When you’re working with large data sets, having that data structured in a way that means you can use software to process and understand it will enable you to derive insights far more quickly than any manual approach. Logfile data is no exception.
As increasing numbers of organizations embrace the idea that log files can offer far more than an aid to troubleshooting or a regulatory requirement, the importance of log file monitoring and structuring the data in those log files so that it can be extracted, manipulated, and analyzed efficiently is quickly moving up the priority list. In this article, we’re going to explore one of the most popular formats for structuring log files: JSON.
What is JSON?
JSON, or JavaScript Object Notation to give it its full form, is a machine-readable syntax for encoding and exchanging data. Despite the name, you’ll find JSON in use far outside its original realm of web servers and browsers. With all major computing languages supporting it, JSON is one of the most widely used formats for exchanging data in machine-to-machine communications.
One of the advantages of JSON over other data exchange formats, such as XML, is that it’s easy for us humans to both read and write. Unlike XML, JSON doesn’t rely on a complex schema and completely avoids the forest of angle brackets that results from requiring everything to be enclosed within tags. This makes it much easier for first-time users to get started with JSON.
A JSON document is made up of a simple syntax of key-value pairs ordered and nested within arrays. For example, a key called “status” might have values “success,” “warning,” and “error.” Keys are defined within the document and are always quoted, meaning there are no reserved words to avoid, and arrays can be nested to create hierarchies.
That means you can create whatever keys make sense for your context, and structure them however you need. The keys and how they are nested (the JSON specification) need to be agreed upon between the sender and the recipient, which can then read the file and extract the data as required.
The simplicity and flexibility of JSON make it an ideal candidate for generating structured log statements; log data can be extracted and analyzed programmatically, while the messages remain easy for individuals to understand. JSON logging is supported by all major programming languages, either natively or via libraries.
Benefits of JSON logging
Given that log messages are always generated by software, you might expect that they are always structured and be wondering what JSON can add. While it’s true that log messages will always follow a particular syntax (in accordance with how the software has been programmed to output logs), that syntax could be one long string of characters, multiple lines of obscure codes and statuses, or a series of values delimited by a character of the programmer’s choice.
In order to make sense of these logs, you first need to decipher their syntax and then write logic to parse the messages and extract the data you need. Unfortunately, that logic is often quite brittle, so if something changes in the log format – perhaps a new piece of data is included, or the order of items is changed – then the parser will break.
If you’re only dealing with logs from a single system that you have control over, that might be manageable. But the reality in many enterprises is that you’re working with multiple systems and services, some developed in-house and others that are open-source or commercial, and all of them are generating log messages.
Those log messages are a potential mine of information that can be used to gain insights into how your systems – and therefore your business – are performing. However, before you can derive those insights, you first need to make sense of the information that is being provided. Writing and maintaining custom logic to parse logs for dozens of pieces of software is no small task.
That’s where a structured format such as JSON can help. The key-value pairs make it easy to extract specific values and to filter and search across a data set. If new key-value pairs are added, the software parsing the log messages will just ignore those keys it doesn’t expect, rather than failing completely.
Writing logs in JSON format
So what does a log message written in JSON look like? The following is an example log line generated by an Nginx web server and formatted in JSON:
With the JSON format, it’s easy for someone unfamiliar with web server logs to understand what the message contains, as each field is labeled. With a common log format, you need to know what you’re looking at.
Of course, common log format is widely used by web servers, and most log analysis platforms can parse it natively, without further manual configuration. But what about log files generated by other software, such as a custom-built application or third-party software? Looking at this unstructured log file from an iOS application you’d be forgiven for wondering what it’s telling you:
08:51:08 [DataLogger:27]: G L 35.76 +/- 12m <+52.55497710,-0.38856690> +/- 15.27m 0.60
With this format, it’s easy to understand the values and see how the fields are related.
JSON logging best practices
Now that we’ve covered the what, why, and how of JSON logging, let’s discuss some tips to help you get the most out of your JSON logs. Most of these apply whether you’re writing software in-house or are using third-party or open-source tools that allow you to configure the format of the logs they output.
Invest time in designing your logs
Just as you wouldn’t jump in and start writing code for the next ticket on the backlog without first thinking through the problem you’re trying to solve and how it fits into the wider solution, it’s important to take the time to design your log format. There is no standard format for JSON logs – just the JSON syntax – so you can decide on a structure to serve your needs.
When defining keys, think about what level of granularity makes sense. For example, do you need a dedicated “error” key, or is it more useful to have a key labeled “message” that is used for any type of message, and another labeled “status” that will record whether the message was an error, warning, or just information? With the latter approach, you can filter log data by status to view only error messages while reducing the number of columns and filter options.
Add log lines as you code
If you’re developing software in-house, make adding log lines as much a part of your code hygiene as writing unit tests. It’s much easier to decide what information would be useful to output, and at what level (for example, is this a critical error or just useful to know when debugging) when you’re writing that particular piece of functionality, than after you’ve finished the development work.
Capture as much detail as possible
When you’re thinking about what data to capture, it’s easy to focus on the parameters you want to be able to filter, sort, and query by, while losing sight of what you might want to learn from your logs when drilling down into more detail.
Log files provide value on both a macro and micro level: by aggregating and analyzing log files, we can identify patterns of behavior and spot changes that might indicate a problem. Once we know where to look, we can zoom into the individual log files to find out more about what’s going on. This is where capturing as much detail as possible pays dividends.
For application logs, details such as the module name and line number will help you identify the cause of the problem quickly. In the case of server access logs, details such as the requester’s IP, their time zone, logged-in username, and authentication method can be invaluable when investigating a potential security breach.
Keep in mind that not all data needs to be broken down into separate fields; you can create a key to capture more verbose information that you wouldn’t want to filter by, but which is useful when reading individual log messages.
Consistency is king
Being consistent in the way you name keys and the way you record values will help you to analyze logs more efficiently. This applies both within a single piece of software and when designing logs across multiple systems and services.
For example, using the same set of log levels across applications means you can easily filter by a particular type while being consistent in writing status codes, as either strings or numbers will ensure you can manipulate the data effectively.
Unstructured logs – parsing to JSON
Although structuring logs with JSON offers many advantages, in some cases it’s not possible to output logs in this format. For some third-party software, you may not have the ability to configure the format or content of log messages.
If you’re dealing with a legacy system plagued with technical debt, the effort involved in updating the logging mechanism might not be justified – particularly if work on a replacement is underway.
When you’re stuck with an existing unstructured log format, the next best thing is to parse those logs into a JSON format after the fact. This involves identifying the individual values within each message (using a regular expression, for example) and mapping them to particular keys.
Many log analysis platforms allow you to configure rules for parsing unstructured logs to JSON so that they can be processed automatically. You can then analyze the data programmatically alongside your structured log data. Transforming logs to JSON also renders the individual log files more readable to humans, ready for when you want to drill down in more detail.
JSON log analytics with Coralogix
By structuring your logs in JSON format you can more effectively analyze log files from multiple sources and leverage machine learning techniques to identify trends and anomalies in your data. Because JSON is easy to read, you can still view and understand individual log entries when investigating and troubleshooting issues.
As a log analysis and observability platform, Coralogix automatically extracts fields from your JSON logs so that you can filter, sort, query, and visualize according to your JSON log file viewer. With custom views, you can configure reports based on the fields you’re interested in. For unstructured logs, you can set up log parsing rules to extract values and append the JSON to the log entry, or replace the entire entry with structured JSON, according to your needs. Using the Coralogix log analytics platform you can collate and aggregate logs from multiple sources and use sophisticated data analysis tools to improve your understanding of your systems and unlock valuable insights.
In a previous post, we explored the basic concepts behind using Grok patterns with Logstash to parse files. We saw how versatile this combo is and how it can be adapted to process almost anything we want to throw at it. But the first few times you use something, it can be hard to figure out how to configure for your specific use case. Looking at real-world examples can help here, so let’s learn how to use Grok patterns in Logstash to parse common logs we’d often encounter, such as those generated by Nginx, MySQL, Elasticsearch, and others.
First, Some Preparation
We’ll take a look at a lot of example logs and Logstash config files in this post so, if you want to follow along, instead of downloading each one at each step, let’s just copy all of them at once and place them in the “/etc/logstash/conf.d/logstash” directory.
First, install Git if it’s not already installed:
sudo apt update && sudo apt install git
Now let’s download the files and place them in the directory:
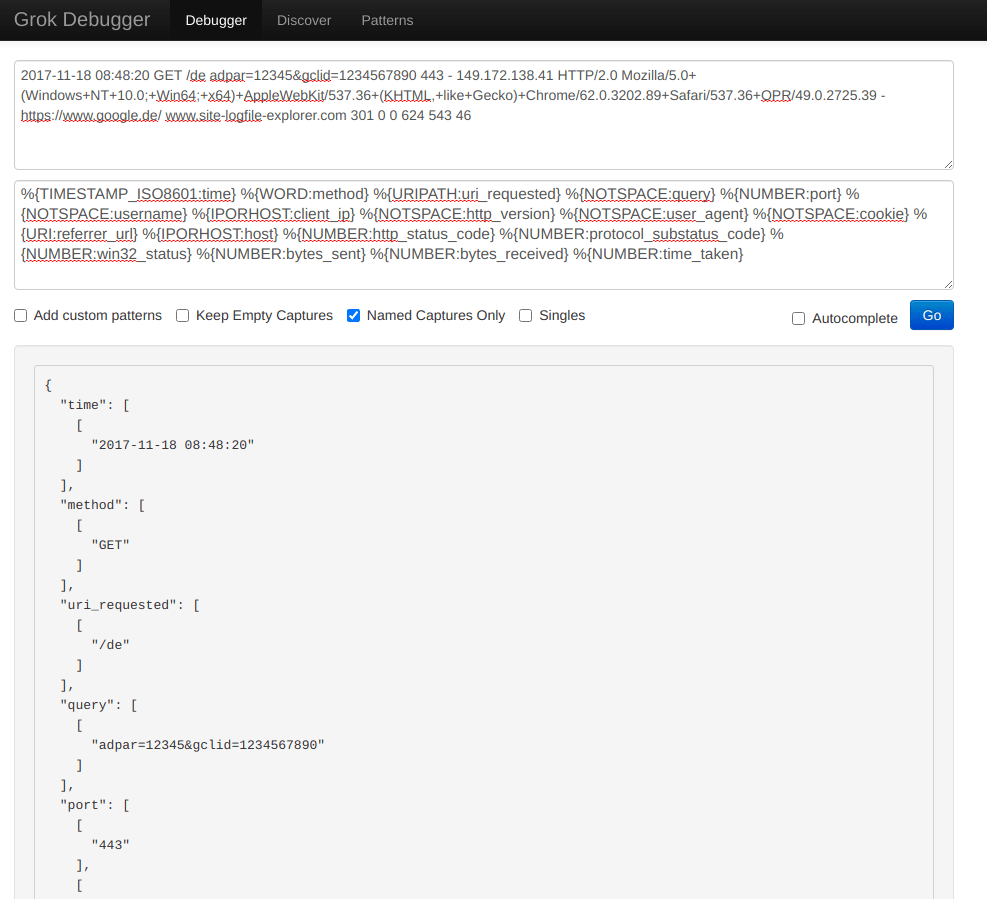
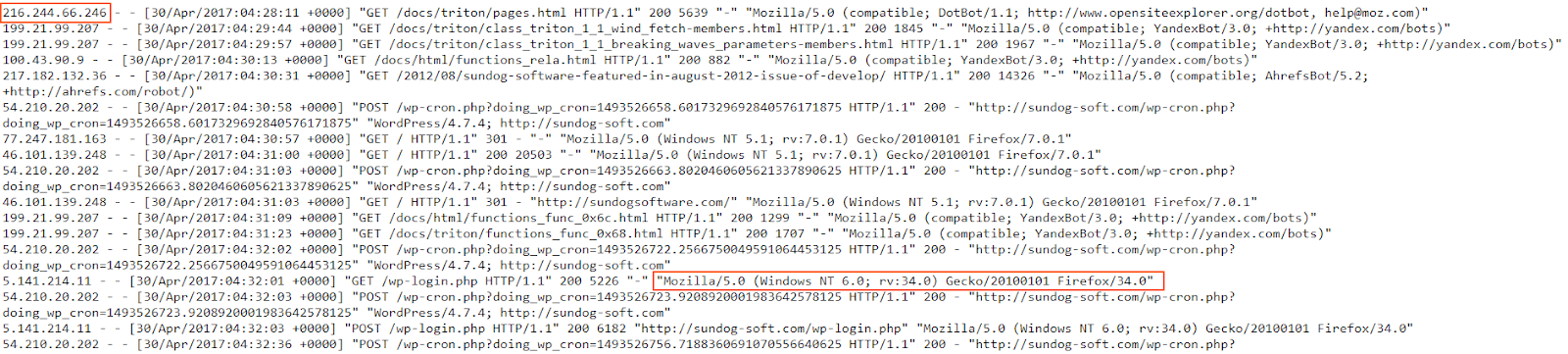
NGINX and Apache are the most popular web servers in the world. So, chances are, we will often have contact with the logs they generate. These logs reveal information about visits to your site like file access requests, NGINX responses to those requests, and information about the actual visitors, including their IP, browser, operating system, etc. This data is helpful for general business intelligence, but also for monitoring for security threats by malicious actors.
Let’s see how a typical Nginx log is structured.
