. They did not allow developers to search for Prometheus’s metadata for a specific period, instead only allowing them to search the most recent logs this way. Further, log storage was not efficient, so developers could quickly max out their logging limits and need to consider which logs they could potentially live without. With some tools, crashes could mean that logs are lost forever.
It’s important to note that there are proprietary tools on the market that do not have these same limitations and have capabilities far beyond what open source tools are capable of providing. These tools can allow for time-bound searching, log aggregation, and distributed tracing with a single tool instead of using a separate open source tool for each need. Coralogix, for example, allows querying of logs using SQL queries or Kibana visualizations and also ingests Prometheus metrics along with metrics from several other sources.
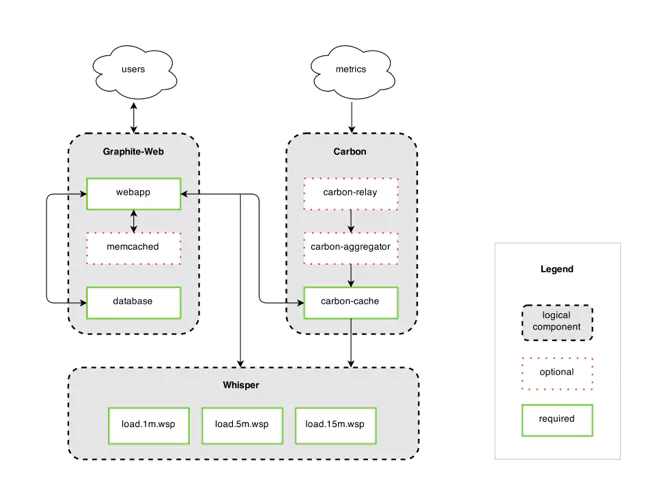
Grafana Loki’s Architecture
Built from Components
Developers built Loki’s service from a set of components (or modules). There are four components available for use: distributor, ingester, querier, and query frontend.
Distributor
The distributor module handles and validates incoming data streams from clients. Valid data is chunked and sent to multiple ingesters for parallel processing.
The distributor relies on Prometheus-like labels to validate log data in the distributor and to process in different downstream modules. Without labels, Grafana Loki cannot create the index it requires for searching. Suppose your logs do not have appropriate labels, for example. In that case, if you are loading from services other than Prometheus, the Loki architecture may not be the optimal choice for log aggregations.
Ingester
The ingester module writes data to long-term storage. Loki does not store the log data it ingests, instead only indexing metadata. The object storage used is configurable, for example, AWS S3, Apache Cassandra, or local file systems.
The ingester also returns data for in-memory queries. Ingester crashes cause unflushed data to be lost. Loki can irretrievably lose logs from ingesters with improper user setup ensuring redundancy.
Querier
Grafana Loki uses the querier module to handle the user’s queries on the ingester and the object stores. Queries are run first against local storage and then against long-term storage. The querier must handle duplicate data because it queries multiple places, and the ingesters do not detect duplicate logs in the writing process. The querier has an internal mechanism, so it returns data with the same timestamp, label data, and log data only once.
Query Frontend
The query frontend module optionally gives API endpoints for queries that enable parallelization of large queries. The query frontend still uses queries, but it will split a large query into smaller ones and execute the reads on logs in parallel. This ability is helpful if you are testing out Grafana Loki and do not yet want to set up a querier in detail.
Object Stores
Loki needs long-term data storage for holding queryable logs. Grafana Loki requires an object store to hold both compressed chunks written by the ingester and the key-value pairs for the chunk data. Fetching data from long-term storage can take more time than local searches.
The file system is the only no-added-cost option available for storing your chunked logs, with all others belonging to managed object stores. The file system comes with downsides since it is not scalable, not durable, and not highly available. It’s recommended to use the file system storage for testing or development only, not for troubleshooting in production environments.
There are many other log storage options available that are scalable, durable, and highly available. These storage solutions accrue costs for reading and writing data and data storage. Coralogix, a proprietary observability platform, analyzes data immediately after ingestion (before indexing and storage) and then charges based on how the data will be used. This kind of pricing model reduces hidden or unforeseen costs that are often associated with Cloud storage models.
Grafana Loki’s Feature Set
Horizontally Scalable
Developers can run Loki in one of two modes depending on the target value. When developers set the target to all, Loki runs components on a single server in monolith mode. Setting the target to one of the available component names runs Loki in a horizontally-scalable or microservices mode where a server is available for each component.
Users can scale distributors, ingestors, and querier components as needed to handle the size of their stored logs and the speed of responses.
Inexpensive Log Storage and Querying
Being open source, Grafana Loki is an inexpensive option for log analytics. The cost involved with using the free-tier cloud solution, or the source code installed through Tanka or Docker, is in storing the log and label data.
Loki recommends labels be kept as small as possible to keep querying fast. As a result, label stores can be relatively small compared to the complete log data. Complete logs are compressed with your choice of the tool before being stored, making the storage even more efficient.
Note: Compression tools generally have a tradeoff between storage size and read speed, meaning developers will need to consider cost versus speed when setting up their Loki system.
Grafana uses Cloud storage solutions like AWS S3 or Google’s GCS. Loki’s cost depends on the size of logs needed for analysis and the frequency of read/write operations. For example, AWS S3 charges for each GB stored and for each request made against the S3 bucket.
Fast Querying
When logs are imported into Grafana Loki using Promtail, ingesters split out labels from the log data. Labels should be as limited as possible since they are used to select logs searched during queries. An implicit requirement of getting speedy queries with Loki is concise and limited labels.
When you query, Loki splits data according to time and then sharded by the index. Available queriers are then applied to read the shard’s entire contents looking for the given search parameters. The more queriers available and the smaller the index, the faster the query response will be available.
Grafana Loki uses brute force along with parallelized components to gain speed of querying. This speed gained with Grafana Loki is considerable for a brute force methodology. Loki uses this brute-force method to gain simplicity over fully indexed solutions. However, fully indexed solutions can search logs more robustly.
Open Source
Open source solutions like Grafana Loki always have drawbacks. The Loki team has had a great interest in their product and works diligently to address the new platform’s issues. Grafana Loki relies on community assistance with documentation and features. Community reliance means setting up and enhancing a log analytics platform with Loki can take significant and unexpected developer resources.
To ensure speedy responses, users must sign up for Enterprise services which come at a cost like other proprietary systems. If you are considering these Enterprise services, ensure you have looked at other proprietary solutions, so you get the most valuable features from your log analytics platform.
Summary
Grafana Loki is an open source, horizontally scalable, brute-force log aggregation tool built for use with Prometheus. Production users will need to combine Loki with a cloud account for log storage.
Loki gives users a low barrier-to-entry tool that plugs into both Prometheus for metrics and Grafana for log visualization in a simple way. The free version does have drawbacks since it is not guaranteed to be available. There are also instances where Loki can lose logs without proper redundancy implemented.
Proprietary tools are also available with Grafana Loki’s features and with added log aggregation and analytics features. One such tool is the Coralogix observability platform which offers real-time analytics, anomaly detection, and a developer-friendly live tail with CLI.