The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

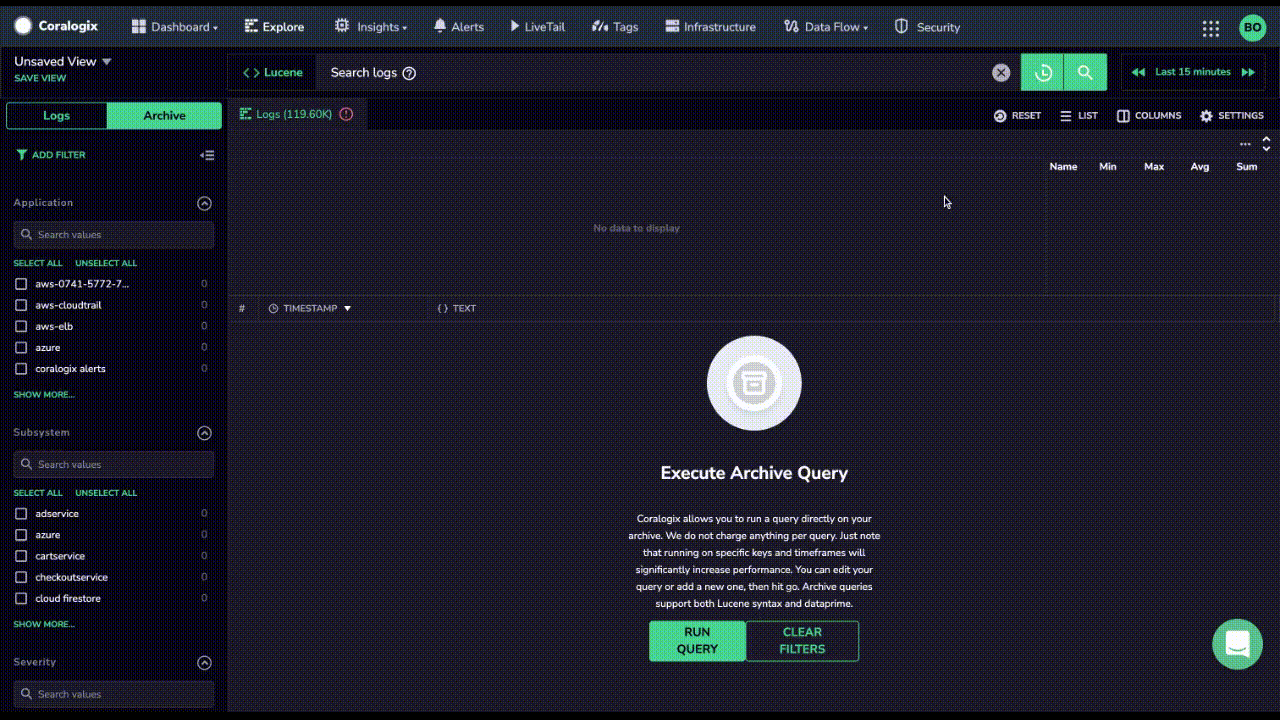