Web application logging best practices
Logging monitoring is a key requirement of any production application. .NET Core offers support for outputting logs from your application. It delivers this capability through a middleware approach that makes use of the modular library design. Some of these libraries are already built and supported by Microsoft and can be installed via the NuGet package manager, but a third party or even custom extensions can also be used for your .NET logging.
This article aims to give an introduction into how logging works in .NET Core 3.1 and offer some best practices to consider when building out your logging approach.
Prerequisites
Before we can get started, there are a few things you will need to follow along. First, you will want the following installed on your local machine.
While this article assumes only a basic awareness of the C# language and .NET Core framework, it is worth spending some time reading up on some of the concepts that we will cover.
Let’s get started
This article will be going through some logging techniques that can be applied to a .NET Core 3.1 application. But before we can get started with .NET logging, we need an application we can change. I have prepared such an application, which is hosted on GitHub. So, let us go ahead and clone the repository so we can begin. Run the following command from the terminal to clone the repository to a local folder.
$ git clone https://github.com/sladesoftware/dotnet-core-3-1
$ cd dotnet-core-3-1
To test that this application works properly, run the following command in the terminal from the root project folder.
$ dotnet run
[Output]
info: Microsoft.Hosting.Lifetime[0]
Now listening on: https://localhost:5001
info: Microsoft.Hosting.Lifetime[0]
Now listening on: https://localhost:5000
info: Microsoft.Hosting.Lifetime[0]
Application started. Press Ctrl+C to shut down.
You can use the cURL tool at this point to test the different endpoints. There are some simple scripts under the scripts/ folder, which will help here. For more information on how to work with this application, refer to the README file.
Where do we log to?
We do not. Not currently, at least. The default configuration allows basic console logging, but we have not made use of the .NET logging pipeline at all. So, all exceptions that occur, HTTP requests and any internal actions; are not logged anywhere. In this simple case, that is not really a problem. But if this were a production application and something went wrong, we would find it difficult to diagnose the cause of the issue.
The logging pipeline
.NET Core 3.1 applications are built using a middleware approach. An application host is configured to use a collection of different middleware components. When the application is running, these components set up the services and configuration available. Logging is achieved out of the box with this same approach.
With other frameworks (including the earlier version of .NET) you would have to install a third-party logging library and configure that manually to be incorporated within your application. For .NET Core 3.1, Microsoft has developed their own logging libraries, which are installed by default in our application. As detailed in the Logging in .NET Core article listed in the Prerequisites section, you will notice that our application makes use of the CreateDefaultBuilder method in the Program.cs file, which configures the logging middleware part to use Console, Debug and EventSource logging providers.
Before we look at how we configure this further, we will look at how to make use of it. We will specifically be focusing on the output from the Console logging provider. Open the TodoController.cs file and inject a logger for the class to use.
using System.Collections.Generic;
using System.Linq;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Logging;
namespace DotnetApplication.Api.Controllers
{
[ApiController]
[Route("api/[controller]")]
public class TodoController : ControllerBase
{
private readonly ILogger logger;
private readonly TodoItemStore store;
public TodoController(ILogger<TodoController> logger, TodoItemStore store)
{
this.logger = logger;
this.store = store;
}
...
}
You can see here that we are able to inject a logger dependency into our class constructor. This is because the default configuration registers a logging provider factory with the built-in dependency injection system within .NET Core 3.1. You will notice that the parameter into the constructor is a generic type referencing the class itself. This is a requirement when using the .NET logging framework as it allows the factory to create a logger instance specific to that class. This approach adds a little extra context into log messages and allows class and namespace specific log level configuration (more on that later).
Now that we have a logger in our class, let us call it from one of our methods. Add the following code to the Get method.
[HttpGet("{fail:bool?}")]
public IActionResult Get(bool fail = false)
{
logger.LogInformation("Hello from the Get() method!");
if (fail) throw new System.Exception("Simulated failure");
return Ok(store.GetItems());
}
Restart the application and send a GET request to the /api/todo endpoint.
$ curl –kL localhost:5000/api/todo
If you look at the output of the application itself (not the response returned by cURL) you should see our information message logged to the console.
info: DotnetApplication.Api.Controllers.TodoController[0]
Hello from the Get() method!
Go ahead and add a few more calls to the logger. Be sure to try logging distinct levels of information, such as errors and warnings as well.