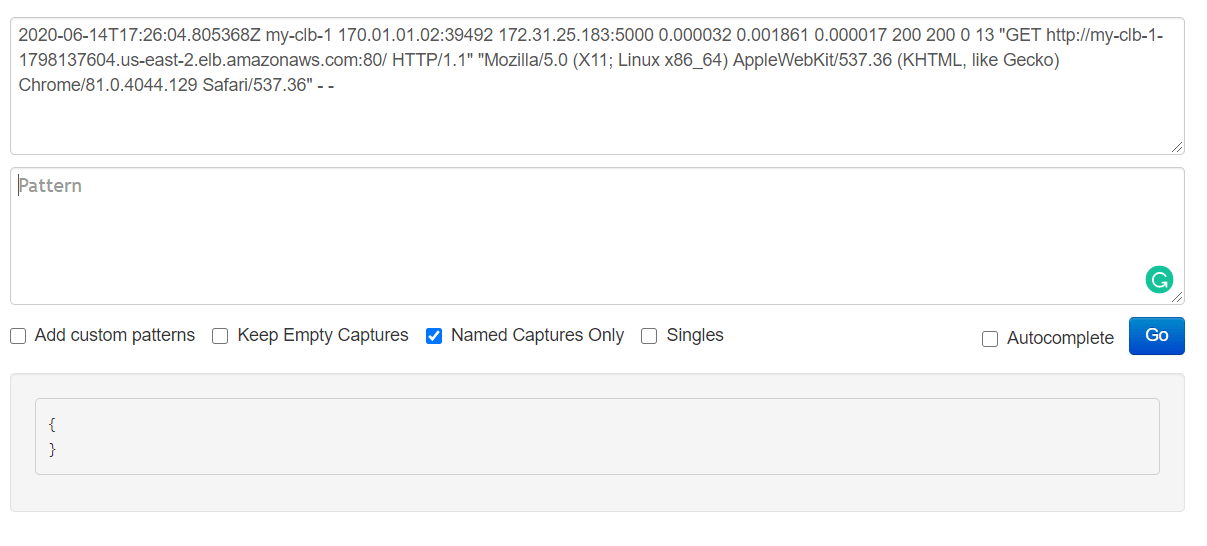
We’ll open the following link in a web browser https://raw.githubusercontent.com/coralogix-resources/logstash/master/nginx/access.log and then copy the first line. Depending on your monitor’s resolution, the first line might actually be broken into two lines, to fit on the screen (otherwise called “line wrapping”). To avoid any mistakes, here is the exact content of the line we will copy:
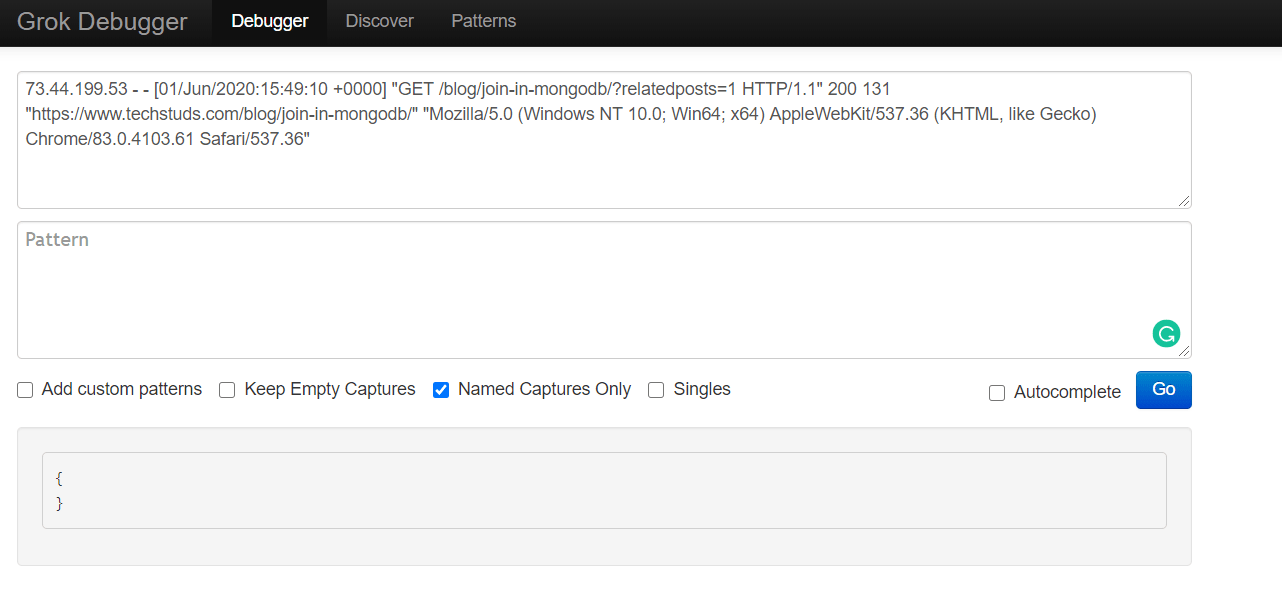
Next, let’s open the Grok Debugger Tool at https://grokdebug.herokuapp.com/ to help us out. In the first field, the input section, we’ll paste the previously copied line.
We go back to the https://grokdebug.herokuapp.com/ website and paste the Grok pattern in the second field, the pattern section. We’ll also tick the “Named captures only” checkbox and then click the “Go” button.
Note: For every line you copy and paste, make sure there are no empty lines before (or after) the actual text in the pattern field. Depending on how you copy and paste text, sometimes an empty line might get inserted before or after the copied string, which will make the Grok Debugger fail to parse your text. If this happens, just delete the empty line(s).
This tool is useful to test if our Grok patterns work as intended. It makes it convenient to try out new patterns, or modify existing ones and see in advance if they produce the desired results.
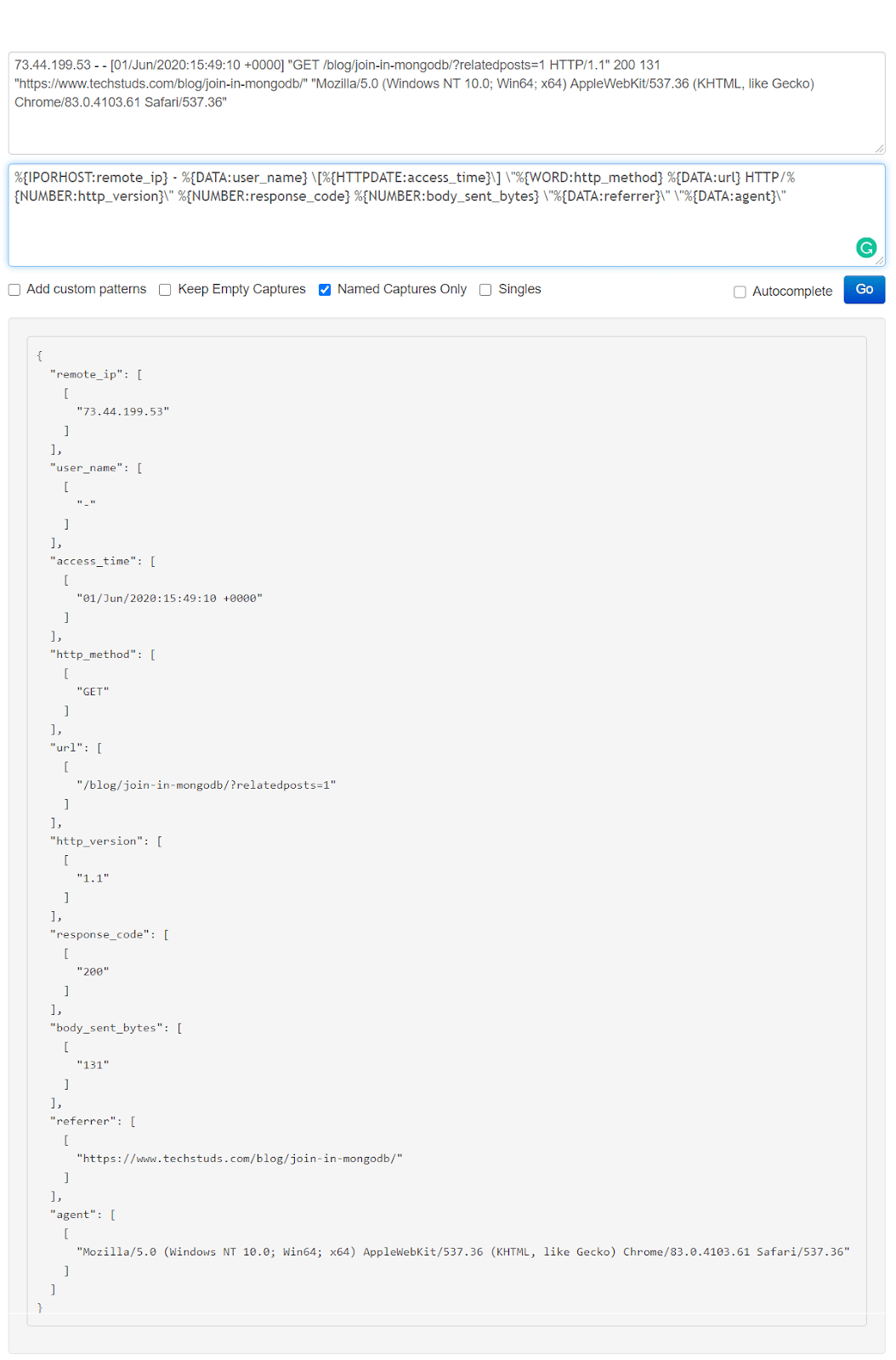
Now that we’ve seen that this correctly separates and extracts the data we need, let’s run Logstash with the configuration created specifically to work with the Nginx log file:
We can see the fields and their associated values neatly extracted by the Grok patterns.
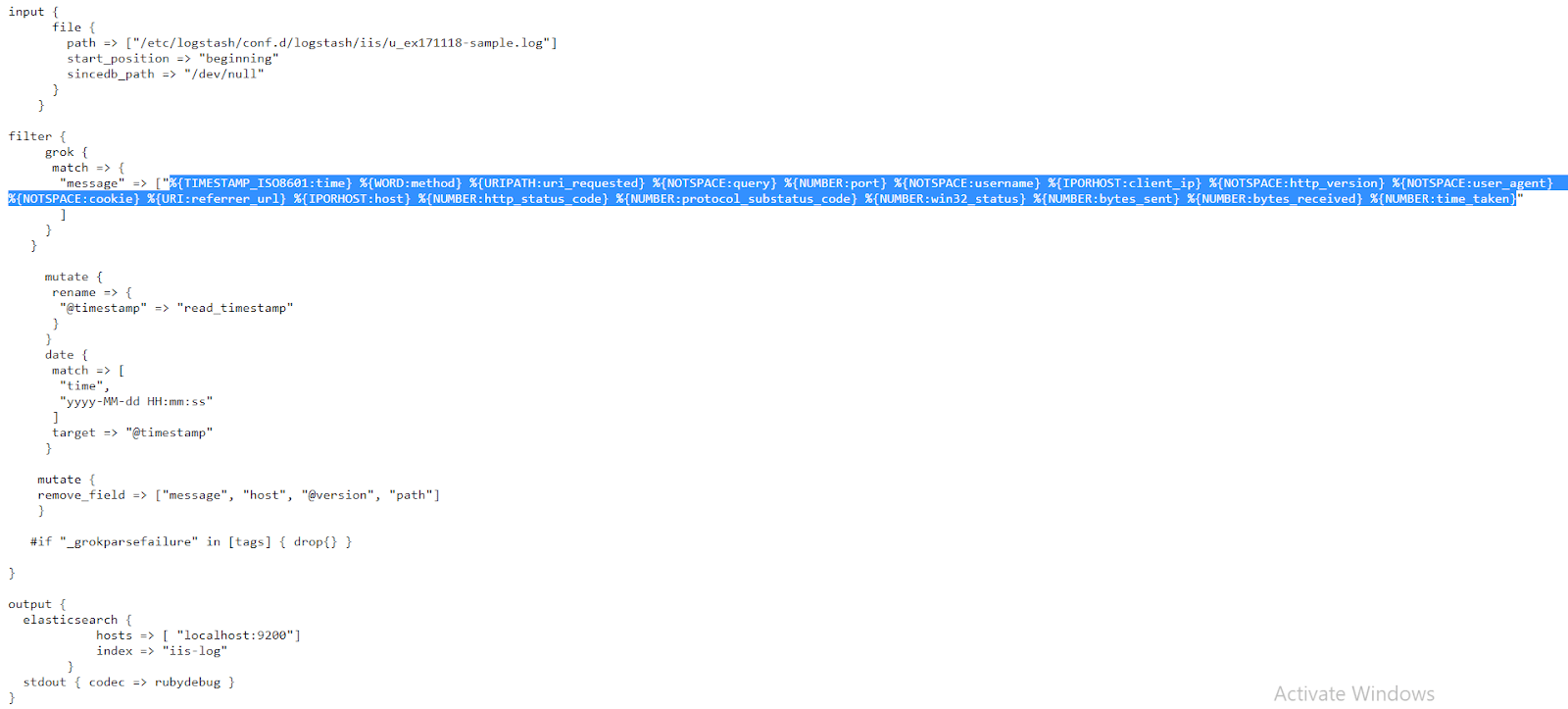
IIS Logs
While we’ll often see Apache and Nginx web servers on the Linux operating system, Microsoft Windows has its own web server included in IIS (Internet Information Services). These generate their own logs that can be helpful to monitor the state and activity of applications. Let’s learn how to parse logs generated by IIS.
