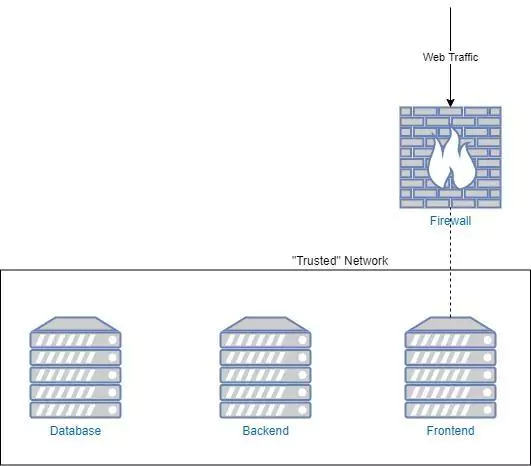
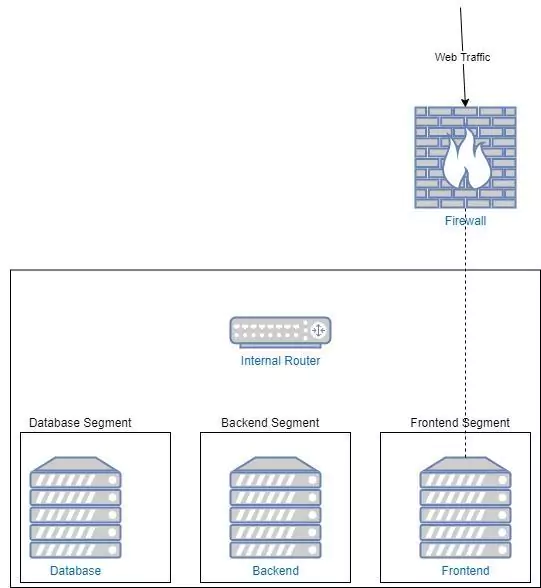
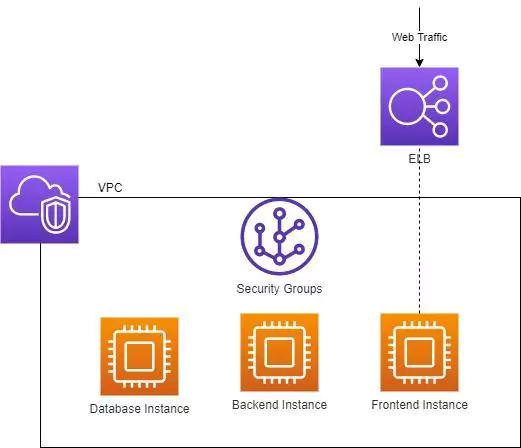
Avon and Family Tree aren’t companies you would normally associate with cybersecurity, but this year, all three were on the wrong side of it when they suffered massive data breaches. At Avon 19 million records were leaked, and Family Tree had 25GB of data compromised. What do they have in common? All of them were using Elasticsearch databases.
These are just the latest in a string of high profile breaches that have made Elasticsearch notorious in cybersecurity. Bob Diachenko is a cybersecurity researcher. Since 2015, he’s been investigating vulnerabilities in NoSQL databases.
He’s uncovered several high profile cybersec lapses including 250 million exposed Microsoft records. Diachenko’s research suggests that 60% of NoSQL data breaches are with Elasticsearch databases. In this article, I’ll go through five common causes for data breaches and show how the latest Elastic Stack releases can actually help you avoid them.
1. Always Secure Your Default Configuration Before Deploying
According to Bob Diachenko, many data breaches are caused by developers forgetting to add security to the default config settings before the database goes into production. To make things easier for beginner devs, Elasticsearch traditionally doesn’t include security features like authentication in its default configuration. This means that when you set up a database for development, it’s accessible to anyone who knows the IP address.
Avoid Sitting Ducks
The trouble starts as soon as a developer pushes an Elasticsearch database to the internet. Without proper security implementation, the database is a sitting duck for cyberattacks and data leaks. Cybersecurity professionals can use search engines like Shodan to scan for open IP ports indicating the presence of unsecured Elasticsearch databases. As can hackers. Once a hacker finds such a database, they can freely access and modify all the data it contains.