Coralogix and Logging Levels
Coralogix offers support for quota optimisation. With our Quota optimizer, you’ll be able to visualize your noisiest applications, broken down by your .NET logging level.
Logging in JSON
While logging to the console is great when you are developing the application and running it locally, it is not very helpful for production applications as the output is often transient and therefore lost as soon as it is output (unless you happen to be watching the output at the time). Under a production environment, it is often more useful to store the log messages somewhere else. A simple alternative to the console here is to write the log messages to a JSON file, stored somewhere on the hard drive.
Microsoft has not yet developed a .NET logging extension library to handle writing log entries to a JSON file. So, for this part, we will look to a third-party library to serve this purpose: Serilog. This is an open-source library that builds upon the logging middleware built into .NET Core 3.1 and provides the ability to write our entries to a JSON file with little other configuration.
To get started, let us add the Serilog package to our project.
$ dotnet add package Serilog.Extensions.Logging.File
This will install the required package to our project and pull down all dependencies to allow us to build the project with this added library. Now we need to configure our logging middleware part to write to a JSON file using this new provider. Add the following to the Program.cs class.
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureLogging((_, builder) =>
{
builder.AddFile("logs/app-{Date}.json", isJson: true);
})
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup<Startup>();
});
}
That’s it! If you run the application again and hit your endpoints, you should see a JSON file appear under the logs/ folder. That file will hold a lot of information about the HTTP requests, custom log messages, and more, all in JSON format.
Does Coralogix Process JSON?
Coralogix is at home with JSON logs. With structured input, you’ll be able to take advantage of the full range of Coralogix products – from live tail to machine learning.
How to manage codebases for .NET Logging
If you have started adding some extra calls to the logger in your methods, you will start to see how littered code can become with calls to a logger. To give some context to this, let us add some more calls to the logger to the Update method.
[HttpPatch("{id:int}/{fail:bool?}")]
public IActionResult Update([FromBody] TodoItem item, int id, bool fail = false)
{
logger.LogInformation($"Enter /api/todo/{id}/{fail}");
if (fail)
{
logger.LogError("Fail is set to true, so simulating failure");
throw new System.Exception("Simulated failure");
}
if (item == null)
{
logger.LogWarning("No JSON body, returning HTTP 400 - Bad Request");
return BadRequest();
}
if (!store.ReplaceItem(id, item))
{
logger.LogWarning($"No items exist with Id {id}, returning HTTP 404 - Not Found");
return NotFound();
}
logger.LogInformation($"Item {id} updated, returning HTTP 200 - OK");
return Ok("OK - Updated");
}
You can see from this example that the code is now definitely littered. It has the effect of obscuring what the method is doing, as there is a lot of “noise” in the form of calls to the logger. This is quite a common approach to logging. This section will offer some tips to help reduce this noise, while still getting value from your logs.
Changing the log level
The first part I wanted to mention is around configuring the application to change what is logged. This is not related to reducing noise in the code but will help when reducing noise in the logs that are output. Often, this simple approach will help with small production systems, but when you start scaling out to larger systems, you will want to investigate external log collection and analysis systems that can handle large volumes of logs, such as the Elastic Stack.
In our example above, we have output 3 distinct levels of log messages: Information, Warning and Error. If you look at the appsettings.json and appsettings.Development.json files, you will see some configuration around log levels.
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft": "Warning",
"Microsoft.Hosting.Lifetime": "Information"
}
},
"AllowedHosts": "*"
}
We will not go into too much detail here, but there are a few points worth mentioning. Firstly, you can define different log levels per namespace or class, or even just something to fall back on (the default). You can also include more files that correspond to the environment and then configure the log levels differently there. For example, in this application, we have an appsettings.Development.json file. This could set all log levels to Information so that we see everything that is logged during development. We could then define more restrictive log levels (I.e. just warning and errors) in the main appsettings.json file (or you can include an appsettings.Production.json file for Production-specific configuration). Using this approach, we would have verbose logging when we are running the application locally during development, but more restrictive logging when the application is running in production. You can read more about this here.
Logging exceptions through the middleware
Let us try to reduce some of the noise now in our method. We are going to log exception information using a middleware approach. By default, the pipeline we are using already has some middleware set up to include this, as well as more to log the HTTP requests and responses in terms of endpoints and status codes. But we will add something custom to gain an understanding as to how it will work.
