The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

From production monitoring to security concerns, it’s critical for businesses to analyze and review their log data. This is particularly true for large and enterprise companies, where the sheer amount of data makes log analysis the most efficient way to track key indicators. CTOs, in particular, are dealing with the challenges of this massive amount of data flowing through their organization, including how to harness it, gather insights from it, and secure it.
When it comes to the best platforms for log analysis and security information and event management (SIEM) solutions, 3 trivial Elk Stack alternatives come up: Splunk, Sumo Logic, and ELK.
Choosing which of these big guns to go with is no easy task. We’ll look at these top three platforms, including their advantages and disadvantages, and see who comes out the winner.
What is Splunk?
Splunk Enterprise is a platform to aggregate and analyze data. With Splunk, you can automate the collection, indexing, monitoring, and alerting functions when it comes to your data to control and leverage the information flowing into your business.
Scheduled searches let you create real-time dashboards and visualizations (offering both XML and drag-and-drop style customization options for visualization), while scheduled reports enable you to run and share reports at various intervals. In terms of support and community, Splunk hosts Splunkbase, which has thousands of apps and add-ons.
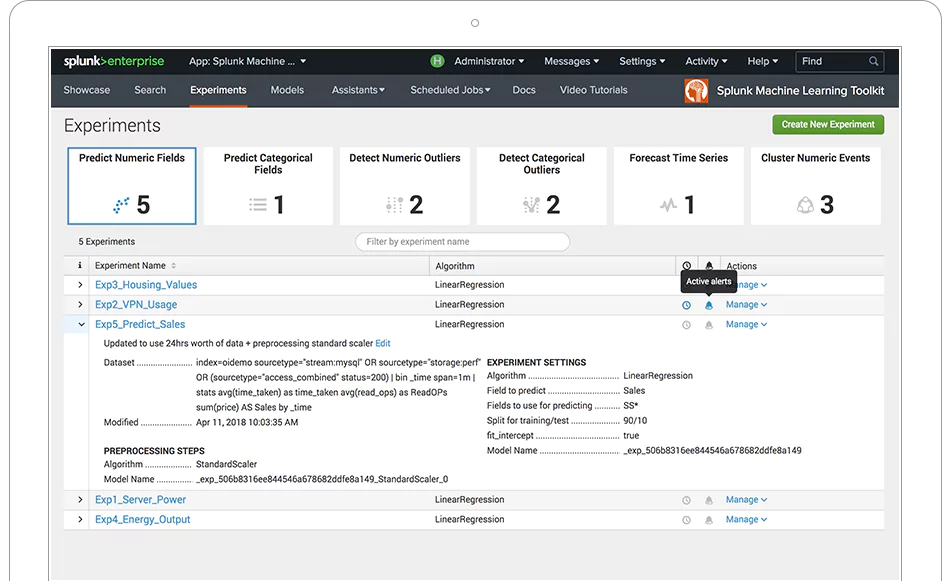
The platform has the functionality to be used by experts as well less technically-inclined users. It scales well – with the ability to scale up to unlimited amounts of data per day – and has built-in failover and disaster recovery capabilities.
In addition to the self-hosted Splunk Enterprise, there is also the Splunk Cloud option, where Splunk is deployed and managed as a service.
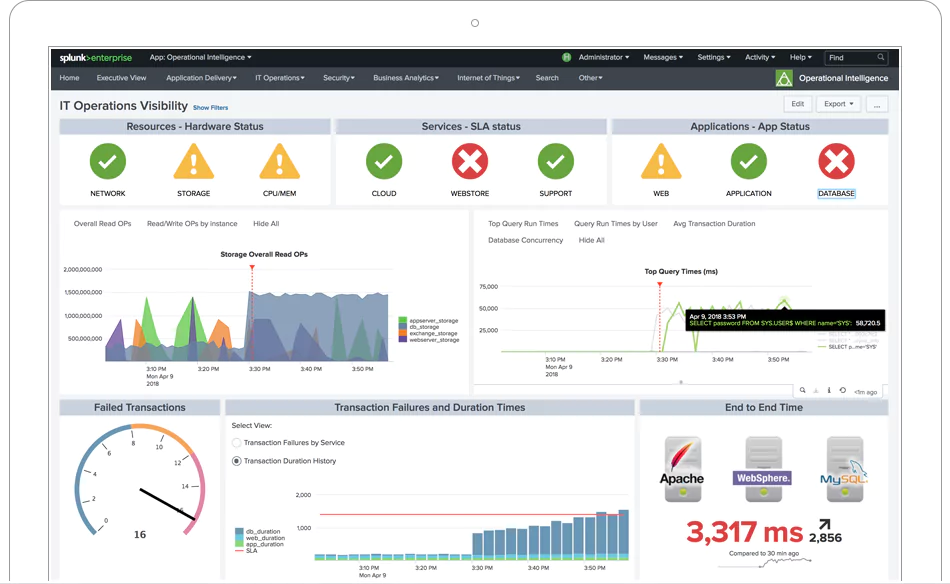
The pros of Splunk
Splunk is good at what it does, which is primarily fast consolidation of logs to be able to search data and find insights.