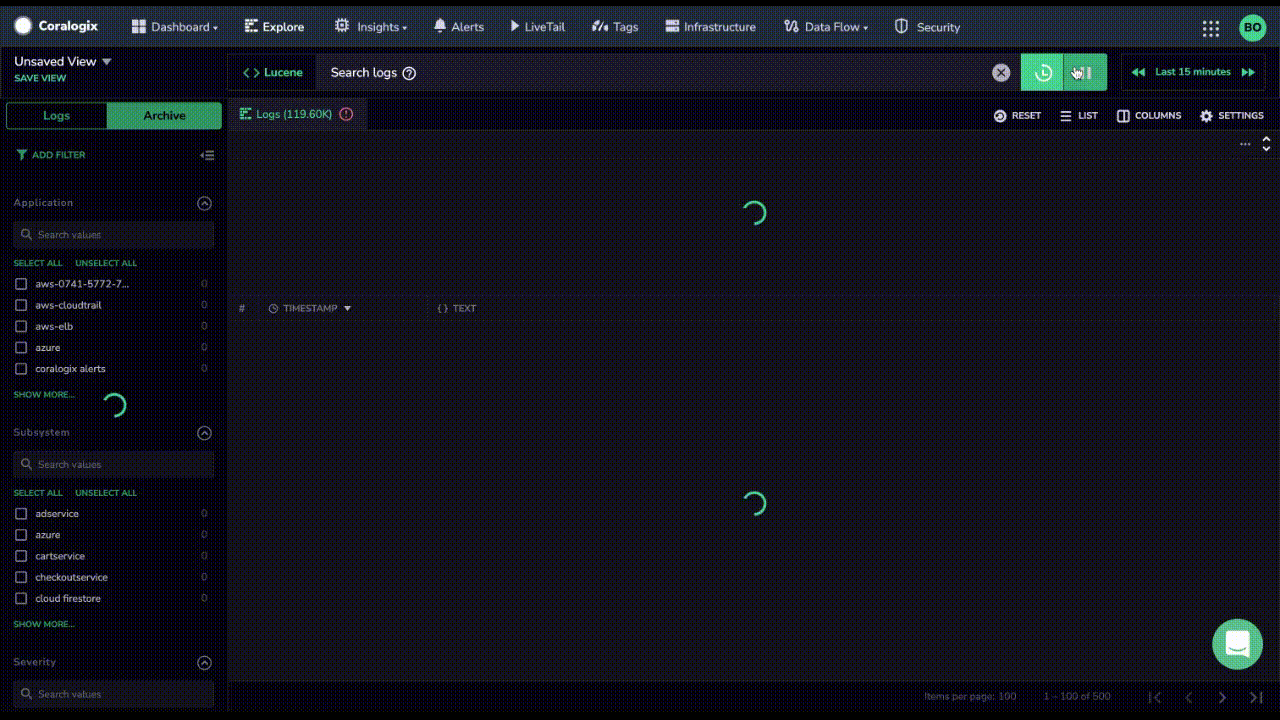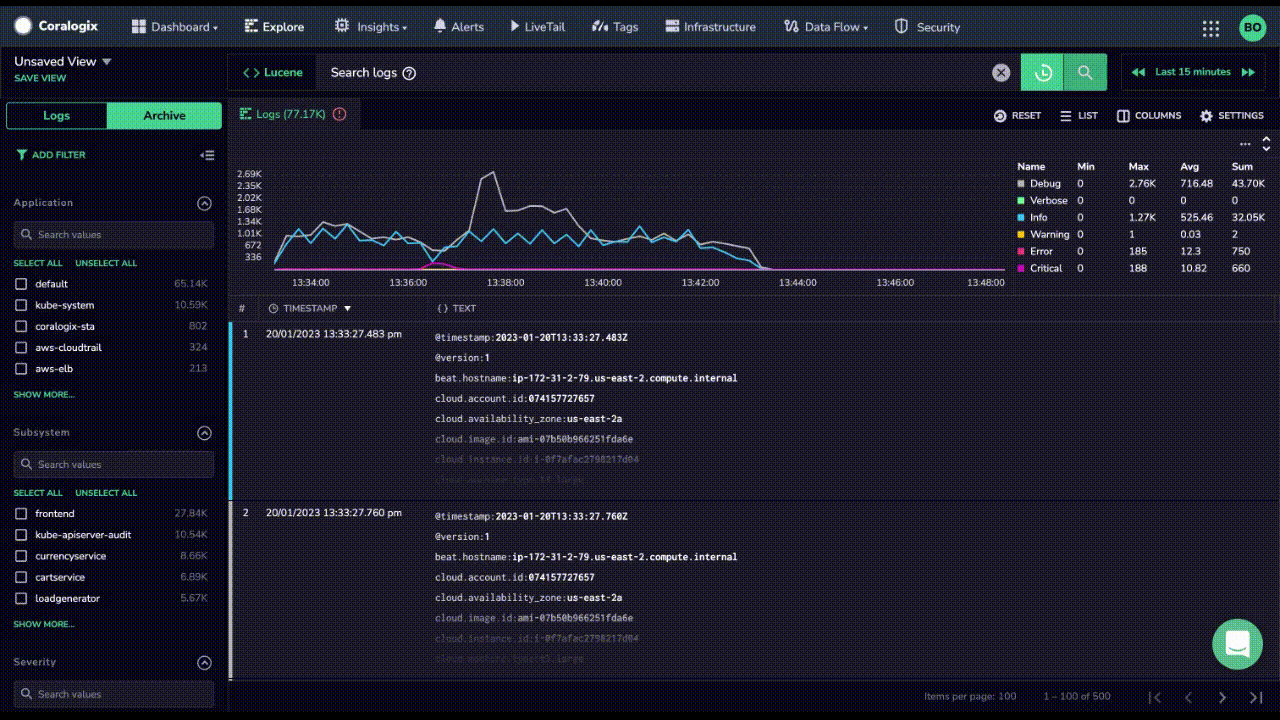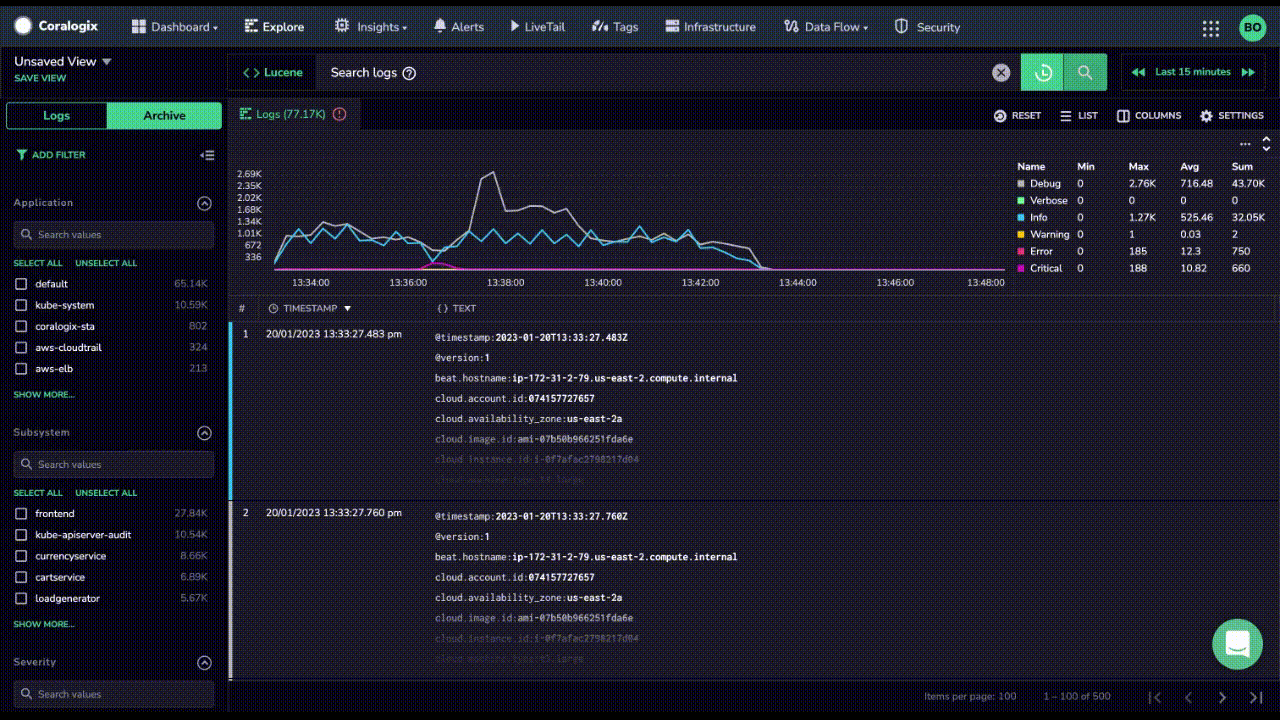