To add middleware, we have two options. We can either create a new class and register that class with the pipeline, or we can simply add a lambda expression. We will take this former approach here as we want to be able to inject a logger instance into our middleware component. With that in mind, create a new file at the project root called UnhandledExceptionMiddleware.cs and enter the following code.
using Microsoft.AspNetCore.Http;
using Microsoft.Extensions.Logging;
using System;
using System.Threading.Tasks;
namespace DotnetApplication.Api
{
public class UnhandledExceptionMiddleware
{
private readonly ILogger logger;
private readonly RequestDelegate next;
public UnhandledExceptionMiddleware(ILogger<UnhandledExceptionMiddleware> logger, RequestDelegate next)
{
this.logger = logger;
this.next = next;
}
public async Task Invoke(HttpContext context)
{
try
{
await next(context);
}
catch (Exception exception)
{
logger.LogError(exception,
$"Request {context.Request?.Method}: {context.Request?.Path.Value} failed");
}
}
}
}
This is a quite simple component – it invokes the next step in the pipeline but wraps it in a try-catch. If an exception is thrown further down the chain, this component will catch it and then output an error log message with the content of the exception and a brief message detailing the request that failed.
We now need to hook this up, so add the following one line to our Startup.cs class.
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseMiddleware<UnhandledExceptionMiddleware>();
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}
Note: This needs to be added after the app.UseDeveloperExceptionPage() call, as that adds another piece of middleware that will swallow the exception.
Now that we have set up our custom middleware component, run the application again. If you trigger one of the exception endpoints (by specifying true for the fail route parameter) then you should see our new log message appear in the console (and JSON log file).
...
fail: DotnetApplication.Api.UnhandledExceptionMiddleware[0]
Request GET: /api/todo/true failed
System.Exception: Simulated failure
at DotnetApplication.Api.Controllers.TodoController.Get(Boolean fail) in ...
...
Logging requests and responses
Let us now create another middleware component. This time, we want to log the full body of our HTTP requests and responses. This is partly already covered by the built-in middleware class Microsoft.AspNetCore.Routing.EndpointMiddleware. Looking at a sample of this from the Serilog output in our JSON file, we can see there are several entries around an HTTP request being handled.
{
"@t": "2020-08-05T11:26:14.1913840Z",
"@m": "Executed endpoint '"DotnetApplication.Api.Controllers.TodoController.Create (DotnetApplication.Api)"'",
"@i": "99874f2b",
"EndpointName": "DotnetApplication.Api.Controllers.TodoController.Create (DotnetApplication.Api)",
"EventId": {
"Id": 1,
"Name": "ExecutedEndpoint"
},
"SourceContext": "Microsoft.AspNetCore.Routing.EndpointMiddleware",
"RequestId": "0HM1P5NB98QKE:00000001",
"RequestPath": "/api/todo",
"SpanId": "|409deee3-42069a9a6ad1857f.",
"TraceId": "409deee3-42069a9a6ad1857f",
"ParentId": ""
}
This is an example of the information logged when the endpoint to create a new To-Do item is hit. You will be able to see from each log entry that it is only metadata that is logged. While this may be useful, there may be scenarios where we want to log the actual body of the request. So, let us create a middleware component to do this.
Create a new file called HttpRequestBodyMiddleware.cs at the root of the project and enter the following code.
using Microsoft.AspNetCore.Http;
using Microsoft.Extensions.Logging;
using System.IO;
using System.Text;
using System.Threading.Tasks;
namespace DotnetApplication.Api
{
public class HttpRequestBodyMiddleware
{
private readonly ILogger logger;
private readonly RequestDelegate next;
public HttpRequestBodyMiddleware(ILogger<HttpRequestBodyMiddleware> logger,
RequestDelegate next)
{
this.logger = logger;
this.next = next;
}
public async Task Invoke(HttpContext context)
{
context.Request.EnableBuffering();
var reader = new StreamReader(context.Request.Body);
string body = await reader.ReadToEndAsync();
logger.LogInformation(
$"Request {context.Request?.Method}: {context.Request?.Path.Value}n{body}");
context.Request.Body.Position = 0L;
await next(context);
}
}
}
Register the middleware component as you did before: in the Startup.cs class. It does not matter where in the chain it is registered, but I have added it at the start of the chain here.