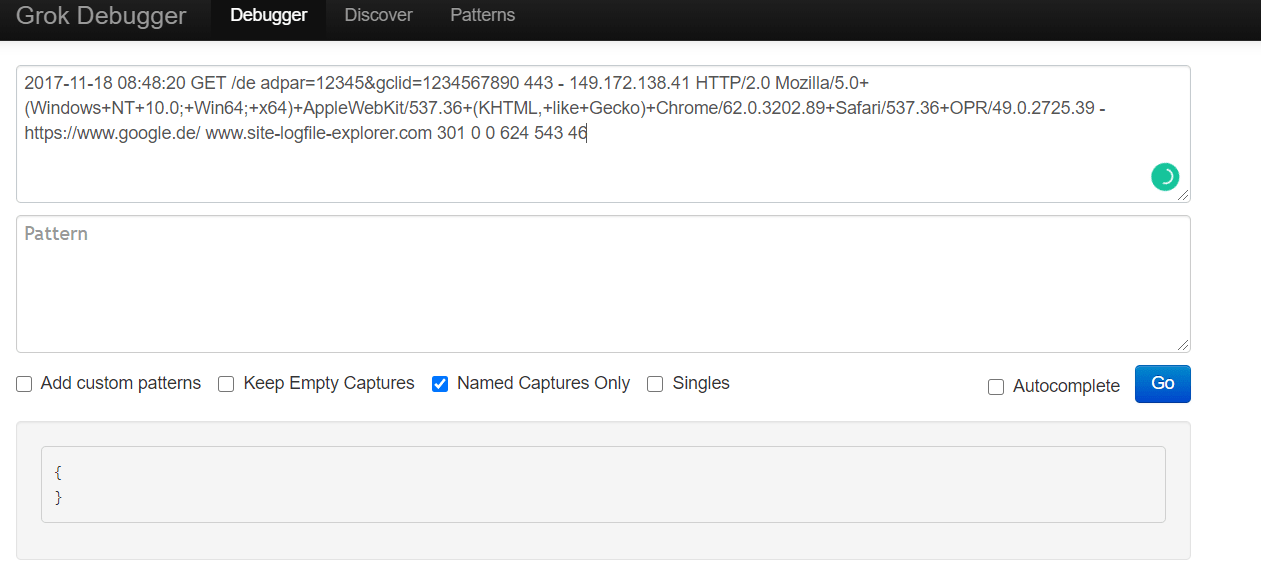
Once again, to take a closer look at how our specific Grok patterns will work, we’ll paste our log line into the Grok Debugger Tool tool, in the first field, the input section.
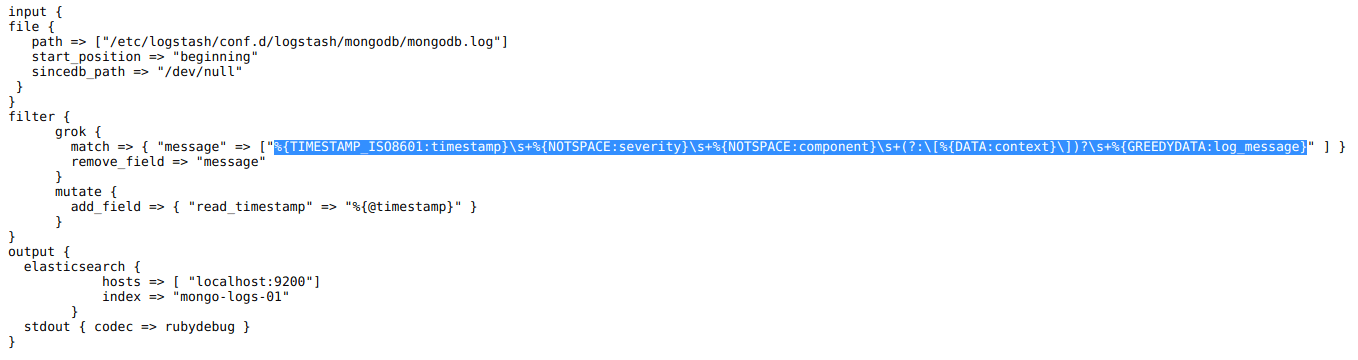
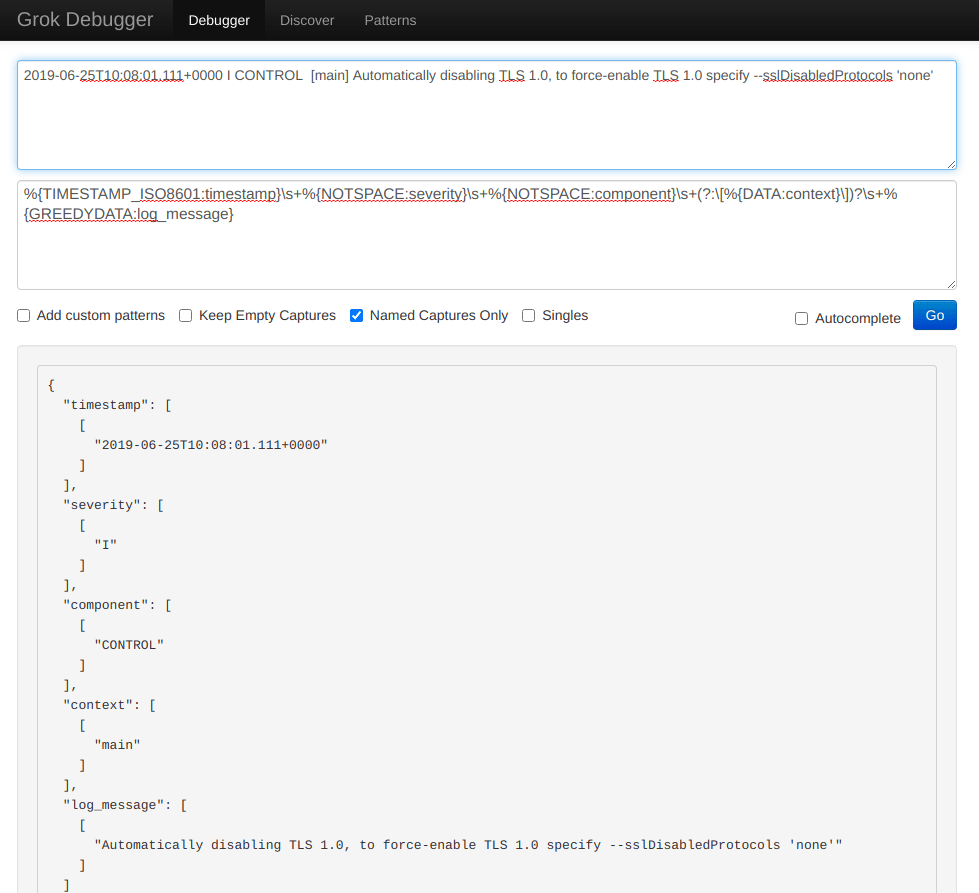
While not as popular as MySQL, the MongoDB database engine still has a fairly significant market share and is used by many leading companies. The MongoDB logs can help us track the database performance and resource utilization to help with troubleshooting and performance tuning.
User Agent Mapping and IP to Geo Location Mapping in Logs
Very often, when a web browser requests a web page from a web server, it also sends a so-called “user agent”. This can contain information such as the operating system used by a user, the device, the web browser name and version and so on. Obviously, this can be very useful data in certain scenarios. For example, it can help you find out if users of a particular operating system are experiencing issues.
Web servers also log the IP addresses of the visitors. While that’s useful to have in raw logs, those numbers themselves are not always useful to humans. They might be nice to have when trying to debug connectivity issues, or block a class of IPs, but for statistics and charts, it might be more relevant to have the geographic location of each IP, like country/city and so on.
to the actual names of the specific operating system, device and/or browser that was used, and other info which is much more easy to read and understand by humans. Likewise, IP addresses can be transformed to estimated geographical locations. The technical term for these transformations is mapping.
In the useragent filter section, we simply instruct Logstash to take the contents of the agent field, process them accordingly, and map them back to the agent field.
In the geoip filter, we instruct Logstash to take the information from the clientip field, process it, and then insert the output in a new field, called geoip.
Let’s run Logstash with this config and see what happens:
We’ll need to wait for a longer period of time for this to be done as there are many more lines the utility has to process (tens of thousands). As usual, when it’s done, we’ll press CTRL+C to exit.
Now let’s explore how this log was parsed and what was inserted to the index:
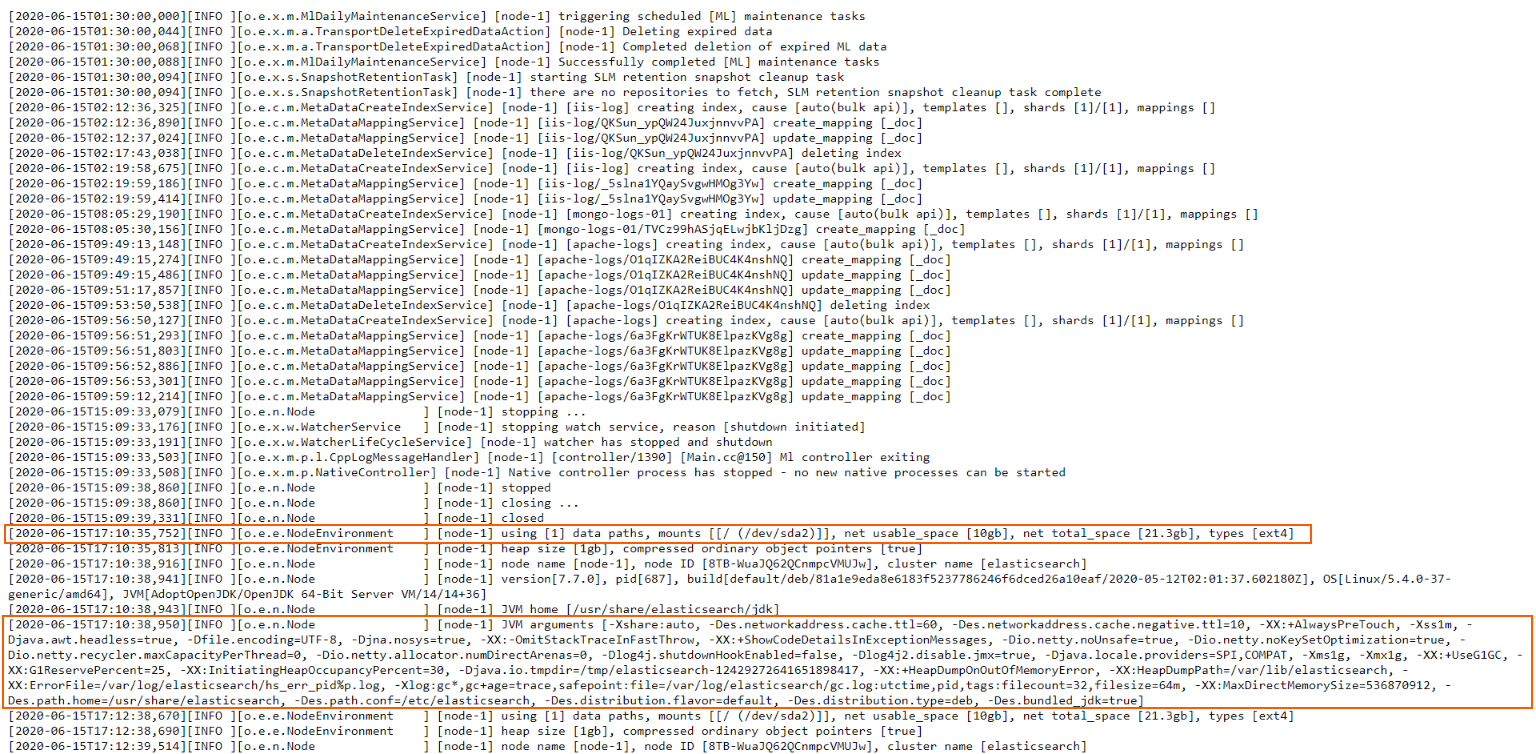
Now, this is slightly different from what we’ve worked with up until now. In all the other logs, each line represented one specific log entry (or message). That meant we could process them line by line and reasonably expect that each logged event is contained within a single line, in its entirety.
Here, however, we sometimes encounter multi-line log entries. This means that a logged event can span across multiple lines, not just one. Fortunately, though, Elasticsearch clearly signals where a logged event begins and where it ends. It does so by using opening [ and closing ] square brackets. If you see that a line opens a square bracket [ but doesn’t close it on the same line, you know that’s a multi-line log entry and it ends on the line that finally uses the closing square bracket ].
Logstash can easily process these logs by using the multiline input codec.