The cons of Splunk
The biggest concern with Splunk is the complexity of setting it up and maintaining it. It has a relatively steep learning curve and can take time to get going properly and manage on an ongoing basis. The other major issue to be aware of is pricing, which can be quite high.
Understanding Splunk’s pricing
Splunk Enterprise starts at $173 per ingested GB, is quoted per month. It is billed annually, and includes standard (not premium, though this is available) support.
What is Sumo Logic?
Sumo Logic is a cloud-native, machine data analytics service for log management and time series metrics. With the service, you can build, run and secure your AWS, Azure, Google Cloud Platform, or hybrid applications.
How does Sumo Logic compare with Splunk?
The biggest difference when compared with Splunk is that Sumo Logic is built for the cloud; even though Splunk now offers its Splunk cloud option, Sumo Logic’s architecture is built around cloud usage.
This means integrations are smoother, particularly when it comes to platforms such as AWS; scalability is built-in, there is no need for constant updates, and getting started is quicker and easier than with Splunk.
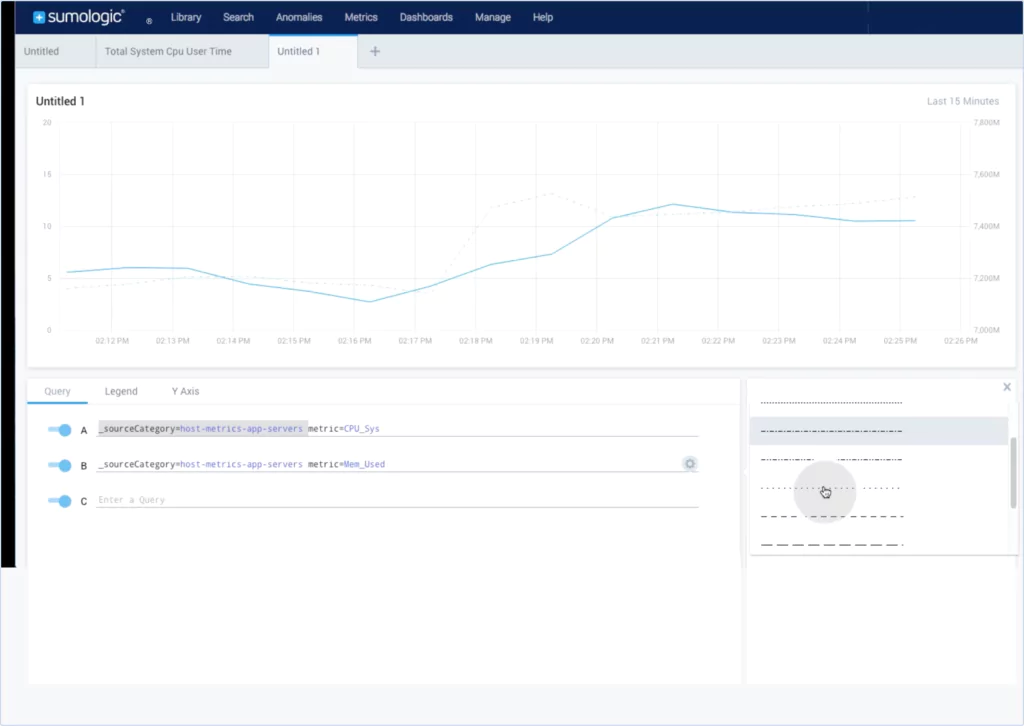
The pros of Sumo Logic
Sumo Logic is easy to use and has all the advantages of being a SaaS solution, such as scalability, getting up and running quickly, and so on. Some people like the UI, while others prefer the other offerings’ look and feel.
The cons of Sumo Logic
Sumo Logic lacks some of the extended features of Splunk, particularly when it comes to the Splunk Enterprise offering. There have been complaints about Sumo Logic’s speeds when searching older data, its customer service, and its pricing being on the expensive side. Sumo Logic also lacks some of the community support of Splunk and particularly ELK.
