The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

Observability is one of the biggest trends in technology today. The ability to know everything, understand your system, and analyze the performance of disparate components in tandem is something that has been embraced by enterprises and start-ups alike.
What additional considerations need to be made when factoring in cyber resiliency? A weekly review of the headlines reveals a slew of news covering data breaches, insider threats, or ransomware. The latter is particularly of concern, with multinationals and government institutions having their precious data ransomed for millions of dollars of cryptocurrency by faceless hackers.
In this article, we’ll examine two stances on the relationship between observability and cyber resiliency. First, we will look at the cyber resiliency considerations you need to be mindful of when implementing and configuring your observability solution. Then, we’ll move on to examining how a correctly deployed observability solution can empower your organization’s cyber resiliency.
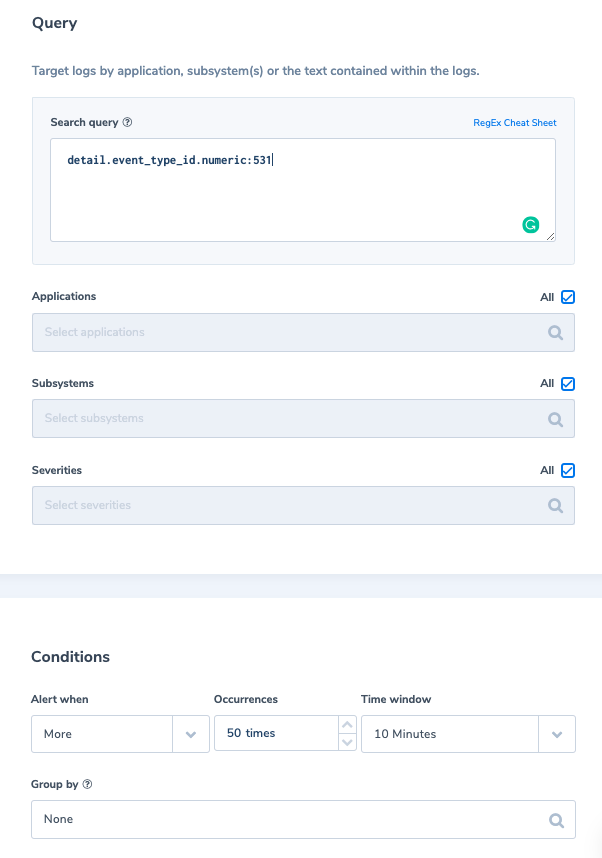
Log data – cyber resiliency considerations
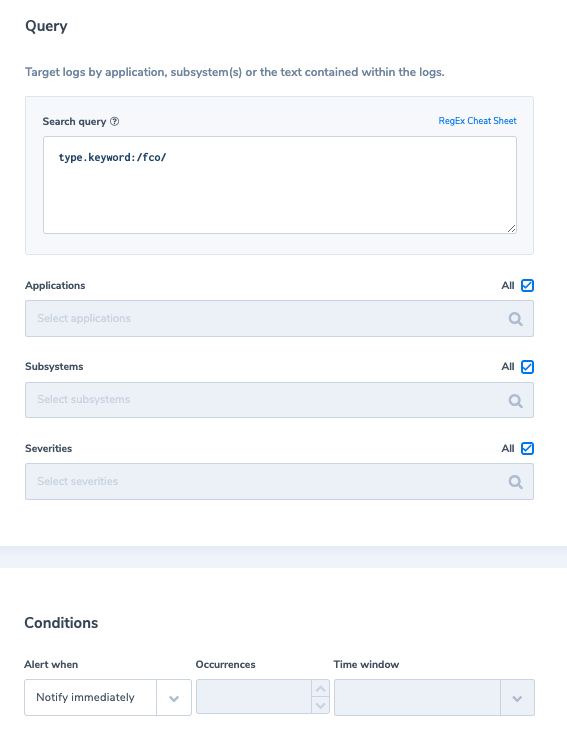
Logs are the indicators of what’s going on with your system. When they aren’t inside an observability platform, they are just rows and rows of raw textual data in a database. When examining the NIST Cyber Security Framework, logs are a big part of both the ‘identify’ and ‘detect’ pillars. The reason for this is simple. Logs are critical when it comes to identifying when a system is compromised.