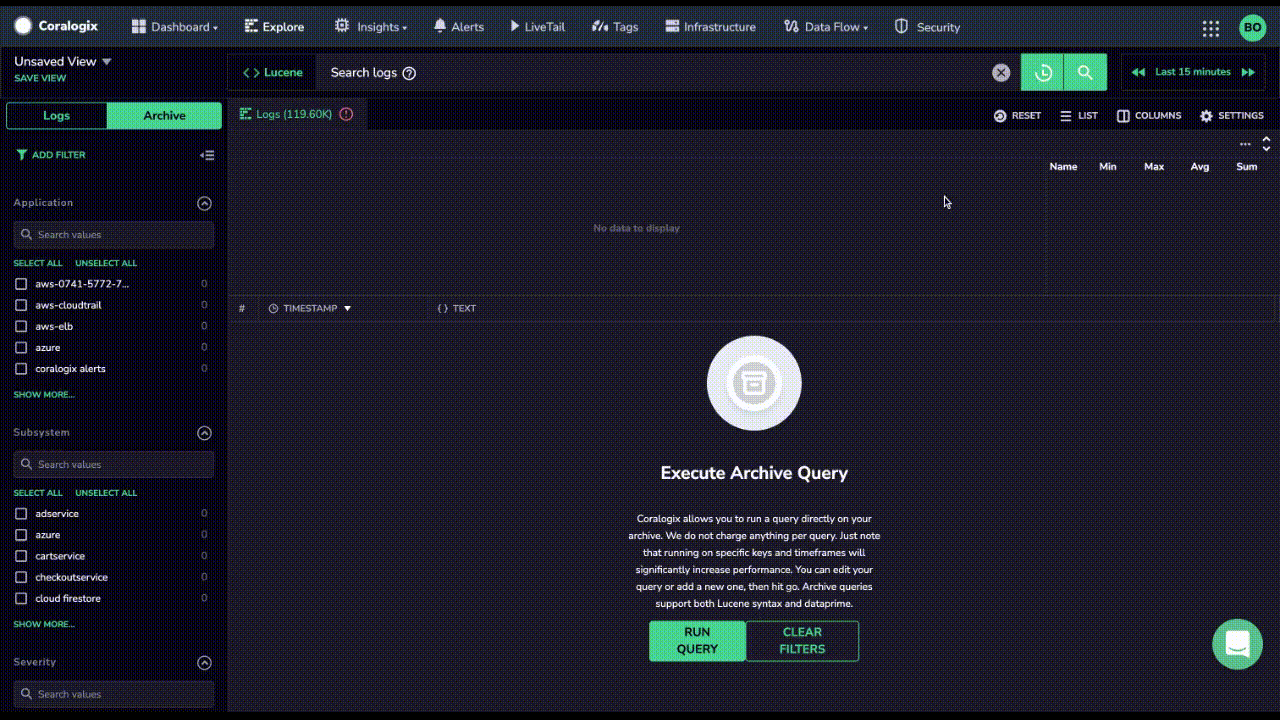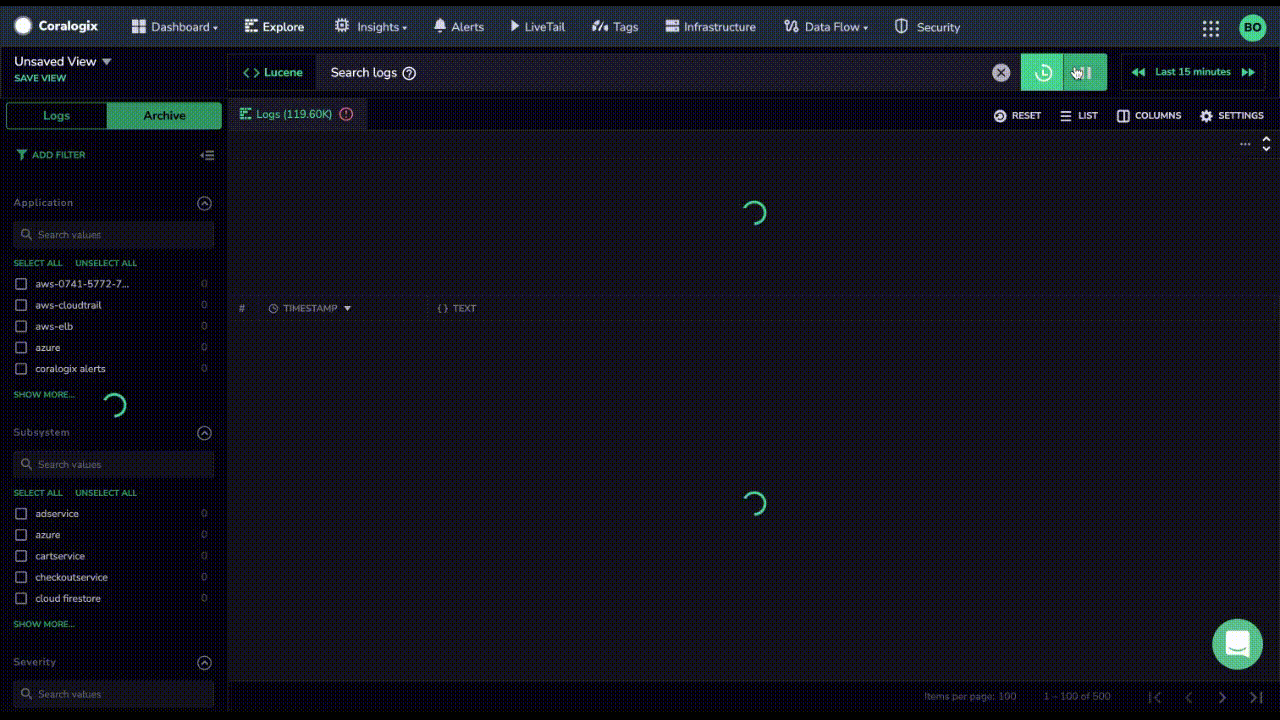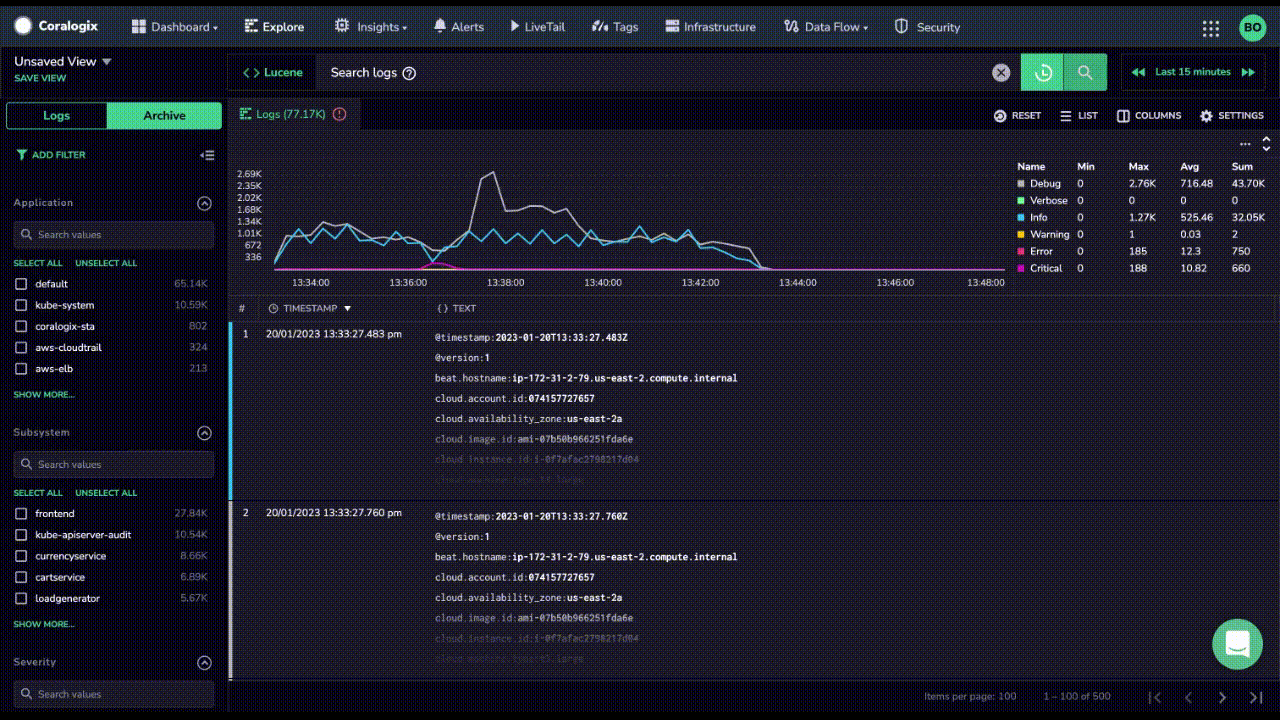