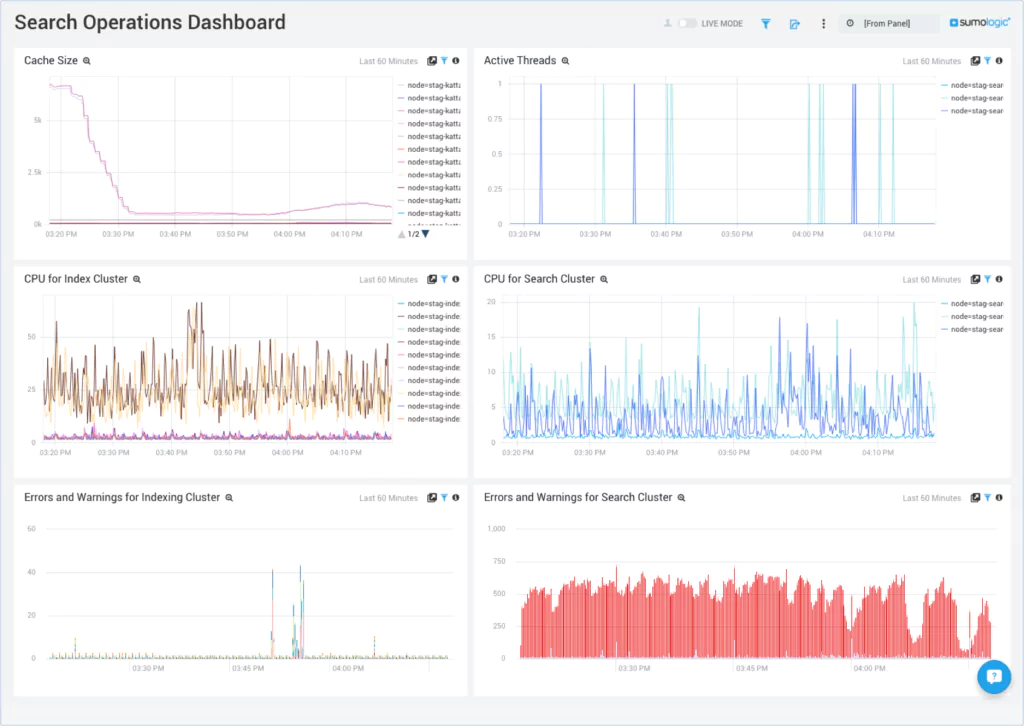
Understanding Sumo Logic pricing
The Sumo Logic Enterprise platform starts at $150 per GB per month, with an annual commitment required. If you want the full support package, it’s an optional add-on to this package.
What is ELK?
ELK is the world’s most popular log management platform. The ELK Stack is made up of three different solutions, all of them open-source: Elasticsearch, Logstash, and Kibana.
Elasticsearch is a search engine based on Lucene that provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Logstash collects, parses, and stores logs, and Kibana is a data visualization tool. Also included as part of the stack is Beats, a platform for lightweight shippers that sends data from edge machines to Logstash and Elasticsearch. With the addition of Beats, ELK Stack became known as the Elastic Stack.
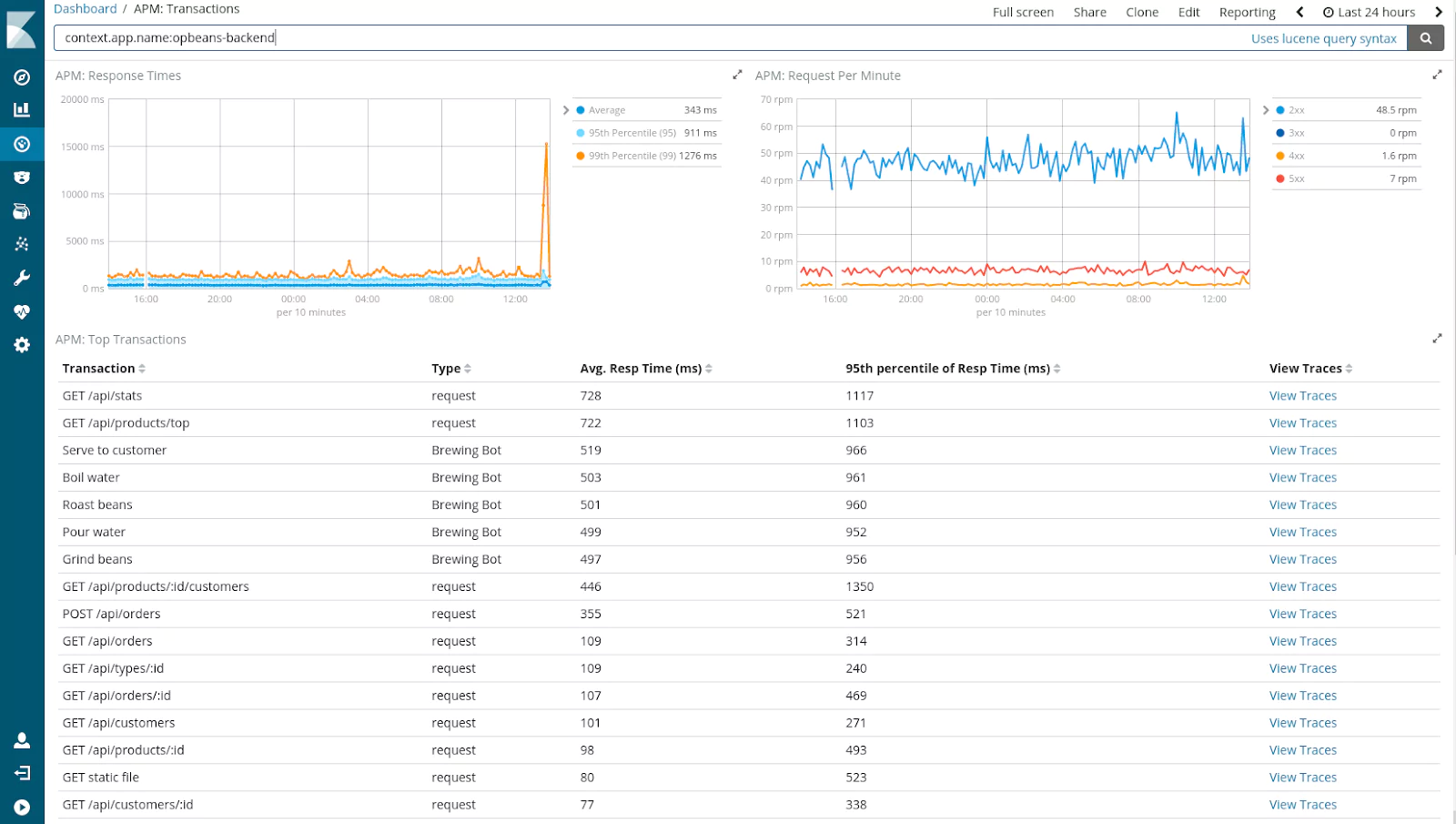
With ELK, you can reliably and securely ingest data from any source, in any format and search, analyze, and visualize it in real-time. Being open source, it’s been rigorously tested by the large ELK community and is trusted by companies such as Sprint, Microsoft, eBay, and Facebook.
The pros of ELK
ELK consolidates three mature components to form one powerful solution. Being an open source tool, there are numerous benefits that come with the adoption of ELK. In general, there has been a tremendous movement towards open source, particularly for enterprises.
Open source solutions come with a lot of control, where you aren’t tied to a rigid way of doing things, and open source tools, especially ones like ELK/Elastic Stack, bring with them a vibrant community of contributors, testers, and fellow users who can contribute to your success.