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
app.UseMiddleware<HttpRequestBodyMiddleware>();
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseMiddleware<UnhandledExceptionMiddleware>();
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}
Restart the application and hit the Create endpoint and check that the request body has been logged to the console and the Serilog JSON file.
info: DotnetApplication.Api.HttpRequestBodyMiddleware[0]
Request PUT: /api/todo
{ "name": "TODO1", "description": "Something 1" }
Now that we are logging HTTP requests and exceptions, we can remove some of the log messages from the controller actions. You may find that you still require some, but that will normally be for specific purposes and should be used sparingly and only where the information cannot be logged elsewhere.
More advanced concepts
Beyond what we have already discussed, there are other, more advanced techniques that could be used to further reduce noise in your code. Both techniques that I am going to mention are large enough to call for full articles themselves, so I am only going to give a high-level overview of what they are and how they can help to reduce noise.
Going further with Coralogix
Coralogix offers some of the most sophisticated log analytics on the market. We use machine-learning powered techniques to identify previously unknown anomalies in logging data. This allows you to zoom in on your problems efficiently, and get back to your product, knowing that your .NET logging is in safe hands.
Aspect-Oriented Programming
One more advanced concept that is worth mentioning is that of Aspect-Oriented Programming or AOP. This is a concept that aims to apply more behavior to units of software without changing the code itself. It achieves this sometimes by wrapping calls to code in proxy implementations, or other times by adding attributes to methods and classes for use in intercepting calls to them. This is a perfect candidate for abstracting non-business logic code, such as logging, from your methods; allowing the code to hold just the business logic whilst not losing the benefits of logging.
To give a brief example of using an AOP in C#, here is a method with a logging attribute applied that captures the call to the method.
[LogMethod]
public int Add(int x, int y)
{
int result = x + y;
return result;
}
In this case, the LogMethod attribute could capture any or all the following details:
- When the method was called and by what code
- When the method returned
- The value of any parameters passed to the method
- Any value returned by the method
- How long it took for the method to complete
This supplies valuable information without adding more noise to the code. One such example library that delivers this approach is the AspectCore library. You can read more about using it for creating a logging attribute here.
Sidecar process
A Sidecar is a different kind of pattern that is more attributed to architectural or infrastructure designs. The concept of a Sidecar is to have a separate process running alongside your application. In the case of a service that offers some form of request/response model, such as an HTTP web service, the Sidecar can act as a proxy for those requests. By this, I mean that any requests sent to the service would be sent to the Sidecar proxy. This would in turn forward the requests onto the actual service and redirect the response back to the caller.
The benefit of using this pattern is that it would allow you to add custom logging code inside the proxy; therefore, allowing you to capture valuable information about the requests and responses, without adding more code to the business logic. This is especially helpful in a system where the service already exists and potentially cannot be modified.
High-performance logging
Up until now, we have used the logging framework provided by .NET Core 3.1. You may have noticed that all the calls to the logger have been synchronous. This is by design by Microsoft – they deliberately do not support asynchronous logging as they recommend logging to be quick. However, just because asynchronous logging is not supported, this does not mean there are not any performance gains that can be achieved. The following tips hope to give some information about potential tweaks that can be applied to support a high volume of logs being output.
Log Level
It is not always necessary to log every Debug and Information log message in every environment. As such, consider lowering the log level in more performance-critical environments, such as Production. Reducing the log level as far as Warning or Error will help to reduce the number of messages that are output to the log locations configured for the application.
Debug and Console Logging
Again, it is not always necessary to use all log providers configured for use by the application under all environments. Specifically, the Debug and Console log providers may not be needed in environments beyond local development. Removing these log providers (that are automatically included in all environments by the default ASP.NET Core configuration) may help to reduce the number of messages being output and therefore help to boost performance.
A performance degradation was investigated and written about by Rick Strahl, though this was specifically running on a Windows platform using ASP.NET Core 2.2. Be careful though, as you do not want to remove a log provider that you do need. For example, under containerized environments, the console output is often collected by the host for use elsewhere (I.e. Docker, AWS CloudWatch, etc).
High Performance .NET Logging
It is understood that logging to external sources such as a database, a web service, or even a file, can increase the overhead of writing out messages due to network latency and I/O bottlenecks. Since logging should be a quick process, it is recommended to try to avoid logging to these sources where possible.
However, there are some acceptable approaches to using these sources where they are needed.
Use an In-Memory Buffer/Queue
When you do need to write log messages to slower sources, consider using a fast-access intermediary to cache the messages before a background process handles the actual load of writing these messages to the required sources. This could be as simple as writing the log messages to a
However, this approach comes with its own potential issues. Where you may benefit from better performance under high load, you face the possibility of losing some of your log messages if the application were to crash or be stopped/restarted. Any messages still stored in memory at the time the application stops will be lost.
