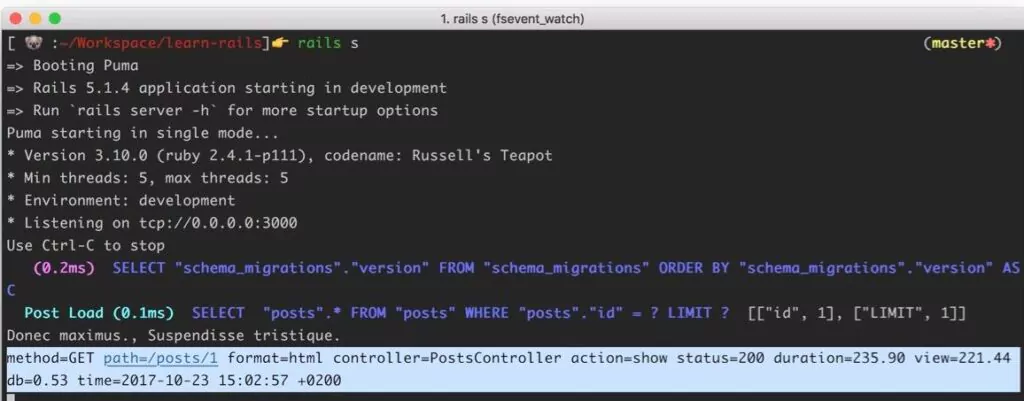
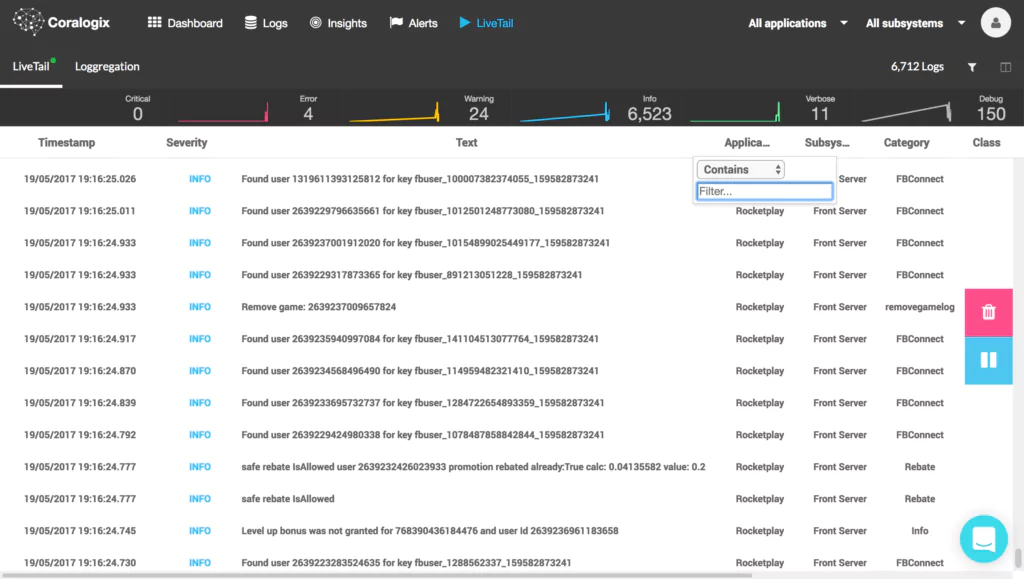
The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

“Teacher somewhere in India: The world you see is supported by a giant turtle.
Student: And what holds this giant turtle down?
Teacher: Another giant turtle, of course.
Student: And what is it that holds this one?
Teacher: Don’t worry – there are turtles all the way down!”
Throughout my years of experience, I frequently encountered solutions (or at least attempts to find a solution) for security issues that were rather complicated and cumbersome, that has led me to wonder if those who came up with them sincerely believe that their complexity and subtlety could improve the safety level in their organizations.
In this article, I will attempt to support the claim that states that ‘very often the opposite is correct’, while towards the end I will present two examples of situations where this rule is intentionally bent in order to improve the security of critical assets.
The Scenario
Suppose you have been entitled to protect the building you live in, how would you start the planning process for it? Evidently, you would try to analyze and point out the most critical assets for the enterprise like tenants, letters in the mailboxes, and the bicycles locked down in the lobby. You would attempt to predict the possible threats to these assets and their likelihood. Subsequently, you could effectively reduce the likelihood to an occurrence of one of these threats or minimize its expected risks through a variety of methods. The most common aspect between these methods is that the way in which each method will reduce risk or the chance of realizing one or the other threats, is known to the user.
Often times, in the world of data security or cyber, those in charge of protecting systems do not necessarily understand the thinking process in a potential attackers’ mind deeply enough. Frequently, the result is a network, that paradoxically, is built for managing and maintenance but is easy to break into.
A few examples of weak security:
DMZ – according to its’ common definition, is a network located between the public network (usually the Internet) and the corporate network. While controlled access to servers located in it through the internet and the corporate network will be enabled, access to the internet or corporate network from it will not be enabled.