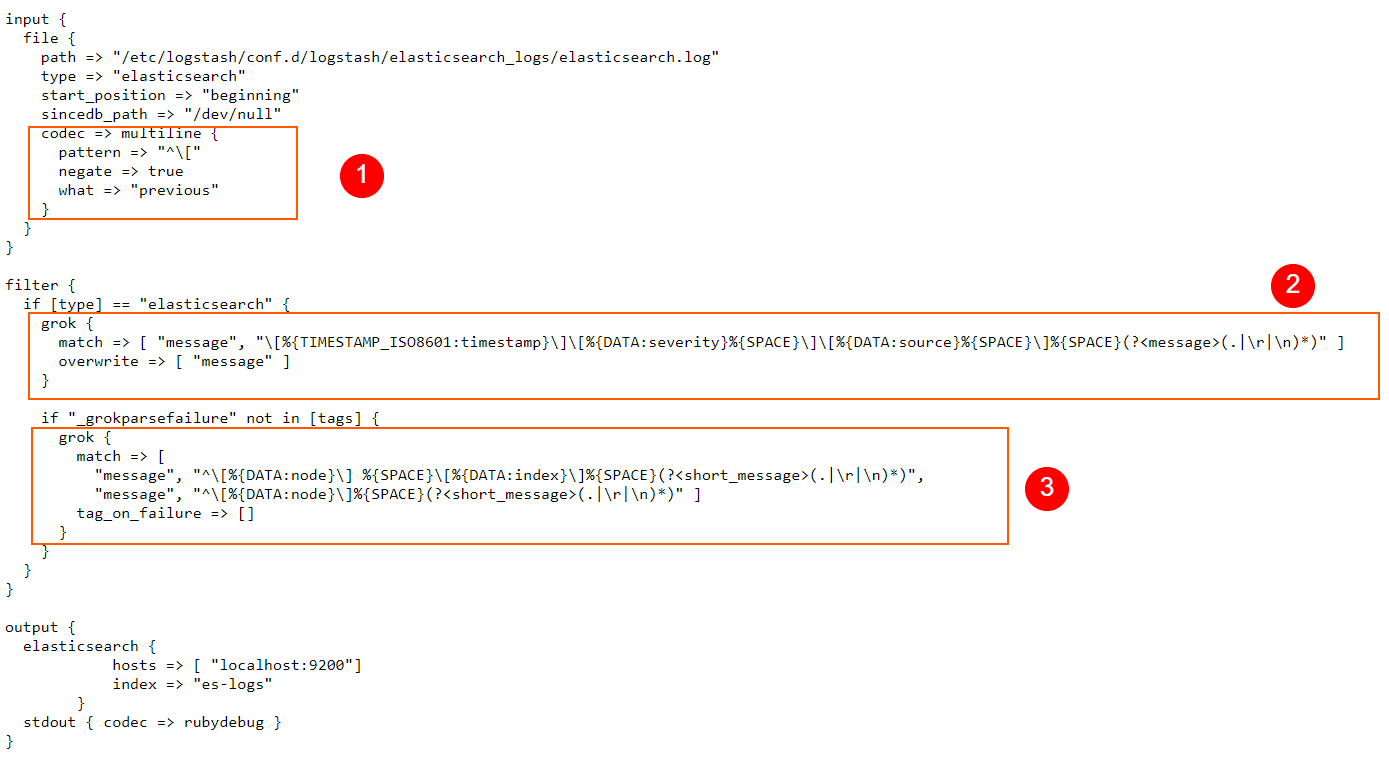
In the codec => multiline section of our config, we define the pattern that instructs Logstash on how to identify multiline log entries. Here, we use a RegEx pattern, but of course, we can also use Grok patterns when we need to.
With negate set to true, a message that matches the pattern is not considered a match for the multiline filter. By default, this is set to false and when it is false, a message that matches the pattern is considered a match for multiline.
“what” can be assigned a value of “previous” or “next“. For example, if we have a match, negate is set to false, and what has a value set to previous, this means that the current matched line belongs to the same event as the previous line.
In a nutshell, what we are doing for our scenario here is telling Logstash that if a line does not start with an opening square bracket [ then the line in the log file is a continuation of the previous line, so these will be grouped in a single event. Logstash will apply a “multiline” tag to such entries, which can be useful for debugging, or other similar purposes if we ever need to know which entry was contained in a single line, and which on multiple lines.
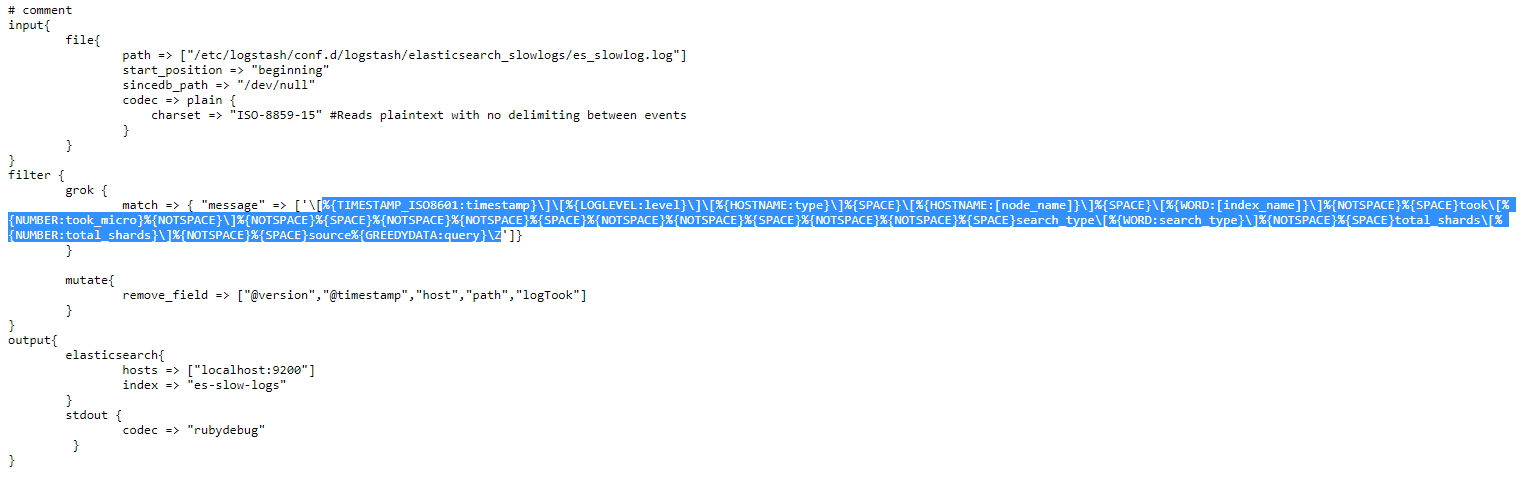
In the filter section we use a typical Grok pattern, just like we did many times before, and replace the message field with the parsed content.
Finally, a second Grok pattern will process the content in the message field even further, extracting things like the logged node name, index name, and so on.
After the program does its job, we press CTRL+C to exit.
Logstash has now parsed both single-line events and multiline events. We will now see how useful it can be that multiline events have been tagged appropriately. Because of this tag, we can now search entries that contain only single-line events. We do this by specifying in our cURL request that the matches must_not contain the tags called multiline.
Elasticsearch can also generate another type of logs, called slow logs and are used to optimize Elasticsearch search and indexing operations. These are easier to process since they don’t contain multiline messages.
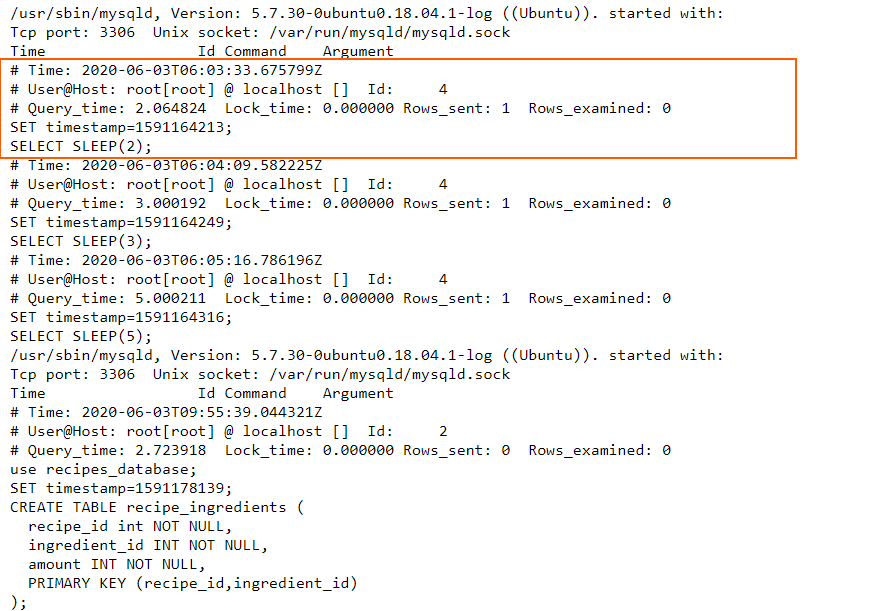
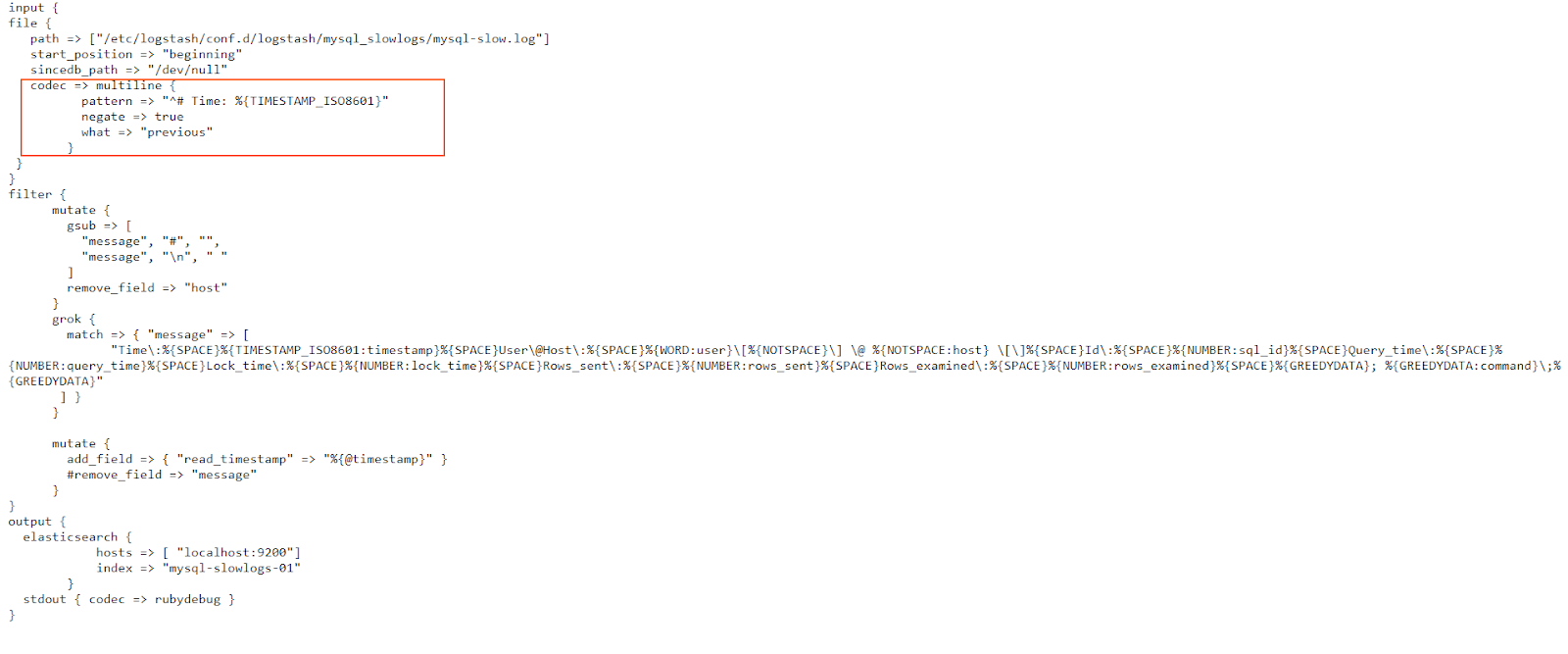
MySQL can also generate slow logs to help with optimization efforts. However, these will log events on multiple lines so we’ll need to use the multiline codec again.
In the multilinecodec configuration, we use a Grok pattern. Simply put, we instruct Logstash that if the line doesn’t begin with the “# Time:” string, followed by a timestamp in the TIMESTAMP_ISO8601 format, then this line should be grouped together with previous lines in this event. This makes sense, since all logged events in this slow log begin with that specific timestamp, and then describe what has happened at that time, in the next few lines. Consequently, whenever a new timestamp appears, it signals the end of the current logged event and the beginning of the next.