Developers who set up Elasticsearch databases are responsible for implementing a secure configuration before the database goes into production. Elasticsearch’s official website has plenty of documentation for how to secure your configuration and developers need to read it thoroughly.
Elasticsearch to the Rescue
That being said, let’s not put all the blame on lazy programmers! Elasticsearch acknowledges that the fast-changing cybersecurity landscape means devs need to take their documentation with a pinch of salt. Users are warned not to read old blogs as their advice is now considered dangerous. In addition, Elasticsearch security can be difficult to implement. Developers under pressure to cut times to market won’t necessarily be incentivised to spend an extra few days double checking security.
To combat the threat of unsecured databases, Elasticsearch have taken steps to encourage secure implementation as a first choice. Elastic Stack 6.8 and 7.1 releases come with features such as TLS encryption and Authentication baked into the free tier. This should hopefully encourage “community” users to start focussing on security without worrying about bills.
2. Always Authenticate
In 2018, security expert Sebastien Kaul found an Elasticsearch database containing tens of millions of text messages, along with password information. In 2019, Bob Diachenko found an Elasticsearch database with over 24 million sensitive financial documents. Shockingly, neither database was password protected.
So why are so many devs spinning up unauthenticated Elasticsearch databases? On the internet! In the past, the default configuration didn’t include authentication. Devs used the default configuration because it was convenient and free.
To rub salt on the wound, Elasticsearch told users to implement authentication by placing a Nginx server between the client and the cluster. This approach had the downside that many programmers found setting up the correct configuration much too difficult for them.
Recognising the previous difficulties, Elasticsearch has recently upgraded the free configuration. It now includes native and file authentication. The authentication takes the form of role based access control.
Elasticsearch developers can use Kibana to create users with custom roles demarcating their access rights. This tutorial illustrates how role based access control can be used to create users with different access rights.
3. Don’t Store Data as Plain Text
In his research, Bob Dianchenko found that Microsoft had left 250 million tech support logs exposed to the internet. He discovered personal information such as emails had been stored in plain text.
In 2018, Sebastien Kaul found an exposed database containing millions of text messages containing plain text passwords.
Both of these are comparatively benign compared to Dianchenko’s most recent find, a leaked database containing 1 billion plain text passwords. With no authentication protecting it, this data was ripe for hackers to plunder. Access to passwords would allow them to commit all kinds of fraud, including identity theft.
Even though storing passwords in plain text is seriously bad practice, many companies have been caught doing it red handed. This article explains the reasons why.
Cybersecurity is No Laughing Matter
In a shocking 2018 twitter exchange, a well-known mobile company admitted to storing customer passwords in plain text. They justified this by claiming that their customer service reps needed to see the first few letters of a password for confirmation purposes.
When challenged on the security risks of this practice, the company rep gave a response shocking for its flippancy.
“What if this doesn’t happen because our security is amazingly good?”
Yes, in a fit of poetic justice, this company later experienced a major data breach. Thankfully, such a cavalier attitude to cybersecurity risks is on the wane. Companies are becoming more security conscious and making an honest attempt to implement security best practice early in the development process.
Legacy Practices
A well-known internet search engine stored some of it’s account passwords in plain text. When found out, they claimed the practice was a remnant from their early days. Their domain admins had the ability to recover passwords and for this to work, needed to see them in plain text.
Although company culture can be slow to change, many companies are undertaking the task of bringing their cybersecurity practices into the 21st century.
Logging Sensitive Data
Some companies have found themselves guilty of storing plain text passwords by accident. A well-known social media platform hit this problem when it admitted it had been storing plain text passwords. The platform’s investigation concluded:
“…we discovered additional logs of [the platform’s] passwords being stored in a readable format.”
They had inadvertently let their logging system record and store usernames and passwords as users were typing the information. Logs are stored in plain text, and typically accessible to anyone in the development team authorised to access them. Plain text user information in logs invited malicious actors to cause havoc.
On this point, make sure to use a logging system with strong security features. Solutions such as Coralogix are designed to conform to the most up to date security standards, guaranteeing the least risk to your company.