How long should you keep your logs?
According to IBM, a company takes on average 197 days to identify a security breach. This means that a hacker could reside in your system, undetected, for well over half a year. If your log data is going to be a pivotal part of identifying an attack, as well as diagnosing one, you need to keep hold of them. As a guide then, any critical system logs (as well as any web or application facing systems) should be retained for at least a year.
Naturally, with any storage requirement, there will be costs associated with prolonged log retention. There are several ways that you can offset these additional costs, and Coralogix can help you understand the total cost of ownership associated with longer retention.
However, with the average cost of a data breach in 2020 coming in at $3.86 million, and knowing that you can save $1 million by containing a breach in under 30 days, it might be worth spending a little more on storage for your logs.
Securing your logs
If logs are one of the primary ways of detecting a security breach or understanding the impact of a security breach, then you have to ensure they are stored securely. This enables easier forensic analysis of all relevant data if you suspect a security breach has taken place. Some cyber insurance companies will even require that your logs be stored in a certain way as a part of your agreement.
Log Air-Gapping
Traditionally, for ease and cost, organizations will store log data on the same system or a connected system to the one being monitored. Unfortunately, this practice can do more harm than good. As hacking attacks have become more sophisticated, hackers are increasingly altering or removing logs to cover their tracks. Air-gapping your logs off to a cloud object store, like AWS S3, is the best practice for a cyber-resilient system.
Audit Log Immutability
For the same reason as above, keeping your logs safe is important. Taking further steps, such as implementing immutability for log files, is a key consideration for cyber resilience.
Immutable audit logs are often requirements of security audits such as SOC2. Because audit logs are often indicators of which user accessed which database or application, or changed fundamental configurations, you should consider making them more resilient with immutability.
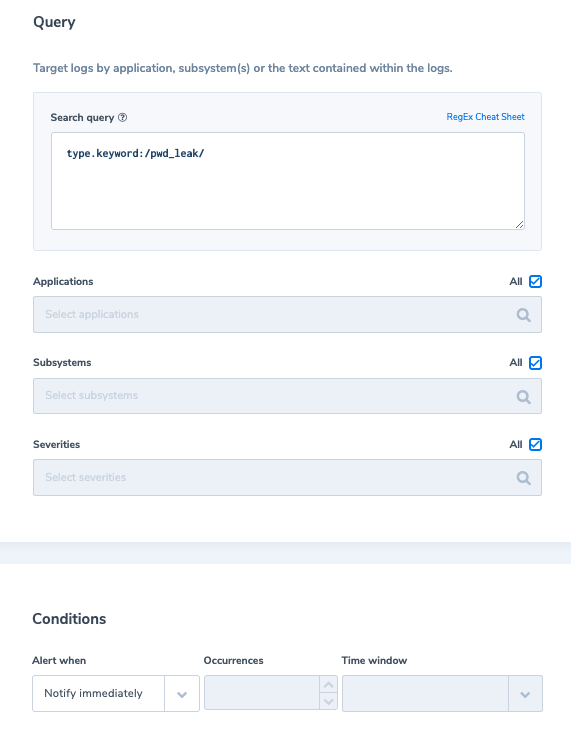
Sensitive Data in Logs
Keeping sensitive data in logs is a big no-no. Log data with credit card details, passwords, or other personal information that isn’t natively obscured or encrypted can cause you big issues. There are a few different ways that you can avoid security breaches in log data.
Password hashing, encryption, and salting are all options for decreasing the possible sensitivity of your log data. However, it may take a few more serious cybersecurity incidents before organizations treat log data with the same security considerations as they do production data.
