The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

Security is a top-of-mind topic for software companies, especially those that have experienced security breaches. This article will discuss how to set up Elasticsearch audit logging and explain what continuous auditing logs track.
Alternatively, platforms can use other tools like the cloud security platform offered by Coralogix instead of internal audit logging to detect the same events with much less effort.
Companies must secure data to avoid nefarious attacks and meet standards such as HIPAA and GDPR. Audit logs record the actions of all agents against your Elasticsearch resources. Companies can use audit logs to track activity throughout their platform to ensure usage is valid and log when events are blocked.
Elasticsearch can log security-related events for accounts with paid subscriptions. Elasticsearch audit provides logging of events like authentications and data-access events, which are critical to understanding who is accessing your clusters, and at what times. You can use machine learning tools such as the log analytics tool from Coralogix to analyze audit logs and detect attacks.
Turning on Audit Logging in Elasticsearch
Audit General Settings
Audit logs are off by default in your Elasticsearch node. They are turned on by configuring the static security flag in your elasticsearch.yml (or equivalent .yml file). Elasticsearch requires this setting for every node in your cluster.
xpack.security.audit.enabled=true
Enabling audit logs is currently the only static setting needed. Static settings are only applied, or re-applied, to unstarted or shut down nodes. To turn on Elasticsearch audit logs, you will need to restart any existing nodes.
Audit Event Settings
You can decide what events are logged on each Elasticsearch node in your cluster. Using the events.include or events.exclude settings, you can decide which security events Elasticsearch logs into its’ audit file. Using _all as your include setting will track everything. The exclude setting can be convenient when you want to log all audit event types except one or two.
xpack.security.audit.logfile.events.include=[_all]
xpack.security.audit.logfile.events.exclude=[run_as_granted]You can also decide if the request body that triggered the audit log is included in the audit event log. By default, this data is not available in audit logs. If you need to audit search queries, use this setting, so the queries are available for analysis.
xpack.security.audit.logfile.events.emit_request_body=true
Audit Event Ignore Policies
Ignore policies allow you to search for audit events that you do not want to print. Use the policy_name value to link configurations together and form a policy with multiple settings. Elasticsearch does not print events that match all conditions in a policy.
Each of the ignore filters uses a list of values or wildcards. Values are known data for the given type.
xpack.security.audit.logfile.events.ignore_filters.<policy_name>.users=[*]
xpack.security.audit.logfile.events.ignore_filters.<policy_name>.realms=[*]
xpack.security.audit.logfile.events.ignore_filters.<policy_name>.actions=[*]
xpack.security.audit.logfile.events.ignore_filters.<policy_name>.roles=[*]
xpack.security.audit.logfile.events.ignore_filters.<policy_name>.indices=[*]Node Information Inclusion in Audit Logs
Information about the node can be included in each audit log event. Each of the following settings is used to turn on one of the pieces of information that are available. By default, all are excluded except the node id value. Optional node data includes the node name, the node IP address, the node’s host name, and the node id.
xpack.security.logfile.emit_node_name=true
xpack.security.logfile.emit_node_host_address=true
xpack.security.logfile.emit_node_host_name=true
xpack.security.logfile.emit_node_id=trueInformation Available in Elasticsearch Audit
Elasticsearch audit events are logged into a single JSON file. Each audit event is printed on a single line with no end-of-line delimiter. The format of the file is similar to a CSV in that it was meant to have columns. There are fields within it that follow JSON formatting with an ordered dot notation syntax containing any non-null string. The purpose was to make the file more easily readable by people as opposed to machines.
An example of an Elasticsearch audit log is below. In it, there are several fields that are needed for analysis. For a complete list of the audit logs available, see the Elasticsearch documentation.