There are other providers that handle this type of background logging. We have already looked at Serilog for our JSON file log provider. Serilog also supplies an asynchronous sink, which extends its usage to make use of a background process to write logs asynchronously. This package does handle the instance where the application is stopped, but cannot guarantee that 100% of the messages will be logged in the case that the application crashes.
Sidecar Process
Another potential way to handle writing to less performant sources would be a Sidecar process. In this scenario, the application could write log messages to a file, and a sidecar process would then be tailing this file and writing all new messages to the desired location. This adds some added complexity with having a separate process running alongside your application, but maybe a sufficient approach under certain systems.
As we can see, there are several approaches or techniques that could be applied to improve the performance of your application while writing logs. There is no one-size-fits-all solution here as it will depend on your exact setup and requirements.
LoggerMessage
If your application has a lot of log messages being written and becomes under high load, then you may experience performance issues still, even after applying the above techniques. One other area to consider is the LoggerMessage pattern recommended in the Microsoft documentation for these scenarios.
You can read more about this concept and explore some examples here. At a high level, the default logging approach that we have looked at boxes values and evaluates log message format strings on every output. These approaches, when under high load, can seriously impact performance. The LoggerMessage pattern aims to solve these issues by configuring a strongly-typed, static message that can be used instead of the default logging approach.
Coralogix and Performance
Coralogix is designed to process huge volumes of logs. Performance is a concern that can distract you from the real goal – your product. Allow us to make logging an easy, scalable part of your infrastructure.
Valuable logs
The whole purpose of creating logs from our applications is to supply value when we need to analyze problems. We have already seen how we can add value just by logging messages that describe what the code is doing or capturing exceptions or HTTP requests and responses through the middleware. But what if we want to log some information specific to our business logic, but include the context of the HTTP request that triggered the call to that business logic.
One approach would be to pass down the current HttpContext instance from the controller action that has been called, right through to the business logic in question. However, this would mean coupling the business logic to the concept of the HTTP Context, when that logic could live in a separate library that might be consumed by other non-HTTP-related code. When used by code in the other areas, there may be something else that triggers that call that we should log instead.
We can achieve this in .NET Core 3.1 by extending the logging framework to supply our own provider that we will inject into our business logic (or any other) code as part of the HTTP request. This custom log provider will have a dependency on the IHttpContextAccessor provided by the framework, which will allow us to access the current HttpContext to extract the information we want for our log message.
Let us look at how we would set this up. First, we need to find some code that is outside of our controller methods – the TodoItemStore is a perfect example! Make use of the logger in this method so that we have it setup. Add the following code.
private readonly List<TodoItem> todoList = new List<TodoItem>();
private readonly ILogger logger;
public TodoItemStore(ILogger<TodoItemStore> logger)
{
this.logger = logger;
}
// …
public void AddItem(TodoItem item)
{
item.Id = GetNextId();
logger.LogInformation($"Item {item.Id}: {item.Name} added to store");
todoList.Add(item);
}
// …
When our application is run and we add a new item, we will now see the following log message.
...
info: DotnetApplication.Api.TodoItemStore[0]
Item 1: TODO1 added to store
...
Now we need to create our own logger and provider. Create two files in the root of the project directory called MyLogger.cs and MyLoggerProvider.cs, and enter the following code.
MyLogger.cs
using System;
using Microsoft.Extensions.Logging;
namespace DotnetApplication
{
public class MyLogger : ILogger
{
public IDisposable BeginScope<TState>(TState state) => null;
public bool IsEnabled(LogLevel logLevel) => true;
public void Log<TState>(LogLevel logLevel, EventId eventId, TState state, Exception exception, Func<TState, Exception, string> formatter)
{
Console.ForegroundColor = ConsoleColor.Green;
Console.Write($"{logLevel}: ");
Console.ResetColor();
Console.Write(formatter(state, exception));
Console.WriteLine();
}
}
}
MyLoggerProvider.cs
using System.Collections.Generic;
using Microsoft.Extensions.Logging;
namespace DotnetApplication
{
public class MyLoggerProvider : ILoggerProvider
{
private readonly List<ILogger> loggers = new List<ILogger>();
public ILogger CreateLogger(string categoryName)
{
var logger = new MyLogger();
loggers.Add(logger);
return logger;
}
public void Dispose() => loggers.Clear();
}
}
Now we have our custom logger and provider setup, we can change the logging configuration for our application to include this new provider. Change the Program.cs file to remove all existing providers and use only our custom provider. Removing the other providers will just make it easier to see our changes.