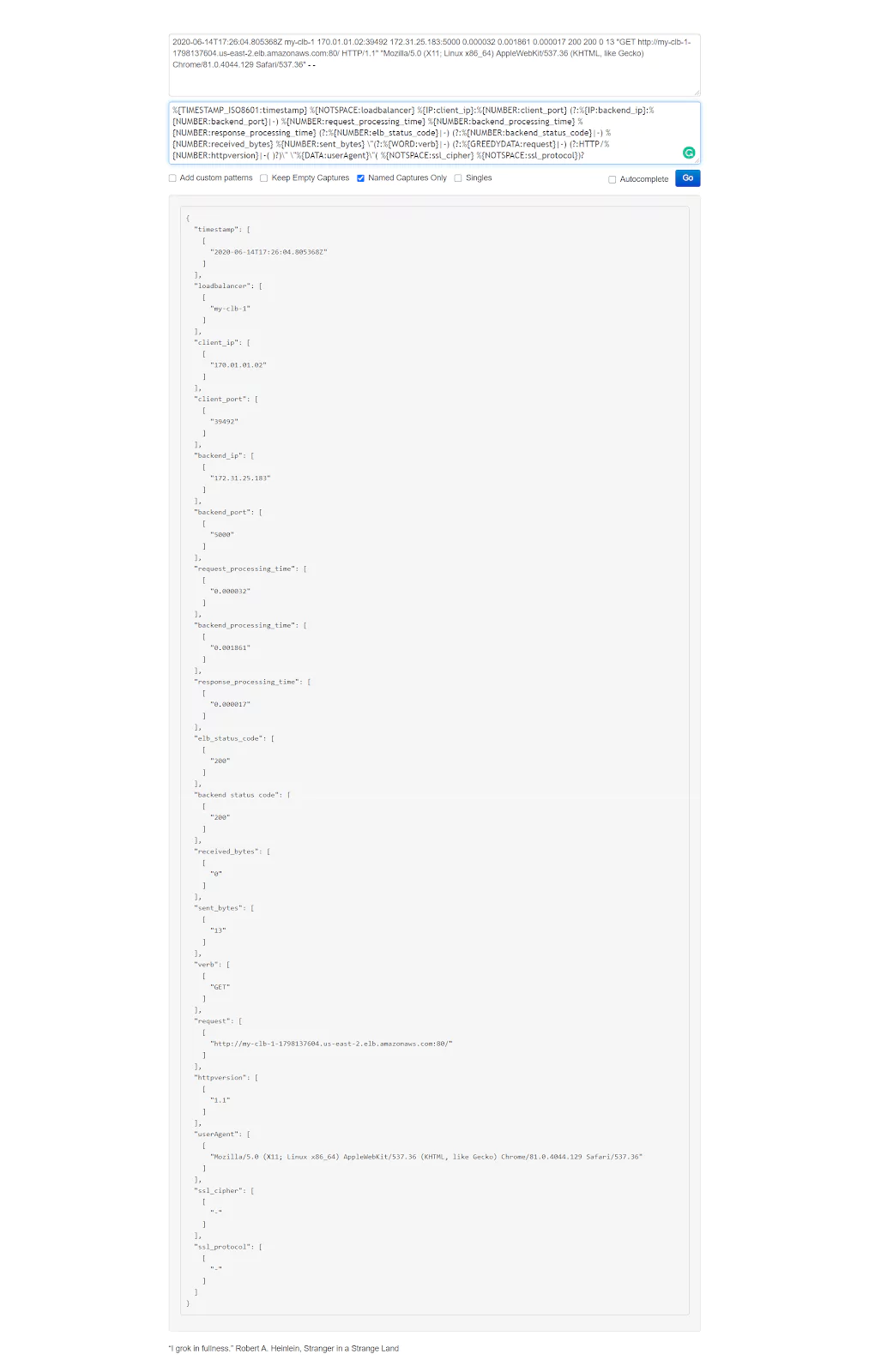
AWS Elastic Load Balancer is a popular service that intelligently distributes traffic across a number of instances. ELB provides access logs that capture detailed information about requests sent to your load balancer. Each ELB log contains information such as the time the request was received, the client’s IP address, latencies, request paths, and server responses.
If you want to test things out in the https://grokdebug.herokuapp.com/ website, the input line you can copy and paste into the first field is the following:
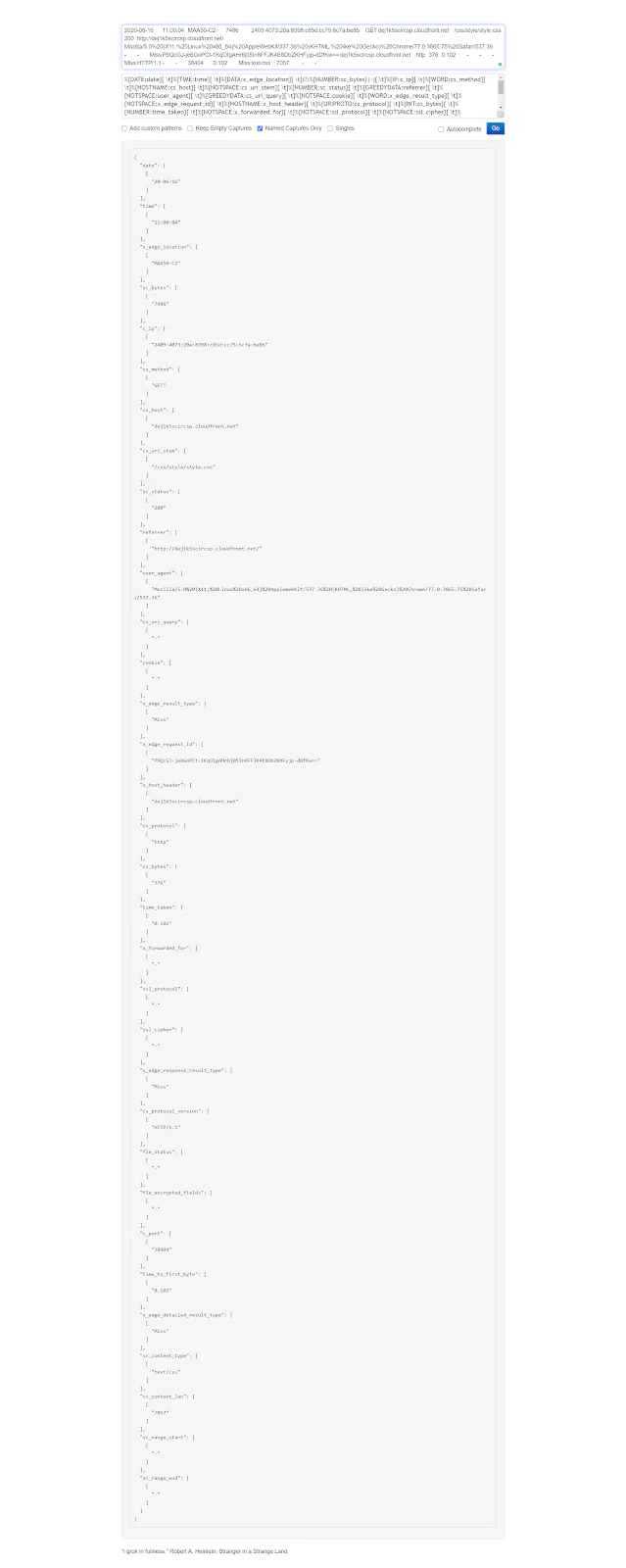
Once again, If you want to test how things work, in the https://grokdebug.herokuapp.com/ website, the input line you can copy and paste into the first field is this one:
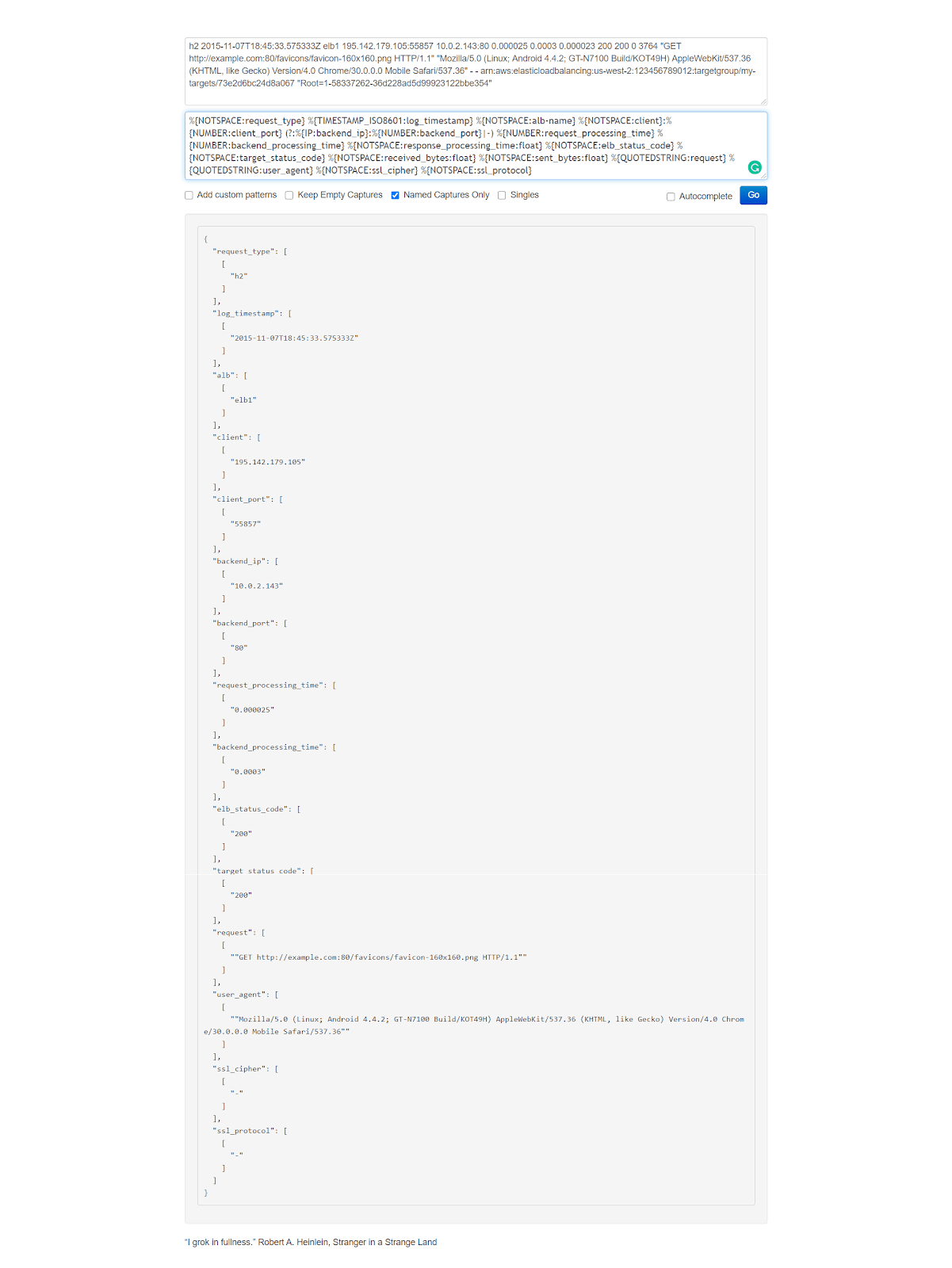
2020-06-16 11:00:04 MAA50-C2 7486 2409:4073:20a:8398:c85d:cc75:6c7a:be8b GET dej1k5scircsp.cloudfront.net /css/style/style.css 200 https://dej1k5scircsp.cloudfront.net/ Mozilla/5.0%20(X11;%20Linux%20x86_64)%20AppleWebKit/537.36%20(KHTML,%20like%20Gecko)%20Chrome/77.0.3865.75%20Safari/537.36 - - Miss P9QcGJ-je6GoPCt-1KqOIgAHr6j05In8FFJK4E8DbZKHFyjp-dDfKw== dej1k5scircsp.cloudfront.net http 376 0.102 - - - Miss HTTP/1.1 - - 38404 0.102 Miss text/css 7057 - -
I hope this arsenal of Grok patterns for common log types are useful for most of your future Logstash needs. Keep in mind that if the log you encounter is just slightly different, only slight changes need to be made to these patterns, which you can use as your starting templates.
Logstash can parse CSV and JSON files easily because data in those formats are perfectly organized and ready for Elasticsearch analysis. Sometimes, though, we need to work with unstructured data, like plain-text logs. In these cases, we’ll need to parse the data to turn it into structured data using Logstash Grok or another 3rd party service like Coralogix. This tutorial will help you use Elasticsearch’s analysis and querying capabilities by parsing with Logstash Grok.
So, let’s dive in and learn how to deal with unstructured data using the Logstash Grok filter.
Why Choose Grok?
Logstash Grok isn’t the only option available to parse unstructured logs. Plenty of other plugins, such as Dissect, third-party log management tools, or just plain RegEx, could do the trick. We can even build our own custom parsing logic if we have super-specific needs.
Grok is a popular choice for a multitude of reasons, starting with how easy it is to use. Grok patterns are relatively easy to understand, especially if we are already familiar with regular expressions, and come with a wide range of built-in patterns for common log formats such as timestamps, IP addresses, and URLs. We can also create custom patterns to cater to our exact requirements.
While there are standalone Grok parser libraries available for various programming languages, Logstash Grok is specifically designed for Logtsash and the tight integration means we can easily incorporate Grok patterns into our Logstash configurations. On top of that, the plugin has been available for years and has a large community of users who share new patterns and best practices online.
Dissect Vs Grok
People often ask if they should use Grok or Dissect to parse their logs in Logstash.
While Grok uses regular expressions to match patterns within log lines, Dissect operates by splitting log lines into key-value pairs based on predefined delimiters such as spaces, commas, or other characters. Dissect is often faster and more efficient than Grok if our log formats have well-defined structures and consistent delimiters. It also means that Dissect configurations are simpler and more concise than Grok patterns, especially for straightforward log formats. However, it is worth noting that Dissect is less flexible than Grok when dealing with more complex unstructured log data. We can decide to use one or the other, or both for a hybrid use case when a section of the line is reliably repeated, but the entire line is not.
Now that we have learned more about Grok and the alternatives let’s dive into Logstash Grok filters.
Theory
In a CSV file, each record has an identical list of fields. The sequence of these fields repeats predictably for any program to read in a structured way. Naturally, this is an ideal situation for Elasticsearch.
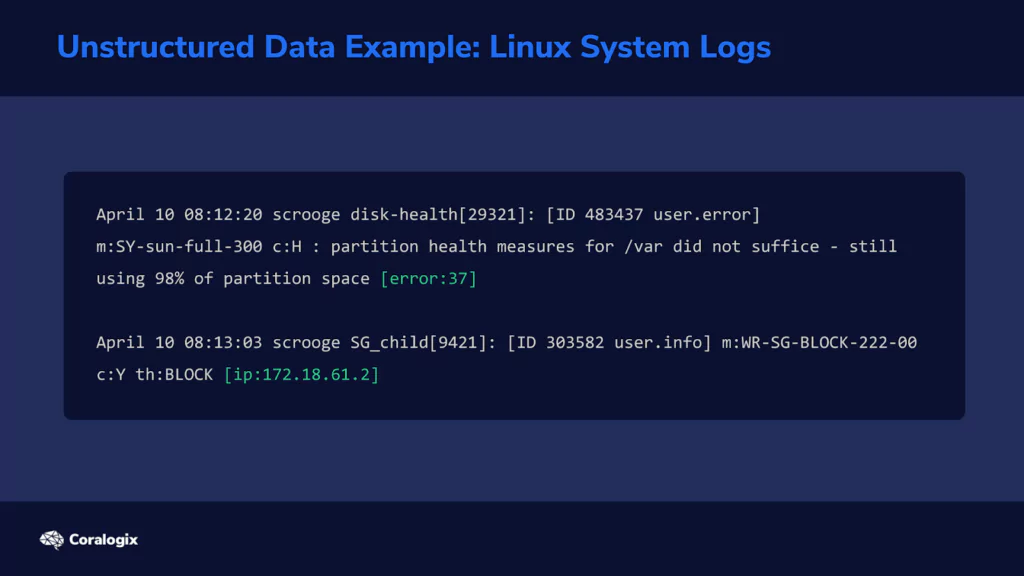
In other cases, information cannot be organized in this ideal way. Consider a typical Linux system log.