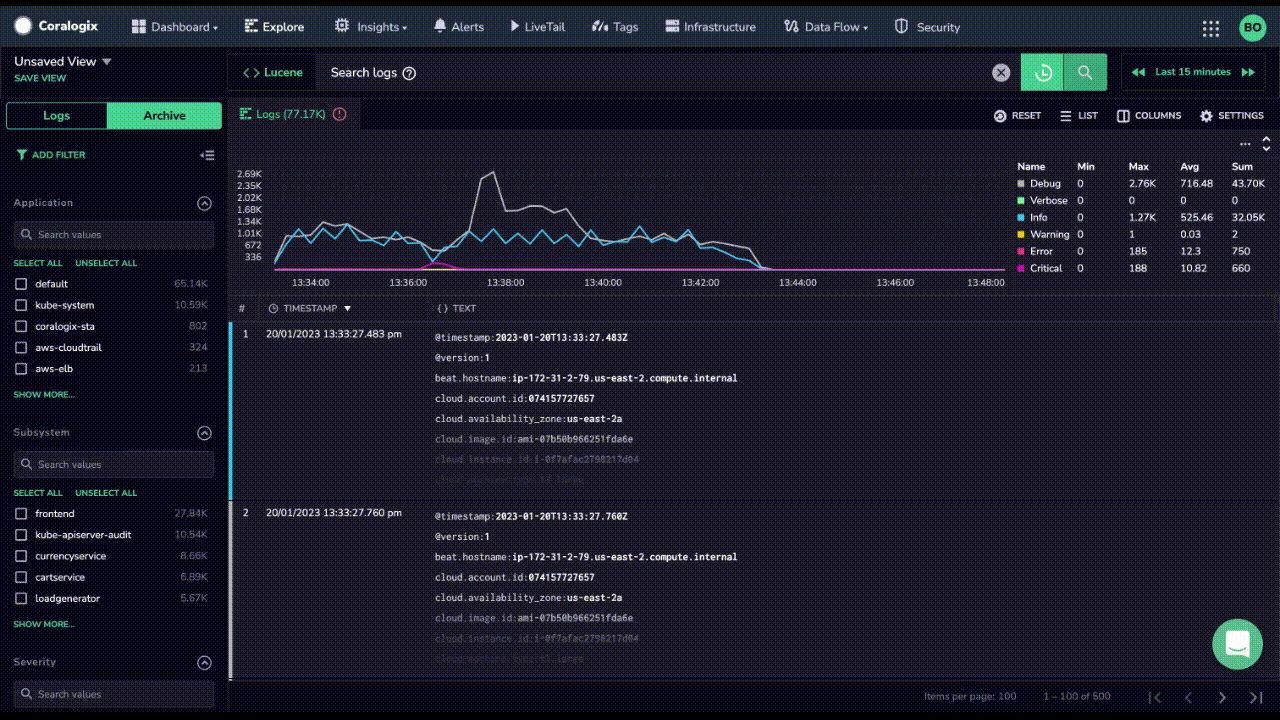
While Coralogix Remote Query is a solution to constant re-ingestion of logs, there are few other options today that also offer customers the ability to query unindexed log data. For instance, Datadog has recently introduced Flex Logs to enable their customers to store logs in a lower cost storage tier.