{"type":"audit", "timestamp":"2021-06-23T07:51:31,526+0700", "node.id":
"1TAMuhilWUVv_hBf2H7yXW", "event.type":"ip_filter", "event.action":
"connection_granted", "origin.type":"rest", "origin.address":"::3",
"transport.profile":".http", "rule":"allow ::1,127.0.0.1"}The event.type attribute shows the internal layer that generated the audit event. This may be rest, transport, ip_filter, or security_config_change. The event.action attribute shows what kind of event occurred. The actions available depend on the event.type value, with security_config_change types having a different list of available actions than the others.
The origin.address attribute shows the IP address at the source of the request. This IP address may be of the remote client, the address of another cluster, or the local node. In cases where the remote client connects to the cluster directly, you will see the remote IP address here. Otherwise, the address is listed with the first OSI layer 3 proxy in front of the cluster. The origin.type attribute shows the type of request made originally. This could be rest, transport, or local_node.
Where Elasticsearch Stores Audit Logs
A single log file is created for each node in your Elasticsearch cluster. Audit log files are written only to a local filesystem to keep the file secure and ensure durability. The default filename is <clustername>_audit.json.
You can configure Filebeat in the ELK stack to collect events from the JSON file and forward them to other locations, such as back to an Elasticsearch index or into Logstash. Filebeat replaced the older model of Elasticsearch, where audit logs were sent directly to an index without queuing. This model caused logs to be dropped if the index rate of the audit log index was lower than the rate of incoming logs.