Multiple programs write their status or error messages to the same log file. On one line in the log, the last field might be an error code. But on the following line, the last field might be an IP address. This means that the parser now needs to have a way to “detect” what each field represents. Let’s look at how the Grok filter does this.
Understanding Grok Patterns and Syntax
When we see something like “[email protected],” we immediately think of “email address” because we have learned to recognize this pattern. Grok can do the same thing by analyzing each piece of text and checking if it matches the patterns you instruct it to look for.
Grok uses regular expressions, or RegEx for short, behind the scenes, which can look weird for someone unfamiliar. For example, here’s how a regular expression that matches an email looks like:
Fortunately, many common expressions are already predefined in Logstash’s Grok filter, and we can use their pattern names instead of writing those complicated strings of characters ourselves.
We can find a list of these predefined pattern names on the documentation page for the Grok filter plugin.
The generic Grok syntax looks like this:
In a nutshell, we tell it what pattern to look for and how to label the strings that match those patterns.
Back to our earlier example, this is how to define and label email addresses:
This Grok pattern will look for all email addresses and identify each as “client_email.” You’re free to choose whatever identifier name you want.
In our case, identifiers will be used as field names for matched values that will be imported to the index. We’ll see how this works in the hands-on exercises to follow.
Example Grok Filter
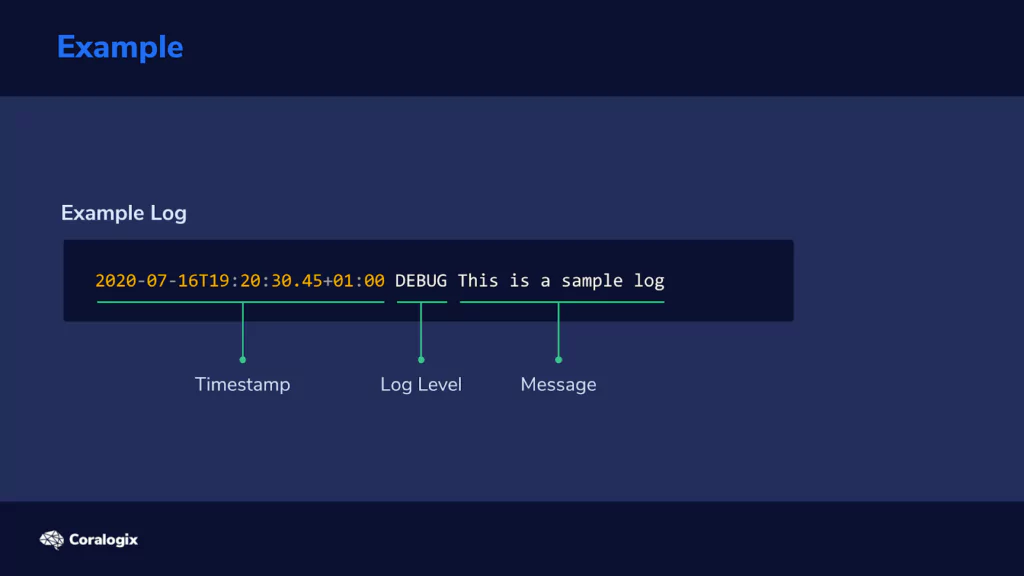
Let’s analyze how we would use Grok. Consider the following line in a log file:
We can see three logical components here: a timestamp, the level of logging, and the error or status message.
The timestamp is in the so-called ISO format, which is useful since we have a Grok pattern that is already available.
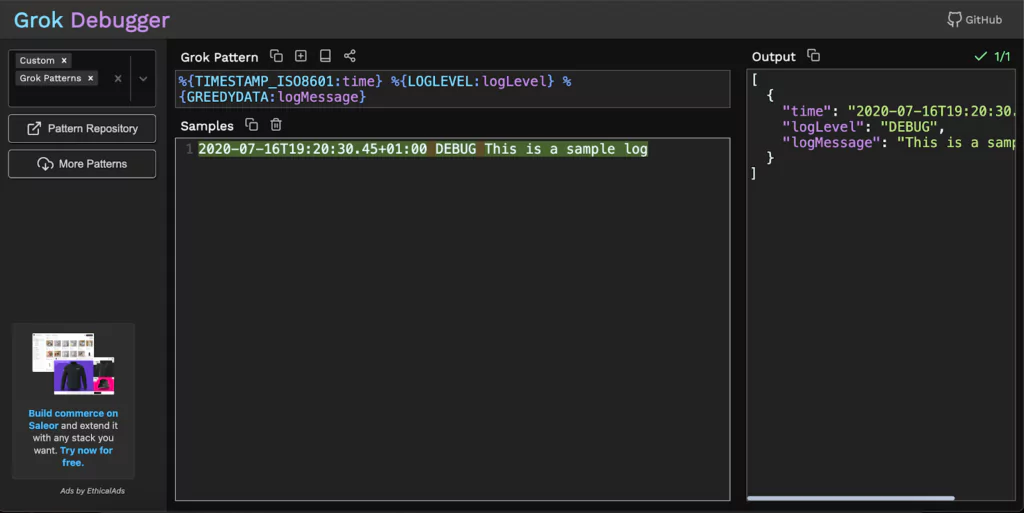
How would we define a Grok filter that would extract the three components from this piece of log text? Well, here it is:
GREEDYDATA might sound mysterious, but all it does is match all other characters in the string analyzed, so it extracts the rest of the text.
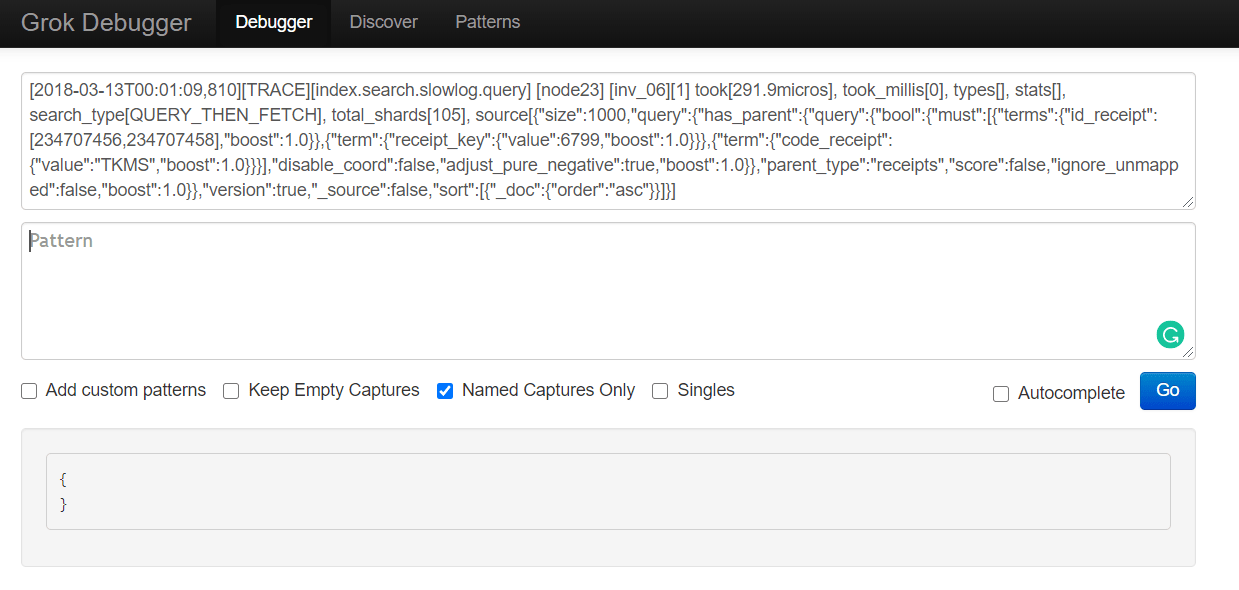
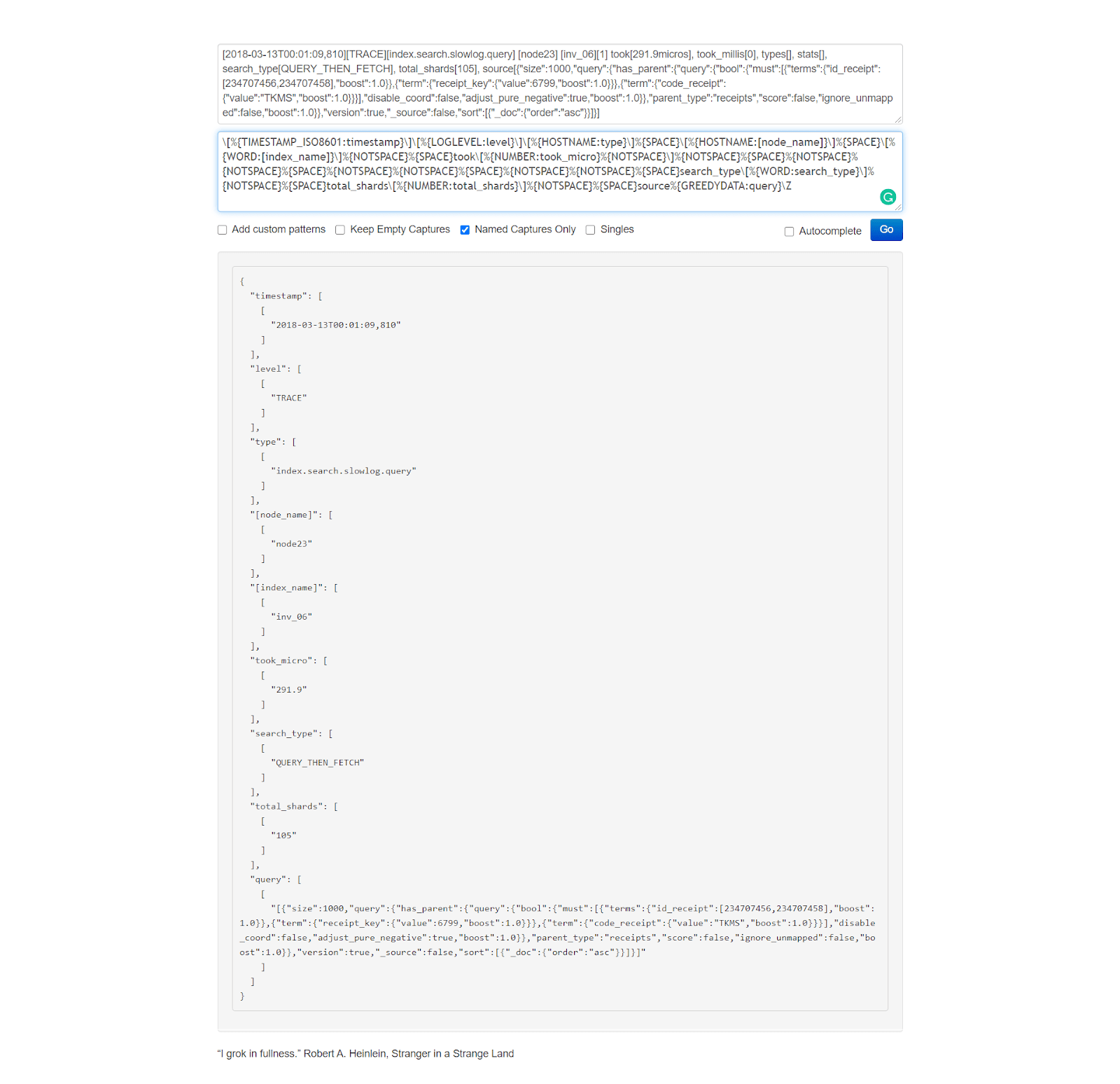
Naturally, we would also like to test these Grok filters and see if they work as intended, on our specific data. For this purpose, we can use the Grok Debugger tool.
With the Grok Debugger, we can copy and paste the Grok filter in the first “Grok Pattern” field and the example log line in the second “Samples” field.
The output would look like this:
Now that we’ve established some Grok fundamentals, let’s explore the concepts using various examples.
Hands-On Exercises
Parsing a Log File with Grok
Let’s apply this newly acquired knowledge and see how to use the Logstash Grok filter plugin on a sample log file.
First, let’s create a directory where we will store our sample data:
$ mkdir -p /home/student/03-grok-examples
Next, let’s create the file we will parse:
$ nano /home/student/03-grok-examples/sample.log
Now let’s copy and paste the following text into the nano editor:
2020-10-11T09:49:35Z INFO variable server value is tomcat
2020-03-14T22:50:34Z ERROR cannot find the requested resource
2020-01-02T14:58:40Z INFO initializing the bootup
2020-06-04T06:56:04Z DEBUG initializing checksum
2020-05-07T03:07:11Z INFO variable server value is tomcat
Finally, let’s press CTRL+X, then type Y and then press ENTER to save the file.
We can now create the Logstash configuration file:
Once again, we press CTRL+X, followed by Y and then ENTER to save the file.