Let’s go over the differences between Coralogix Remote Query vs Flex Logs and see how Datadog pricing compares.
Get a strong full-stack observability platform to scale your organization now.
Overall cost – ingestion and retention
To get a true picture of costs, we need to calculate the unified cost per GB on both platforms. Unified cost is the joined cost of ingestion and retention. The calculation is based on the initial ingestion cost, with the monthly cost of retention, that’s spread out over a year and alongside any additional costs.
DataDog Unified Cost per GB = $0.10 ingestion + $0.60 retention + unknown compute costs = $0.70 per GB per year (+ unknown compute costs).
Coralogix Unified Cost per GB = $0.17 ingestion + $0.05 retention = $0.22 per GB per year
This demonstrates that Coralogix is 70% less than the cost of DataDog, even without considering the unknown compute costs.
A real world example
Let’s say a customer produces ten million logs per day, and retains them for one year. For simplicity, we can also make the following assumptions.
- Assume they’ve already got a year’s worth of data in their long term storage.
- The average log size is 1KB, meaning that one million logs is about 1GB of data.
- The data is never queried. We can assume this because DataDog has not published their compute pricing. It has no effect on Coralogix pricing, because Coralogix does not charge anything per query.
Coralogix Ingestion Cost: $0.17 per GB x 365 = $620
DataDog Ingestion Cost: $0.10 per GB x 365 = $365
Now, we must consider retention costs over the year. DataDog’s costs are recurring. Every month, customers are being charged for 3650GB of data, at $0.05 per GB.
DataDog Retention Cost: $0.05 per GB per Month x 12 = $2190
Coralogix, on the other hand, relies on cloud object storage, because of its scalable performance and extremely low cost. Let’s be generous, and assume there is no intelligent tiering activated in S3 at all. Instead, let’s factor in our standard 5x compression, meaning any retention costs should be divided by 5.
Coralogix Retention Cost: $0.02 per GB per Month x 12 = $876 / 5 = $175.20
So when we combine these figures, there is a clear winner in overall cost.
DataDog costs over the year: $2555 (+ Unknown Compute costs) ❌
Coralogix costs over the year (ignoring any cost optimization): $795.20 ✅ (70% Lower)
A 70% difference in cost is a big deal. Coralogix is clearly the most cost effective solution in any real world scenario, even before we consider cost optimization available in S3, such as intelligent tiering, which drives down retention costs even further. If the goal is to retain data, without losing access, then Coralogix is the obvious choice.
Vendor lock-in: Flex Logs vs Coralogix Remote Query
DataDog stores Flex Logs within their system. For customers, this means that their data is never truly held in their own hands. Instead, DataDog keeps their data on their behalf. The data is held in a proprietary format, making vendor lock-in an unavoidable and serious concern.
Coralogix customers, on the other hand, hold their data in object storage in their own cloud account. The format, CX-Data, is based on Parquet. It’s so open source, customers can even directly index and query their logs using Amazon Athena. Data is never held hostage by Coralogix.
Analysis
DataDog Flex Logs are only available for querying. Any other activities require them to be rehydrated back into expensive, index based storage. On the contrary, Coralogix enables customers to view their data in LiveTail, parse and format their logs and train anomaly detection models, all at no extra cost.
Summary: DataDog Flex Logs vs Coralogix Remote Query
Coralogix logs are less expensive to store and retain, they contain more features and they can be queried at no extra cost. Coralogix makes it much more predictable, scalable and usable solution, offering at least a 69% reduction in cost, when compared in a real world scenario to Flex Logs. In reality, after intelligent tiering is factored in, Coralogix is a fraction of the cost, with access to more features, standing out as the obvious choice for cost optimization and data problems in observability.