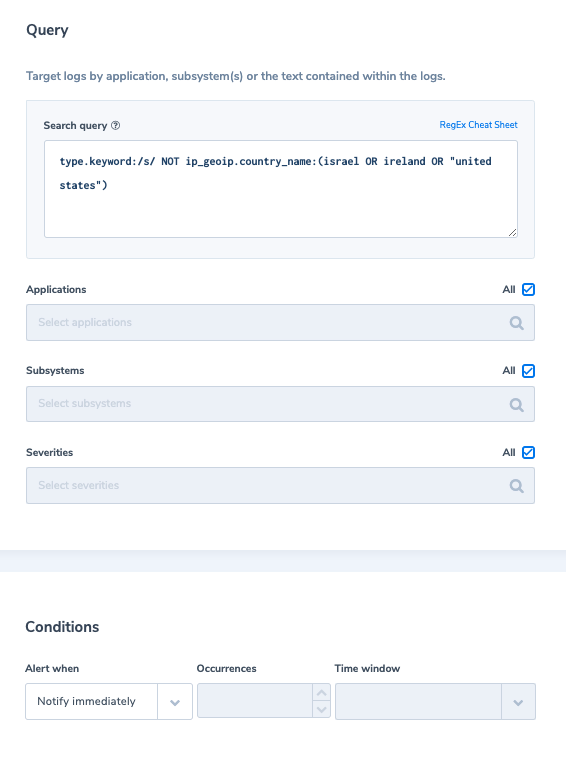
Observability for Cyber Resiliency – DDoS attacks
From 2019 to 2020, there was a 20% rise in DDoS attacks. Netscout went as far as to attribute the pandemic conditions to this rise, where users are overly reliant on eCommerce and streaming services, which are easy prey to such attacks.