...
.ConfigureLogging((_, builder) =>
{
builder.ClearProviders();
builder.AddProvider(new MyLoggerProvider());
})
...
Now run the application again, add a new to-do item and check the output in the console. You should see something like this:
Information: Now listening on: https://localhost:5001
Information: Now listening on: https://localhost:5000
Information: Application started. Press Ctrl+C to shut down.
Information: Hosting environment: Development
...
Information: Item 1: TODO1 added to store
Great! We are now using a custom logger. But we are still missing something – information relating to the HTTP request that triggered this call. Let us update our logger to include an injected service: the IHttpContextAccessor.
using System;
using Microsoft.AspNetCore.Http;
using Microsoft.Extensions.Logging;
namespace DotnetApplication
{
public class MyLogger : ILogger
{
private readonly IHttpContextAccessor httpContextAccessor;
public MyLogger(IHttpContextAccessor httpContextAccessor)
{
this.httpContextAccessor = httpContextAccessor;
}
// ...
}
}
Before we start changing our log output, we need to make sure this service can be injected. Update the provider to pass this dependency to our logger.
using System;
using System.Collections.Generic;
using Microsoft.AspNetCore.Http;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
namespace DotnetApplication
{
public class MyLoggerProvider : ILoggerProvider
{
private readonly IServiceProvider serviceProvider;
private readonly List<ILogger> loggers = new List<ILogger>();
public MyLoggerProvider(IServiceProvider serviceProvider)
{
this.serviceProvider = serviceProvider;
}
public ILogger CreateLogger(string categoryName)
{
var accessor = serviceProvider.GetService<IHttpContextAccessor>();
var logger = new MyLogger(accessor);
loggers.Add(logger);
return logger;
}
public void Dispose() => loggers.Clear();
}
}
We also need to make sure the accessor is available for injection, so update the Startup.cs file with the following change.
public void ConfigureServices(IServiceCollection services)
{
services.AddHttpContextAccessor();
services.AddSingleton<TodoItemStore>();
services.AddControllers();
}
Since we are now trying to access the services configured for injection within the application, we need to move our logger provider configuration to the Startup.cs file so that it can access the HTTP context accessor instance. So, move the following line from the Program.cs file and into the Startup.cs file.
Program.cs
builder.AddProvider(new MyLoggerProvider());
Startup.cs
public void Configure(IApplicationBuilder app, IWebHostEnvironment env, ILoggerFactory loggerFactory)
{
loggerFactory.AddProvider(new MyLoggerProvider(app.ApplicationServices));
...
}
Note that we have also added a third parameter to our Configure method. This is automatically picked up by the framework.
You may also want to remove the custom middleware components that we added so that the console output only has the messages we are interested in now.
Finally, we can now replace our log method with a message that holds a little more value.
public void Log<TState>(LogLevel logLevel, EventId eventId, TState state, Exception exception, Func<TState, Exception, string> formatter)
{
string message = formatter(state, exception);
var context = httpContextAccessor.HttpContext;
if (context == null)
{
Console.WriteLine($"{logLevel}: {message}");
}
else
{
Console.WriteLine(new
{
Message = message,
LogLevel = logLevel,
HttpMethod = context.Request?.Method,
HttpPath = context.Request?.Path
});
}
}
And that is it! Run the application and you should see something like this:
Information: Now listening on: https://localhost:5001
Information: Now listening on: https://localhost:5000
Information: Application started. Press Ctrl+C to shut down.
Information: Hosting environment: Development
...
{ Message = Item 1: TODO1 added to store, LogLevel = Information, HttpMethod = PUT, HttpPath = /api/todo/ }
This is just one example of the added value that you could add to your log messages to give them the context of what is happening in your application at the time. Instead of logging to the console, you could just as easily output this information to a JSON file to form structured log messages that could then be sent off to a log analysis tool such as the Elastic Stack.
Conclusion
In this article, we have seen that .NET Core 3.1 has been built in such a way to give us a lot of easily configured logging approaches out of the box. It is structured in a modular and extensible way to allow us to add in just the components we need, while also being able to take full advantage over the logging mechanism without being restricted to the log providers inside the new framework. We have also looked at a few concepts that will allow us to keep our logging valuable and performant, without polluting the business logic with too much “noise”.