Hashing and Salting Passwords
In daily life we’re warned to take dodgy claims “with a pinch of salt” and told to avoid “making a hash of” something. Passwords on the other hand, need to be taken with more than a pinch of salt and made as much of a hash of as humanly possible.
Salting is the process of adding extra letters and numbers to your password to make it harder to decode. For example, imagine you have the password “Password”. You might add salt to this password to make it “Password123” (these are both terrible passwords by the way!)
Once your password has been salted, it then needs to be hashed. Hashing transforms your password to gibberish. A company can check the correctness of a submitted password by salting the password guess, hashing it, and checking the result against the stored hash. However, cybercriminals accessing a hashed password cannot recover the original password from the hash.
4. Don’t Expose Your Elasticsearch Database to the Internet
Bob Diachenko has made it his mission to find unsecured Elasticsearch databases, hopefully before hackers do! He uses specialised search engines to look for the IP addresses of exposed databases. Once found, these databases can be easily accessed through a common browser.
Diachenko has used this method to uncover several high profile databases containing everything from financial information to tech support logs. In many instances, this data wasn’t password protected, allowing Diachenko to easily read any data contained within. Diachenko’s success dramatically illustrates the dangers of exposing unsecured databases to the internet.
Because once data is on the web, anyone in the world can read it. Cybersecurity researchers like Bob Diachenko and Sebastien Kaul are the good guys. But the same tools used by white-hat researchers can just as easily be used by black-hat hackers.
If the bad guys find an exposed database before the good guys do, a security vulnerability becomes a security disaster. This is starkly illustrated by the shocking recent tale of a hacker who wiped and defaced over 15000 Elasticsearch servers, blaming a legit cybersecurity firm in the process.
The Elasticsearch documentation specifically warns users not to expose databases directly to the internet. So why would anyone be stupid enough to leave a trove of unsecured data open to the internet?
In the past, Elasticsearch’s tiering system has given programmers the perverse incentive to bake security into their database as late as possible in the development process. With Elastic Stack 6.8 and 7.1, Elasticsearch have included security features in the free tier. Now developers can’t use the price tag as an excuse for not implementing security before publishing, because there isn’t one.
5. Stop Scripting Shenanigans
On April 3 2020, ZDNet reported that an unknown hacker had been attempting to wipe and deface over 15,000 Elasticsearch servers. They did this using an automated script.
Elasticsearch’s official scripting security guide explains that all scripts are allowed to run by default. If a developer left this configuration setting unchanged when pushing a database to the internet, they would be inviting disaster.
Two configuration options control script execution, script types and script contexts. You can prevent unwanted script types from executing with the command script.allowed_types: inline.
To prevent risky plugin scripts from running, Elasticsearch recommends modifying the script contexts option using script.allowed_contexts: search, update. If this isn’t enough you can prevent any scripts from running you can set script.allowed_contexts to “none”.
Elasticsearch takes scripting security issues seriously and they have recently taken their own steps to mitigate the problem by introducing their own scripting language, Painless.
Previously, Elasticsearch scripts would be written in a language such as JavaScript. This made it easy for a hacker to insert malicious scripts into a database. Painless brings an end to those sorts of shenanigans, making it much harder to bring down a cluster.
Summary
Elasticsearch is one of the most popular and scalable database solutions on the market. However, it’s notorious for its role in data breaches. Many of these breaches were easily preventable and this article has looked at a few of the most common security lapses that lead to such breaches.
We’ve seen that many cases of unsecured databases result from developers forgetting to change Elasticsearch’s default configuration before making the database live. We also looked at the tandem issue of unsecured databases being live on the web, where anyone with the appropriate tools could find them.
Recently, Elasticsearch have taken steps to reduce this by including security features in their free tier so programmers are encouraged to consider security early. Hopefully this alone provides developers a powerful incentive to address the above two issues.
Other issues we looked at were the worryingly common habit of storing passwords as plain text instead of salting and hashing them and the risks of not having a secure execution policy for scripts. These two problems aren’t Elasticsearch specific and are solved by common sense and cybersecurity best practice.
In conclusion, while Elasticsearch has taken plenty of recent steps to address security, it’s your responsibility as a developer to maintain database security.
 The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first