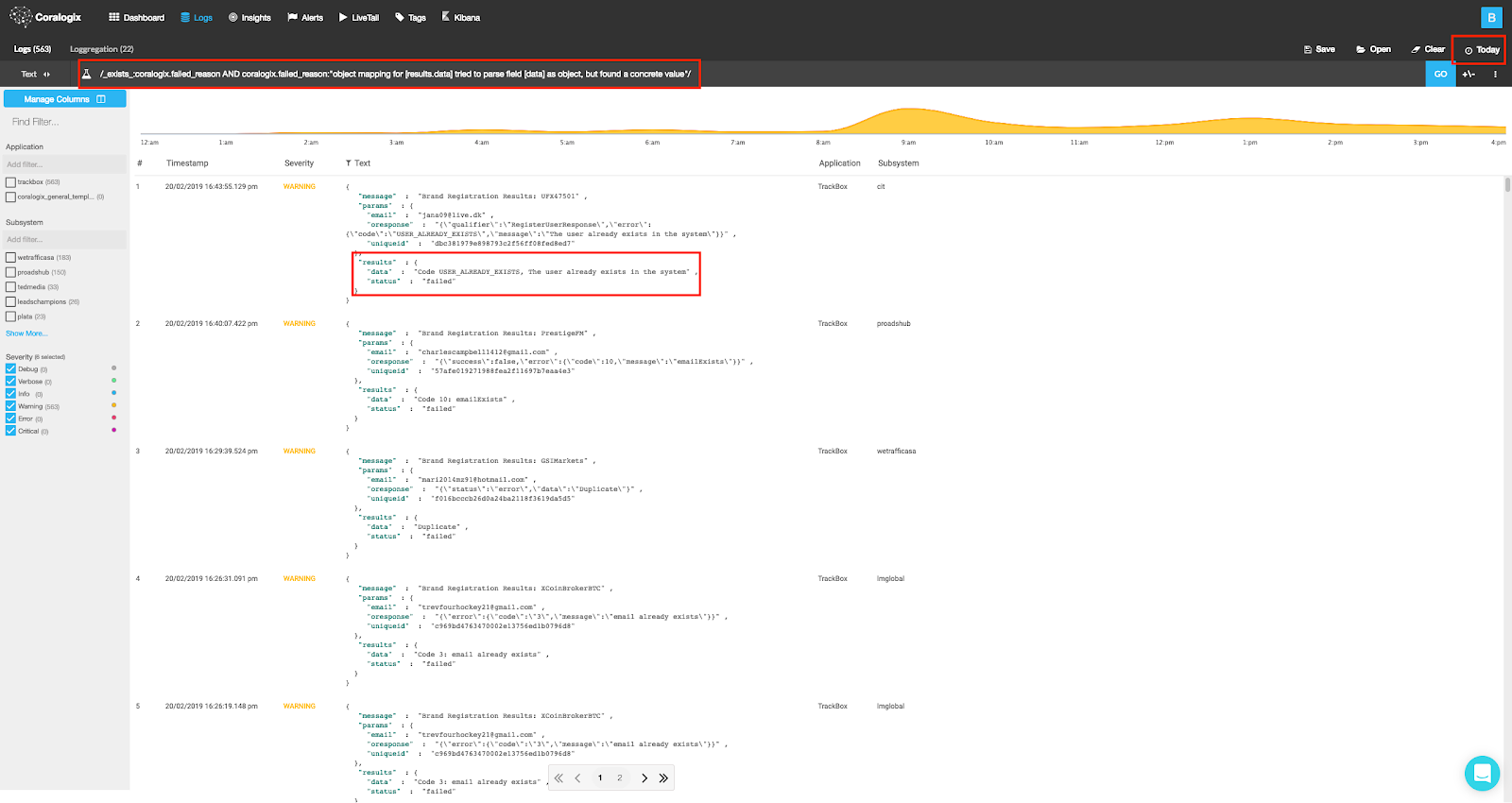
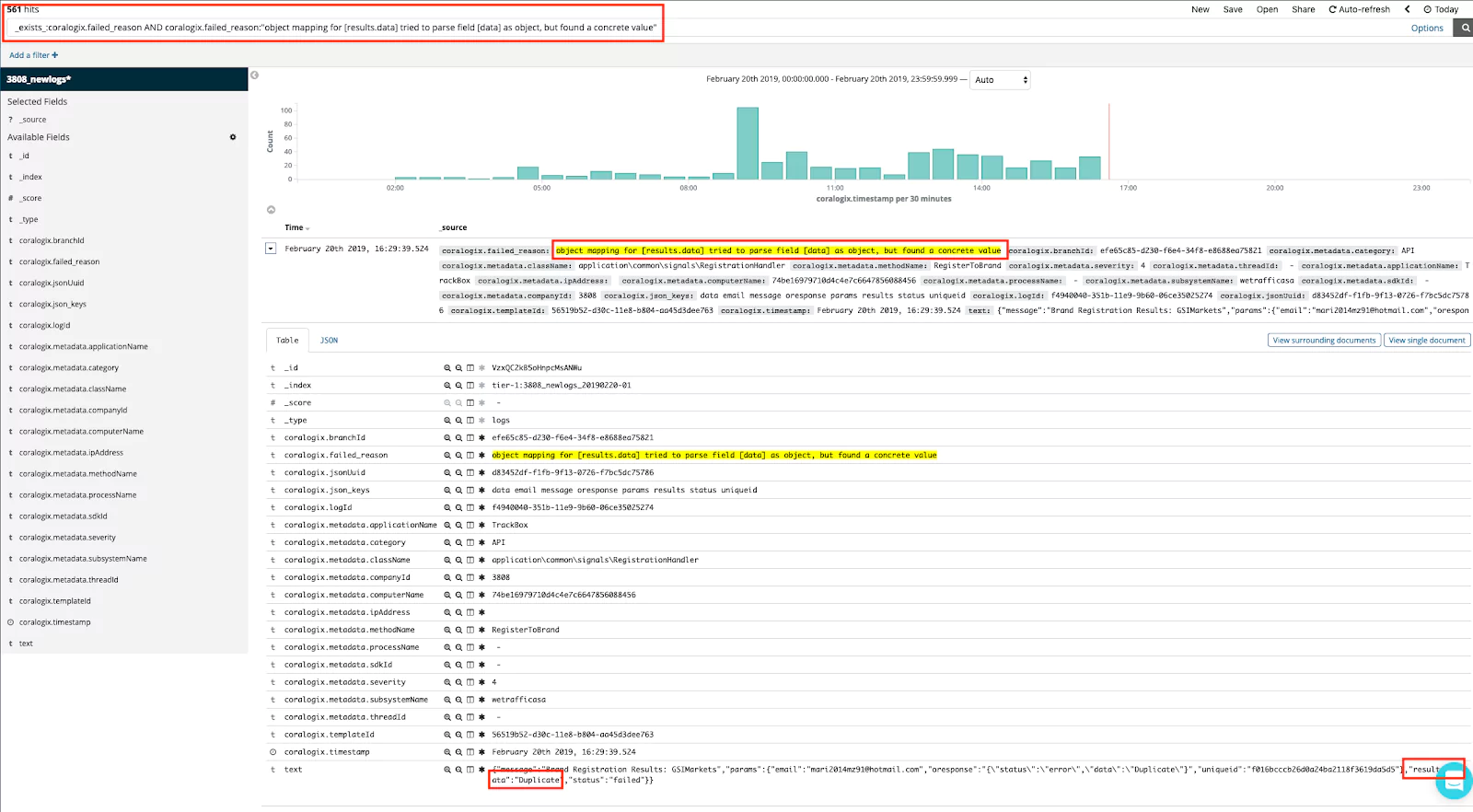
This index ideally will be on a different node and cluster than where the logs were generated. Once the data is in Elasticsearch, it can be viewed on a Kibana audit logs dashboard or sent to another source such as the Coralogix full-stack observability tool, which can ingest data from Logstash.
Configuring Filebeat to Write Audit Logs to Elasticsearch
After the Elasticsearch audit log settings are configured, you can configure the Filebeat settings to read those logs.
Here’s what you can do:
- Install Filebeat
- Enable the Elasticsearch module, which will ingest and parse the audit events
- Optionally customize the audit log paths in the elasticseach.yml file within the modules.d folder. This is necessary if you have customized the name or path of the audit log file and will allow Filebeat to find the logs.
- Specify the Elasticsearch cluster to index your audit logs. Add the configuration to the output.elasticsearch section of the filebeat.yml file
- Start Filebeat
Analysis of Elasticsearch Audit Logs
Elasticsearch audit logs hold information about who or what is accessing your Elasticsearch resources. This information is required for compliance through many government information standards such as HIPAA. In order for the data to be useful in a scalable way, analysis and visualization are also needed.