The cons of ELK
If you are setting up yourself, it can be challenging to set up and maintain. Most users go with a solution that handles the setup for them.
Understanding ELK’s pricing
ELK is free (if you are using the open source version without X-pack).
Which platform is the best?
Given our significant combined experience with all of these platforms, deciding which one to pick had to be carefully weighed up. The functionality and feature set of Splunk, the simplicity and cloud-native advantages of Sumo Logic, and the open source design and robust nature of ELK.
A winner had to be chosen, and based on all of our research and experience, it had to be ELK – thanks to its vibrant community, the fact that it’s constantly improving and evolving faster than its competitors, has better JSON format support, is easier to use and get started with, and of course, comes in at a much lower price.
This is despite its drawbacks – the standard versions of it lack alerting, anomaly detection, and integrations into the development lifecycle – overall, however, it stands above the others as an all-round tool.
Being on top of your logs is critical, whether it’s for production monitoring and debugging, security purposes, resource usage, or any other of the multitude of key business functions log analysis supports.
With Coralogix’s platform, you can know when your flows break, automatically cluster your log data back into its original patterns so you can view hours of data in seconds, see all of your organization’s key indicators at a glance, and a whole lot more.
Interested in finding out more about how your organization can benefit? Check out Coralogix to see how we can help.
(This article was updated in August 2023)