We can see the configuration under the filter section is quite straightforward. We instruct Logstash to use the grok filter plugin and add match instructions where we used the same patterns and identifiers we explored earlier.
After a few seconds, the output shows that the entries have been parsed and imported. At that point, we can press CTRL+C to exit from Logstash.
Let’s explore the contents added to the index:
$ curl -XGET "https://localhost:9200/demo-grok/_search?pretty=true" -H 'Content-Type: application/json' -d'{
"_source": [
"logLevel",
"time",
"logMessage"
]
}'
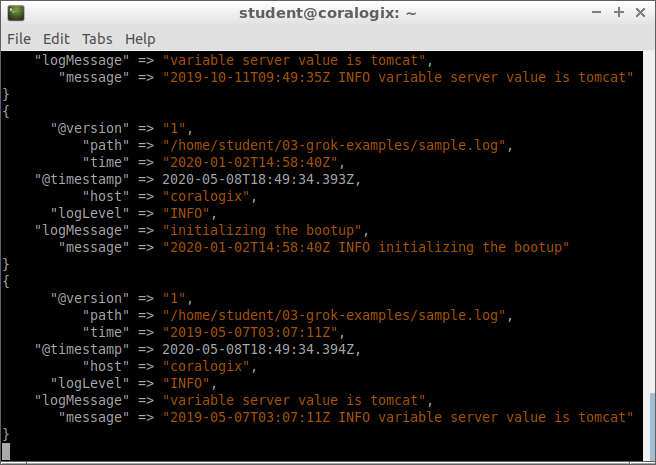
We’ll see our log entries neatly organized in the proper fields. Here’s an example of a document from the index:
In our scenario, things are optimal since each log line has precisely three components, in the same order and each matches every Grok pattern. But what if some text didn’t match any pattern we defined?
How Grok Deals with Lines that Don’t Match Patterns
Let’s edit our sample log:
$ nano /home/student/03-grok-examples/sample.log
and add the following line at the end:
55.12.32.134 GET /user/id/properties
Our sample log should now have six lines and look like this:
2020-10-11T09:49:35Z INFO variable server value is tomcat
2020-03-14T22:50:34Z ERROR cannot found the requested resource
2020-01-02T14:58:40Z INFO initializing the bootup
2020-06-04T06:56:04Z DEBUG initializing checksum
2020-05-07T03:07:11Z INFO variable server value is tomcat
55.12.32.134 GET /user/id/properties
Once again, we press CTRL+X, then Y and ENTER to save the file.
We don’t want to write over previous data we imported into our index, so let’s delete that first:
We can see that the document lacks the fields “time,” “logLevel,” and “logMessage.” The “message” field shows the line from our sample log that generated this document. We can see that this line doesn’t have any fields matching our Grok filter patterns. A tag called _grokparsefailure is added to signal that the parser had trouble with this line from the file.
We now saw what happens when Grok patterns can’t match anything on a line. Let’s explore the next scenario.
Multiple Grok Filters to Parse Complex Files
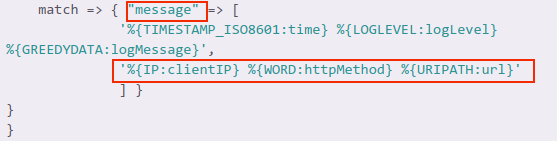
In our previous Logstash configuration, Grok tried to match our three patterns against each line in the sample log. But what if we want each line scanned for a second pair of patterns in case the first pair doesn’t match anything?
For example, in our case, if the line doesn’t have a timestamp, log level and log message, then Grok should try to search for another set of patterns. In this scenario, it will look for an IP address, an HTTP method and a URL.
We also see that these two sets of patterns are separated by a comma. So it’s pretty straightforward to add multiple pairs of patterns to a Grok filter.
But why would we do this? Well, this way, we can process complex logs where multiple programs log to the same file, as one example. Say Nginx and MySQL logged to the same file. One set of patterns can deal with log lines generated by Nginx, the other set can deal with lines generated by MySQL.
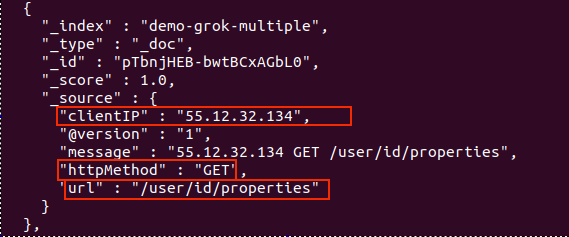
No more _grokparsefailure tags. Also, a new document corresponds to the new line we added to our sample log:
Nice! We got our log data neatly organized in Elasticsearch! We now have the freedom to parse almost any kind of text file, even if its information doesn’t follow a fixed pattern.
In the context of monitoring logging, multiline logs happen when a single log is written as multiple lines in the log file. This can either be caused by not using a standard logger to write with (e.g. print to console) or there’s a n (Newline) in the log to make it more readable (e.g. Java stack traces are error logs formatted as a list of stack frames)
When logs are sent to 3rd party full-stack observability platforms like Coralogix using standard shipping methods (e.g. Fluentd, Filebeat), which read log files line-by-line, every new line creates a new log entry, making these logs unreadable for the user. But, have no fear, there are many shipping methods that support pre-formatting multiline logs so that you are able to restructure, format, and combine the lines into single log messages.
Multiline Log Example
Here’s how a multiline log looks, using a Java stack trace log for this example:
09-24 16:09:07.042: ERROR System.out(4844): java.lang.NullPointerException
at com.temp.ttscancel.MainActivity.onCreate(MainActivity.java:43)
at android.app.Activity.performCreate(Activity.java:5248)
at android.app.Instrumentation.callActivityOnCreate(Instrumentation.java:1110)
at android.app.ActivityThread.performLaunchActivity(ActivityThread.java:2162)
at android.app.ActivityThread.handleLaunchActivity(ActivityThread.java:2257)
at android.app.ActivityThread.access$800(ActivityThread.java:139)
at android.app.ActivityThread$H.handleMessage(ActivityThread.java:1210)
When sending this log using a log shipper, each line will be considered as an independent log message since log files are read line by line (assuming new entry when encountering n) unless a multiline pattern was set in your configuration file.
Configurations with Multiline
Multiline is a configuration option, which should be configured by the user. As mentioned before, most shipping methods support adding multiline pattern options. We will review a few of the most common file shipper configurations and see how to configure multiline to work with them.
Logstash
Being part of the Elastic ELK stack, Logstash is a data processing pipeline that dynamically ingests, transforms, and ships your data regardless of format or complexity. Here is an example of how to implement multiline with Logstash.
The negate can be true or false (defaults to false). If true, a message not matching the pattern will constitute a match of the multiline filter and the what will be applied.
The what can be previous or Next. If the pattern matched, does the event belong to the next or previous event?
For more information on multiline using Logstash visit here.
Filebeat
Also developed by Elastic, Filebeat is a lightweight shipper for forwarding and centralizing logs and files. You can either forward data to your local Logstash and from there to Coralogix, or. you ship directly to our Logstash endpoint.
Within the filebeat.inputs under type–>log use:
multiline:
pattern: '^[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}'
negate: true
match: after
The negate can be true or false (defaults to false). If true, a message not matching the pattern will constitute a match of the multiline filter and the what will be applied.
The match can be after or before. If the pattern matched, does the event belong to the next or previous event? (The after setting is equivalent to previous in Logstash, and before is equivalent to next)
For more info on working with multiline in Filebeat, visit here.
FluentD
Fluentd is a data collector which lets you unify the data collection and consumption for better use and understanding of data.
The format_firstline specifies the regexp pattern for the start line of multiple lines. Input plugin can skip the logs until format_firstline is matched.
The formatN, N’s range is 1..20, is the list of Regexp formats for the multiline log. For readability, you can separate Regexp patterns into multiple regexpN parameters. These patterns are joined and constructs regexp pattern with multiline mode.
Note that in my example, I used the format1 line to match all multiline log text into the message field. Then, I used Coralogix parsing rules to parse my logs into a JSON format. For more information on Coralogix parsing rules visit here.
Fluent Bit is a multi-platform Log Processor and Forwarder which allows you to collect data/logs from different sources, unify and send them to multiple destinations.
The Main config, use:
[SERVICE]
Log_Level debug
Parsers_File /path/to/parsers.conf
[INPUT]
Name tail
Path /var/log/fluent-bit/*.log
Multiline On
Parser_Firstline multiline_pattern
parsers.conf file:
[PARSER]
Name multiline_pattern
Format regex
Regex ^[(?<timestamp>[0-9]{2,4}-[0-9]{1,2}-[0-9]{1,2} [0-9]{1,2}:[0-9]{1,2}:[0-9]{1,2})] (?<message>.*)
Note: In Fluent Bit, the multiline pattern is set in a designated file (parsers.conf) which may include other REGEX filters. At that point, it’s read by the main configuration in place of the multiline option as shown above. Secondly, in a Fluent Bit multiline pattern REGEX you have to use a named group REGEX in order for the multiline to work.
For more info on multiline in Fluent Bit visit here.
2017-03-29 10:00:00,123^%{TIMESTAMP_ISO8601} (In Logstash you can also use Grok patterns)
2017-03-29 Or Mar 22, 2020^(d{2,4}-d{2}-d{2,4}|[A-Za-z]{3} d{1,2}, d{4})
How to check for a multiline issue in Coralogix
It is recommended to look for multiline problems once integration was implemented so you can be sure your log collection works correctly. You can take a few steps in Coralogix to check whether you are dealing with a possible multiline issue:
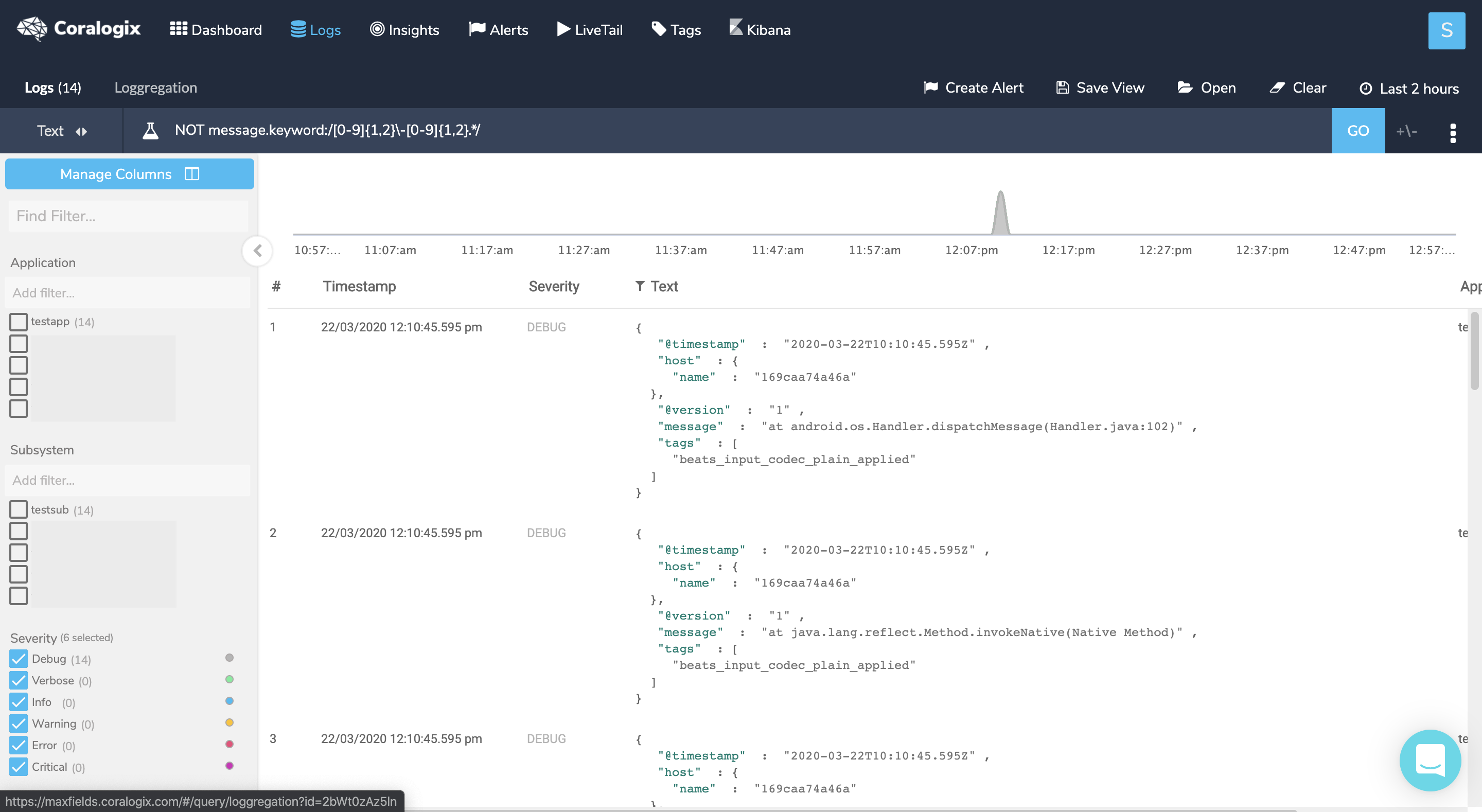
Given the above example of Java stack trace logs, when you know what is the beginning of a line you can create a NOT query on those logs to see if you have any logs that don’t start as expected, which might point to a multiline issue.