The audit logs include events such as authorization successes and failures, connection requests, and data access events. They can also include search query analysis when the emit_request_body setting is turned on. Using this data, professionals can monitor the Elasticsearch cluster for nefarious activity and prevent data breaches or reconstruct events. The completeness of the event type list means that with the analysis you can follow any given entity’s usage on your cluster.
If automatic streaming is available from Logstash or Elasticsearch, audit logs can be sent to other tools for analysis. Automatic detection of suspicious activity could allow companies to stop data breaches. Tools such as Coralogix’s log analysis can provide notifications for these events.
How does Coralogix fit in?
With Coralogix, you can send logs with our log analytics tool. This tool uses machine learning to find where security breaches are occurring in your system. You can also set up the tool to send notifications when suspicious activity is detected.
In addition, the Coralogix security platform allows users to bypass the manual setup of Elasticsearch audit logging by detecting the same access events. This platform is a Security as Code tool that can be linked directly to your Elasticsearch cluster and will automatically monitor and analyze traffic for threats.
Summary
Elasticsearch audit logs require a paid Elasticsearch subscription and manual setup. The logs will track all requests made against your Elasticsearch node and log them into a single, locally stored JSON file. Your configuration determines what is and is not logged into the audit file.
Your locally-stored audit file was formatted with the intention of being human-readable. However, reading this file is not a scalable or recommended security measure. You can stream audit logs to other tools by setting up Filebeat.