 The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 



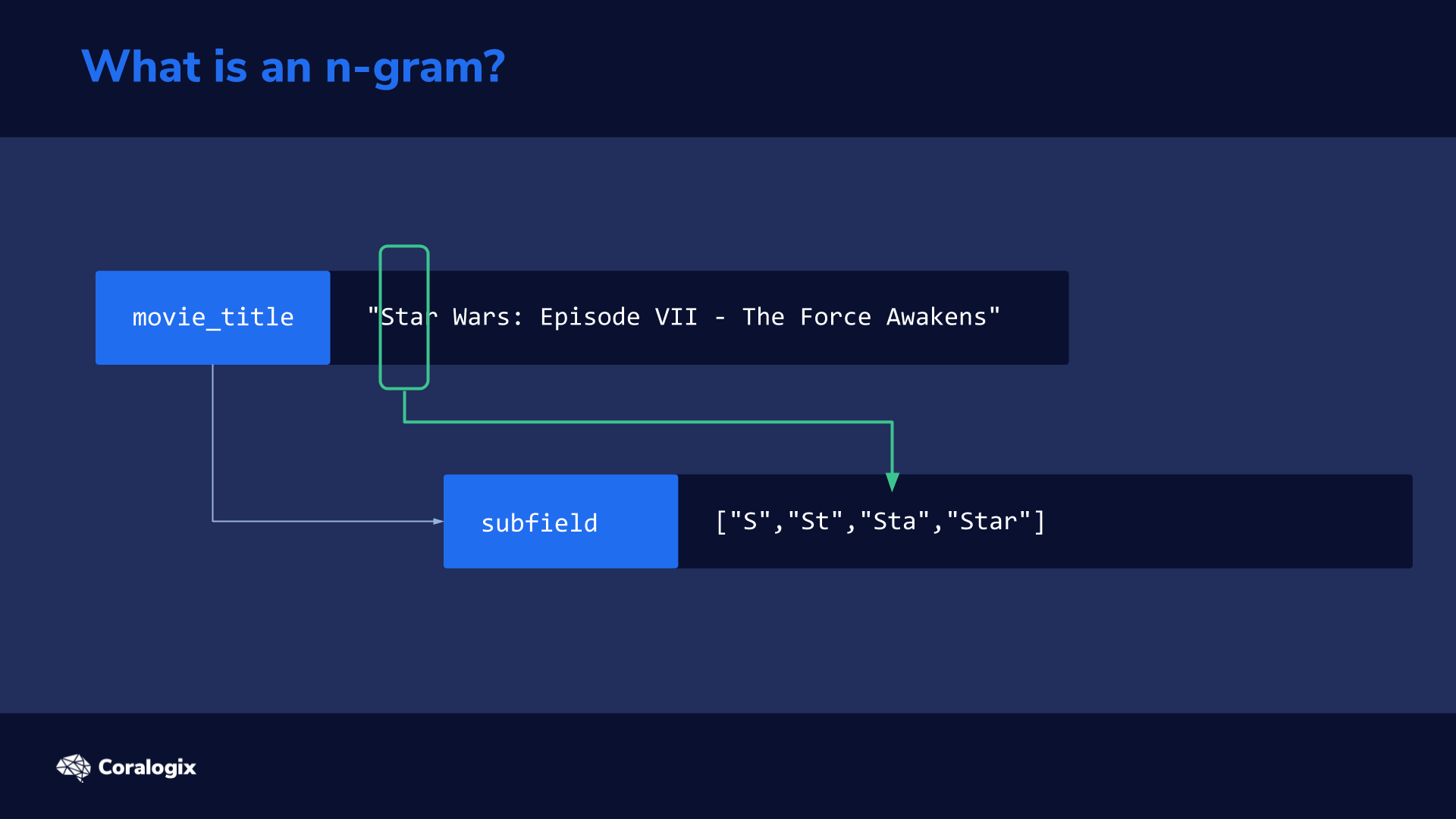















 When you change your primary index data there aren’t many ways to reconstruct it. Now, you may be thinking, “why change the primary data at all?”
When you change your primary index data there aren’t many ways to reconstruct it. Now, you may be thinking, “why change the primary data at all?”