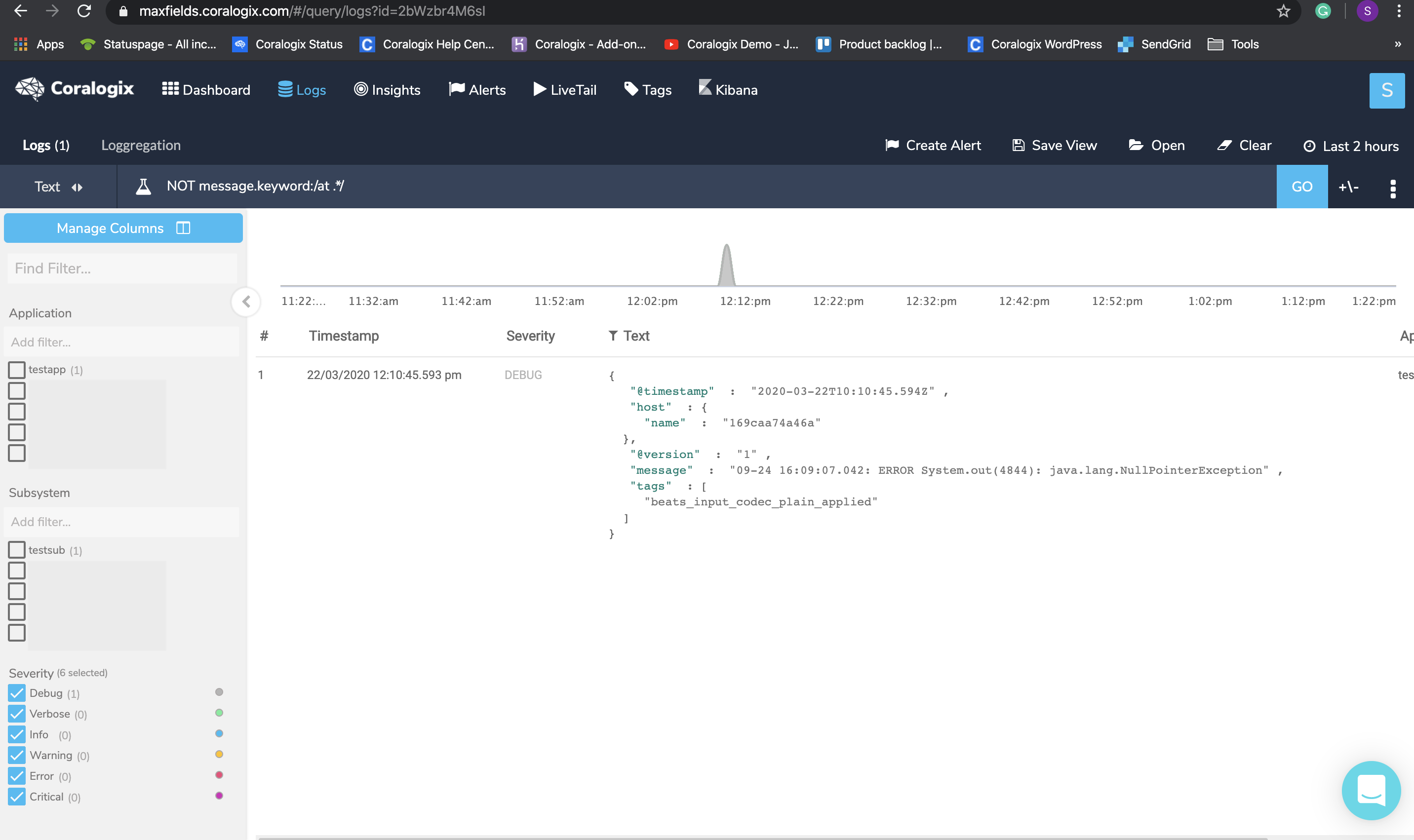
Query : NOT message.keyword:/[0-9]{1,2}-[0-9]{1,2}.*/
To verify that these logs are indeed part of another log entry click on one of them, then hover the +/- sign near the ‘GO’ button and choose a time interval (the min 5 seconds should suffice) and check whether you can find a log before the chosen log that represents its beginning. In our example, I would find the log that starts with the timestamp just right before the marked log. To solve this issue, set a new multiline pattern in your configuration and restart your service.
When you are not sure what is the beginning of a line but are encountering logs that don’t seem to represent a full log, you can create a NOT query on those logs to see what are their possible beginnings.
Query : NOT message.keyword:/at .*/
Click on the result, hover the +/- sign and check if you got any logs before or after the chosen log that might be a part of it. To solve this, set a new multiline pattern in your configuration and restart your service.
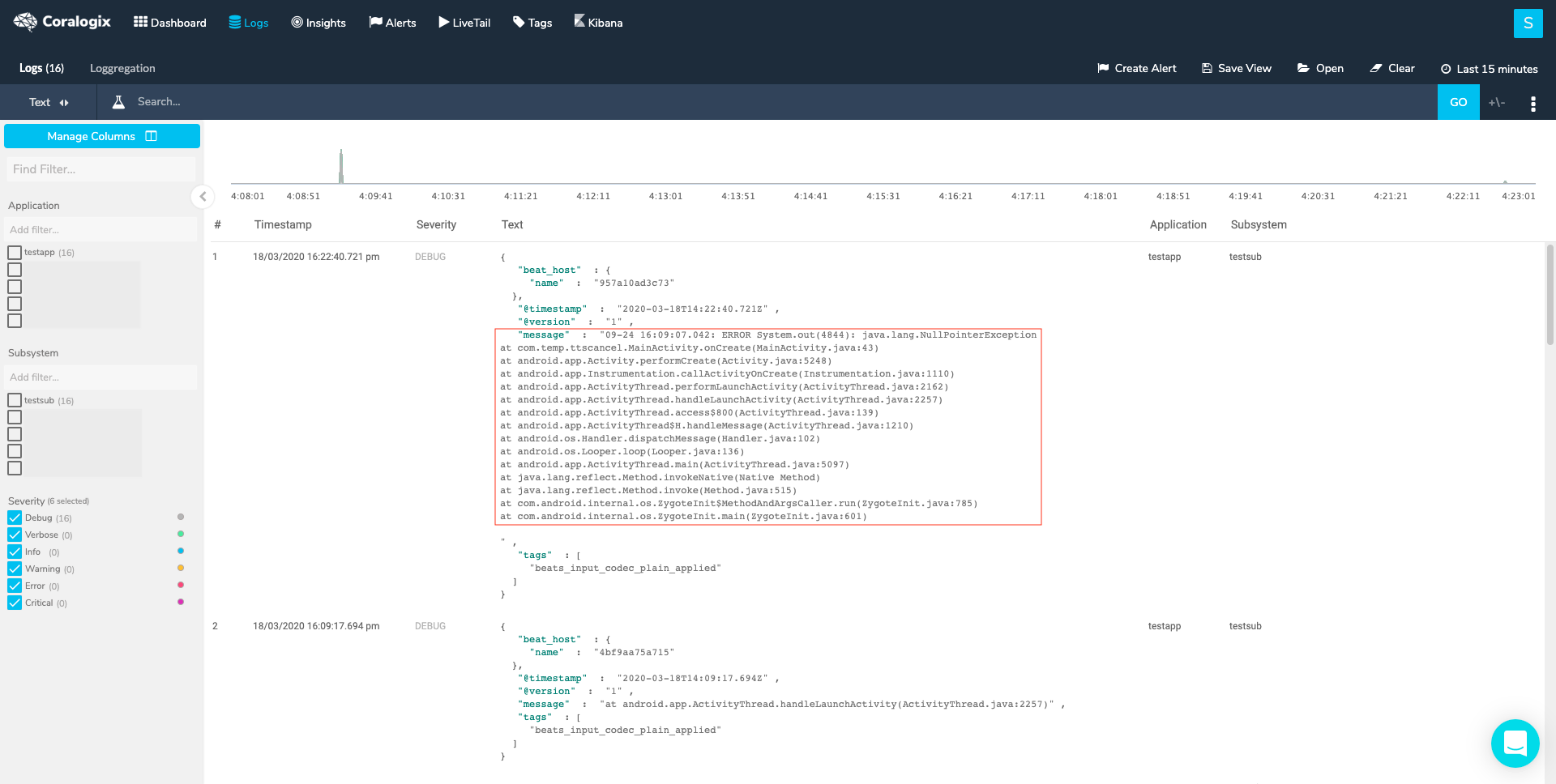
Use Loggregation to identify log templates that belong to multiline logs. Briefly, Loggregation is a Coralogix proprietary algorithm that condenses millions of log entries into a narrow set of patterns, allowing you to easily identify a case where the message field, within a template, doesn’t contain the full log message. After setting the right multiline in our configuration we should expect the full log entry to look like this:
Need help? check our website and in-app chat for quick advice from our product specialists.
Throughout the past few months, I had the opportunity to work with and serve hundreds of Coralogix’s customers, the challenges in performing efficient Log Analytics are numerous, from log monitoring, collecting, searching, visualizing, and alerting. What I have come to learn is that at the heart of each and every one of these challenges laid the challenge of data parsing. JSON structured logs are easier to read, easier to search, alert, and visualize. They can be queried using the ES API’s, exported to Excel sheets, and even be displayed in Grafana. So why is it that a lot of logs are still plain text by default and not structured?
As our focus here in Coralogix was always about our customers and their needs, we developed a parsing engine that allows a single UI to parse, extract, mask, and even exclude log entries in-app, or via API. To get you started with log parsing, we created pre-defined parsing rules for the 12 most common logs on the web.
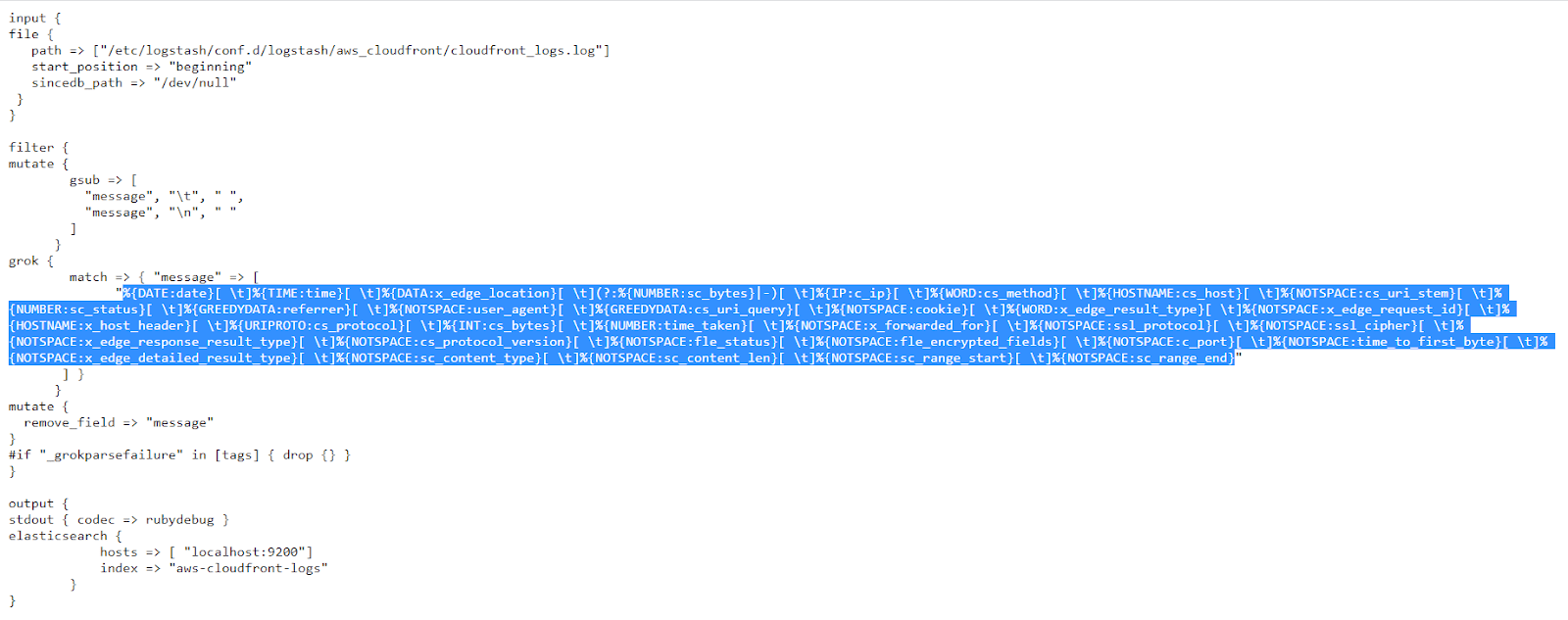
In this post, we collected the following log templates and created their own Named group REGEX in order to parse them into JSON structure logs in Coralogix: Apache logs, IIS, logs, MongoDB logs, ELB logs, ALB logs, CloudFront logs, Mysql logs, access logs, Nginx logs, Http headers, user agent field, java stack trace.
Note that every regex is submitted as a recommendation, of course logs can have different configurations and permutations, you can easily adjust the parsing rules below to your needs, more on named group regex here.
1. User Agent (Use an “Extract” rule in Coralogix):
Exception in thread "main" java.lang.NullPointerException
at com.example.myproject.Book.getTitle(Book.java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
Regular Expression
Exception(?: in thread) "(?P<threadName>[^"]+)" (?P<changethenamelater>.*)s+(?P<stackeholder>(.|n)*)
Results
{
"changethenamelater" : "java.lang.NullPointerException " ,
"stackeholder" : "at com.example.myproject.Book.getTitle(Book.java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)" ,
"threadName" : "main"
}
7. Basic HTTP Headers (Use a “Extract” rule in Coralogix):
 The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 




















{kind=link}
{kind=link}
{kind=link}
{kind=link}