However, in various organizations, there exist a number of DMZ networks and at times several corporate networks. However, as aptly put by Bruce Shneier in his excellent article ‘The feeling and reality of security’ we, as human beings often respond to a perception of security rather than to security itself. The result of such a reality could be a sharp increase in network complexity and thus also the complexity of its treatment and maintenance. In many ways, such an approach requires more attention to small details on the part of network administrators – and in the case of multiple network administrators, special attention to the coordination between them.
If we were to ask ourselves questions about the vulnerabilities and weaknesses of human beings – at the top of the list we would find the weakness of human beings of paying attention to a large quantity of details over time, maintaining concentration over time, and following complex processes…you can already see where this is going…
Another example: A technique that is frequently recommended for network administrators is to place two firewalls in the organization – both being produced by two different manufacturers in back-to-back configuration. This is done so that if any weakness is revealed in one manufacturer, the chances that the same weakness will occur in the other is rather low.
However, the maintenance of these firewalls would require a large amount of resources, and in addition, the same policy would need to be applied to both firewalls in order to take full advantage of them. As the equipment were produced by two different manufacturers, the updates of the equipment changes and becomes more complex over time.
Once again – if we ask ourselves for another commonly exploited weakness, one of the most prominent on the list would be – lack of consistency.
Parents of several children will notice that all principles of their education that they had acquired from childhood is implemented to near perfection with the first child. Suddenly, with the addition of a second child, that disciplined approach may loosen and by the third child, much more has given way – leaving the elder child amazed at how things have changed.
In our case, when we inquire about the network administrator, he explains that he mainly works in back-to-back configuration, but through a deeper examination, we may discover that he was using two different firewalls made by different manufacturers – each one being intended for a different task. For example, one may be responsible for the treatment of IPSEC VPN and services available online, while another for separating the network from several DMZ servers. In this way, filtering takes place by the first or the second firewall, but rarely by both.
Another great example, but with different content:
Many programmers prefer to develop components on their own rather than using open source components. In their opinion, we can never know if someone changed the code on the cloud to a malicious one. When we have control over our own code, it will naturally be perceived with less danger in comparison to code controlled by people whom we do not personally know. Although, as a matter of fact, a code present on the internet is more likely to be secure and organized, since it is open to the public and therefore has more chances of someone detecting flaws in it and offering corrections.
In continuation to the security risks mentioned above, proprietary code may also lead to the likelihood that it contains bugs – this is due to the fact that such a development also requires continuous maintenance, fixing, and a combination with existing components in the organization, especially when it comes to infrastructure development (queue jobs or pipeline components, for example). The “solutions” to such issues typically lead to cumbersome codes that are difficult to maintain and are full of bugs. In addition, in many cases, the programmer who wrote the code leaves the org or changes roles – leaving the organization with code written by an unknown source…which is exactly the point of proprietary code in the first place.
In many organizations, redundant communication equipment as well as parallel communication pathways are stationed in such a way as to reduce the risk for communication failure as a result of the downfall of a Backbone Switch for example.
It is worth noting that while this type of architecture will significantly minimize the risk for communication loss due to a downfall of communication equipment, and if it is set to an active configuration, will also likely reduce the risk of a downfall due to DoS attacks, it also simultaneously creates new risks: risks of attack or malfunction in looping mechanisms (Spanning Tree being one example).
This results in a number of channels that now need to be secured in order to prevent eavesdropping, and a higher chance that equipment failures will go undetected. Meanwhile packet-based monitoring equipment will be unable to collect the needed information easily and effectively.
It is important to understand – I am not stating that the use of communication equipment in order to reduce the risk of communications downfall or size-based attacks is a bad idea. On the contrary, I am only trying to take everything into consideration whilst making such decisions. I most definitely believe that today, communication equipment are rather reliable, therefore organizations need to understand that redundant communication equipment isn’t a magic solution without downside, and that it needs to be tested against the challenges and difficulties that it poses.
I had promised that at the end of this post, I would present an example that in fact demonstrates a situation where complexity is deliberately used in order to create a higher level of security. One example of such a situation, in my opinion, is obfuscation. It is important to keep in mind that compiling source codes into real machine language such as C or C ++ or GO languages, becomes something that is very difficult to reverse back into readable text, and in large projects it becomes nearly impossible. Therefore, many closed source software programs are written in these languages in order to make it difficult for potential thieves to obtain the source code. However, in many cases, due to a variety of technological reasons, many closed source software also need to contain some parts in non – compiled languages or partially compiled ones (such as #C and JAVA), therefore some source code may need to be protected even when compilation is not a possibility. The solution that was discovered was the obfuscation process which converts the code into hard-to-read code by, inter alia:
- Transferring the whole code into one single row containing all different classes and methods.
- Switching variable names, classes and functions of random texts.
- Add demo code that does nothing
- Dismantling functions into sub-functions
In conclusion, this post demonstrated how the fact that people are managing data security in organizations is what creates complexity often due to the biases inherent in the human brain. This complexity may contribute to the data security of the organization, but it also aggravates it at times. Nevertheless, I have also shown one example where in certain cases complexity itself is being used in order to improve data security.