A DDoS (distributed denial of service) attack is effectively where one malicious actor or group seeks to overwhelm a platform or service with traffic from an unmanageable and unforeseen number of sources. Cloudflare is widely regarded as one of the leaders in enterprise-grade DDoS protection. It can be used in conjunction with other aspects of your system, such as network load balancers, to manage and mitigate such attacks.
Coralogix for DDoS detection and prevention
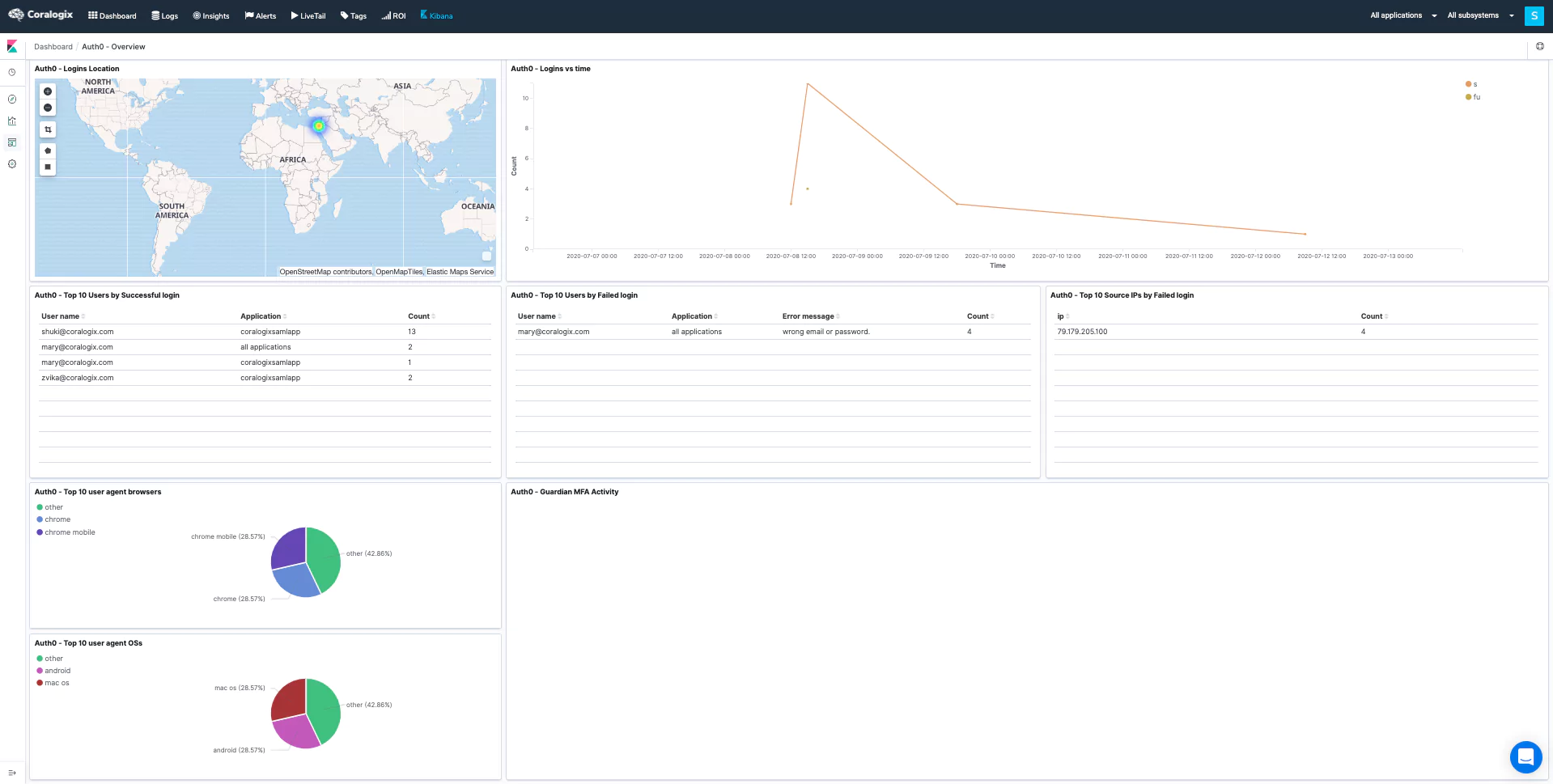
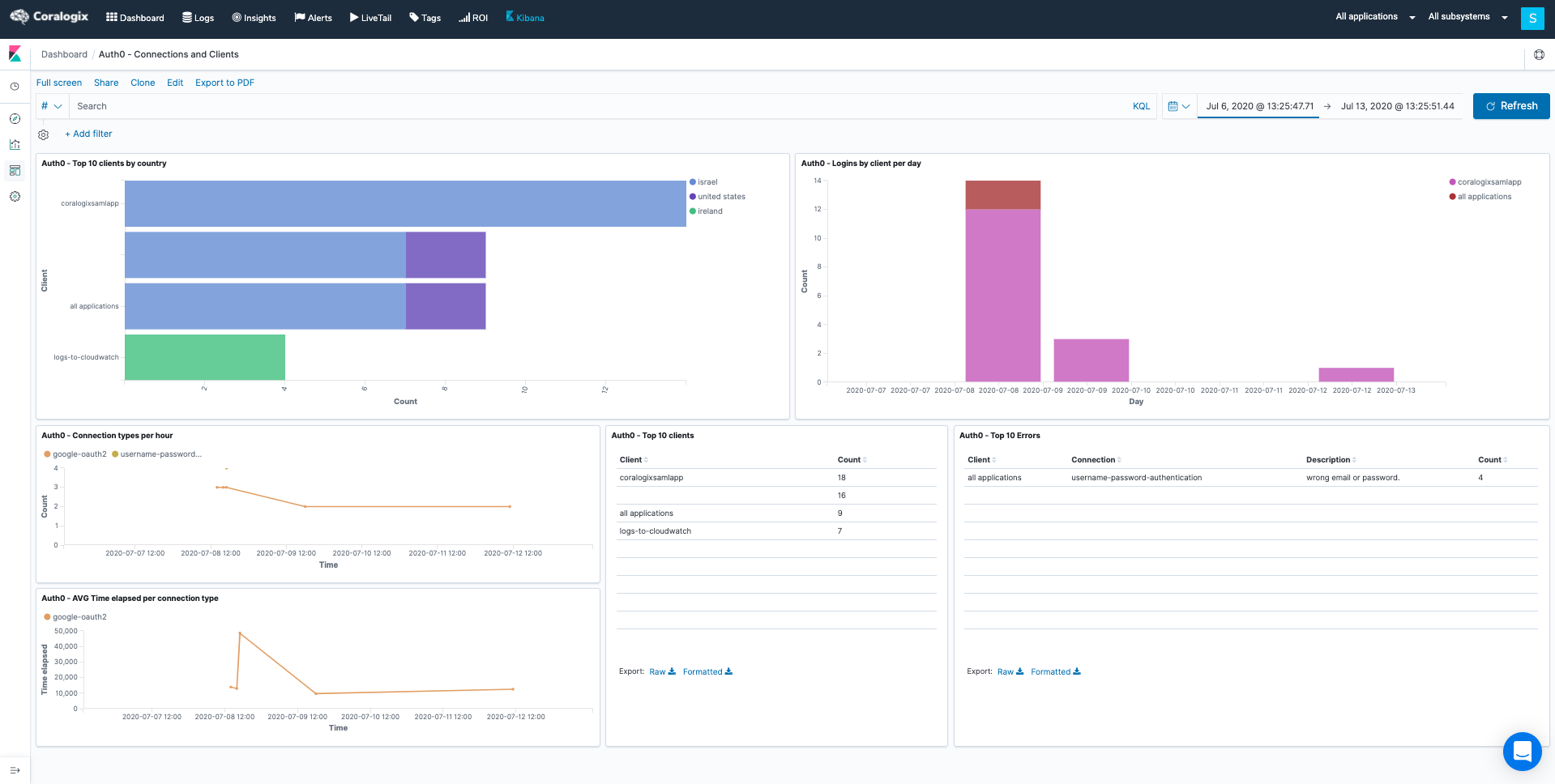
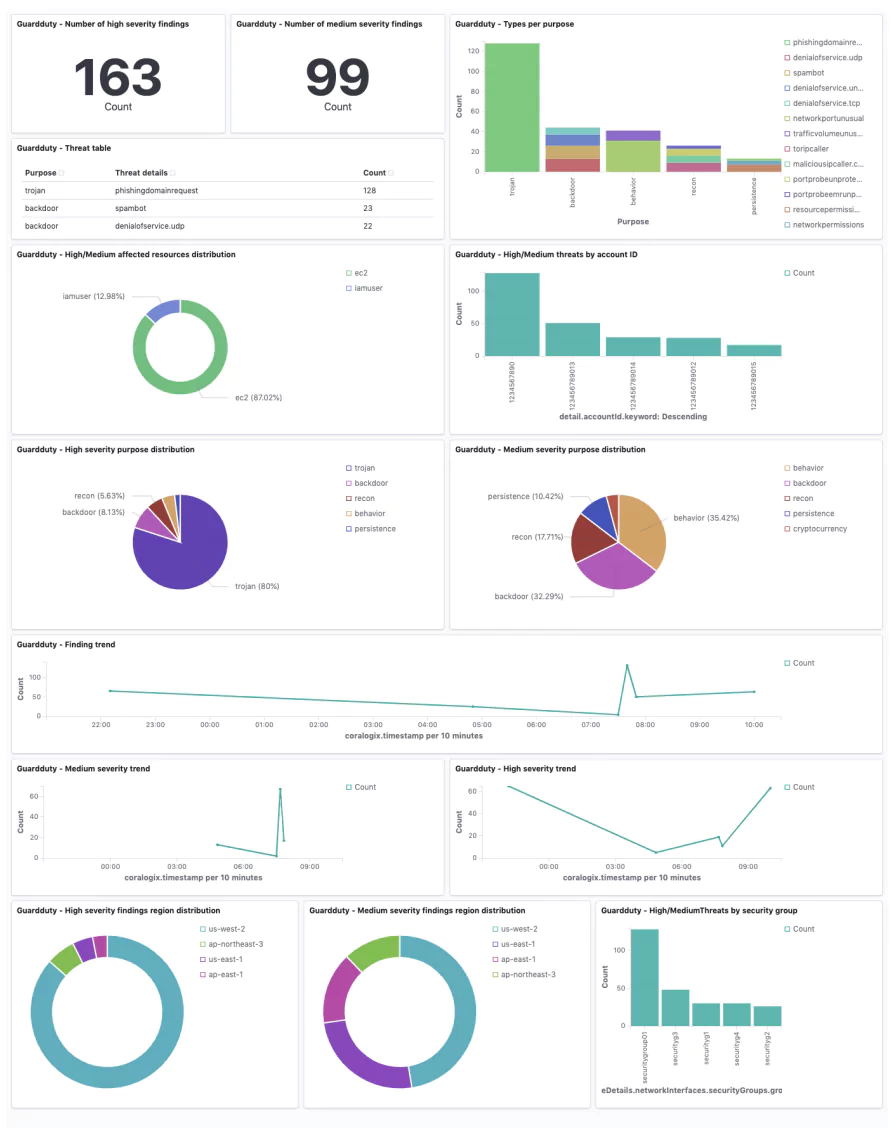
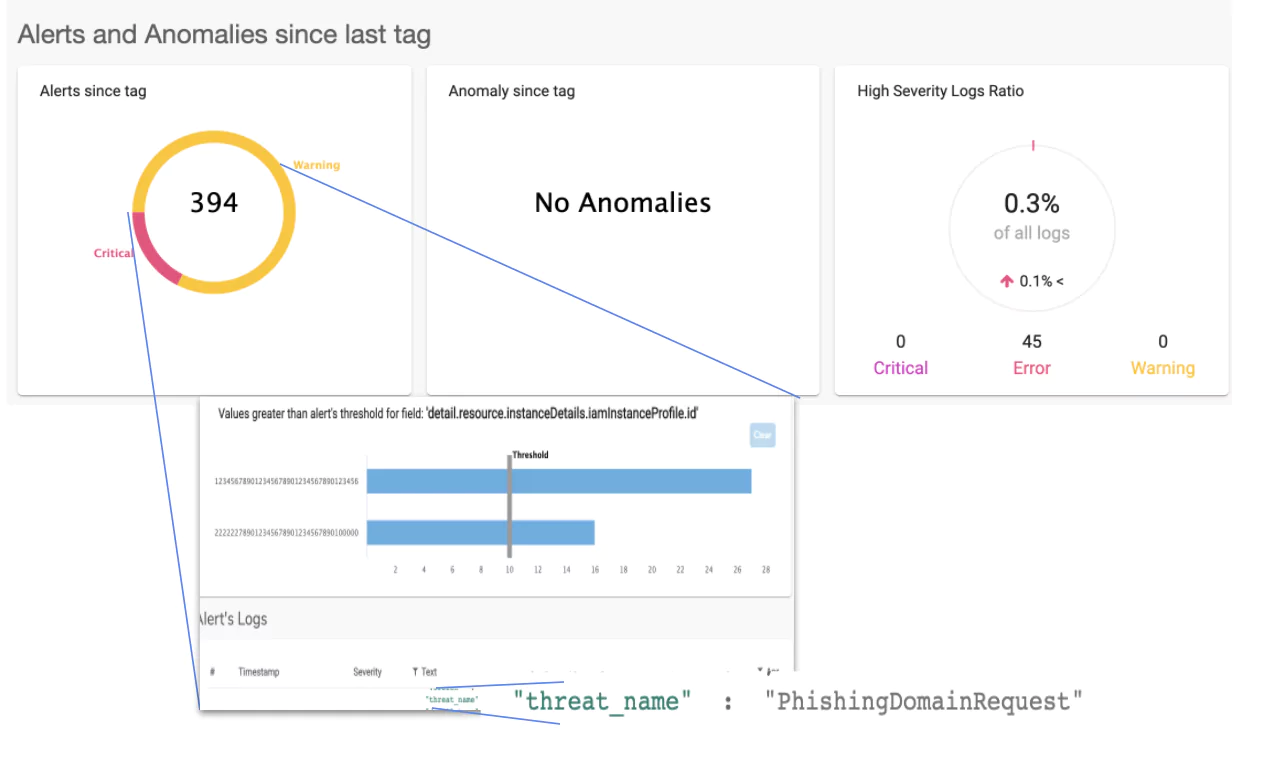
Observability, when properly deployed and understood, has the opportunity to be a huge asset in your cyber resilience toolkit. Coralogix has integrations with Cloudflare and Cloudflare’s audit log function. By combining data from Cloudflare with other relevant metrics, you can effectively enable an early DDoS warning system.
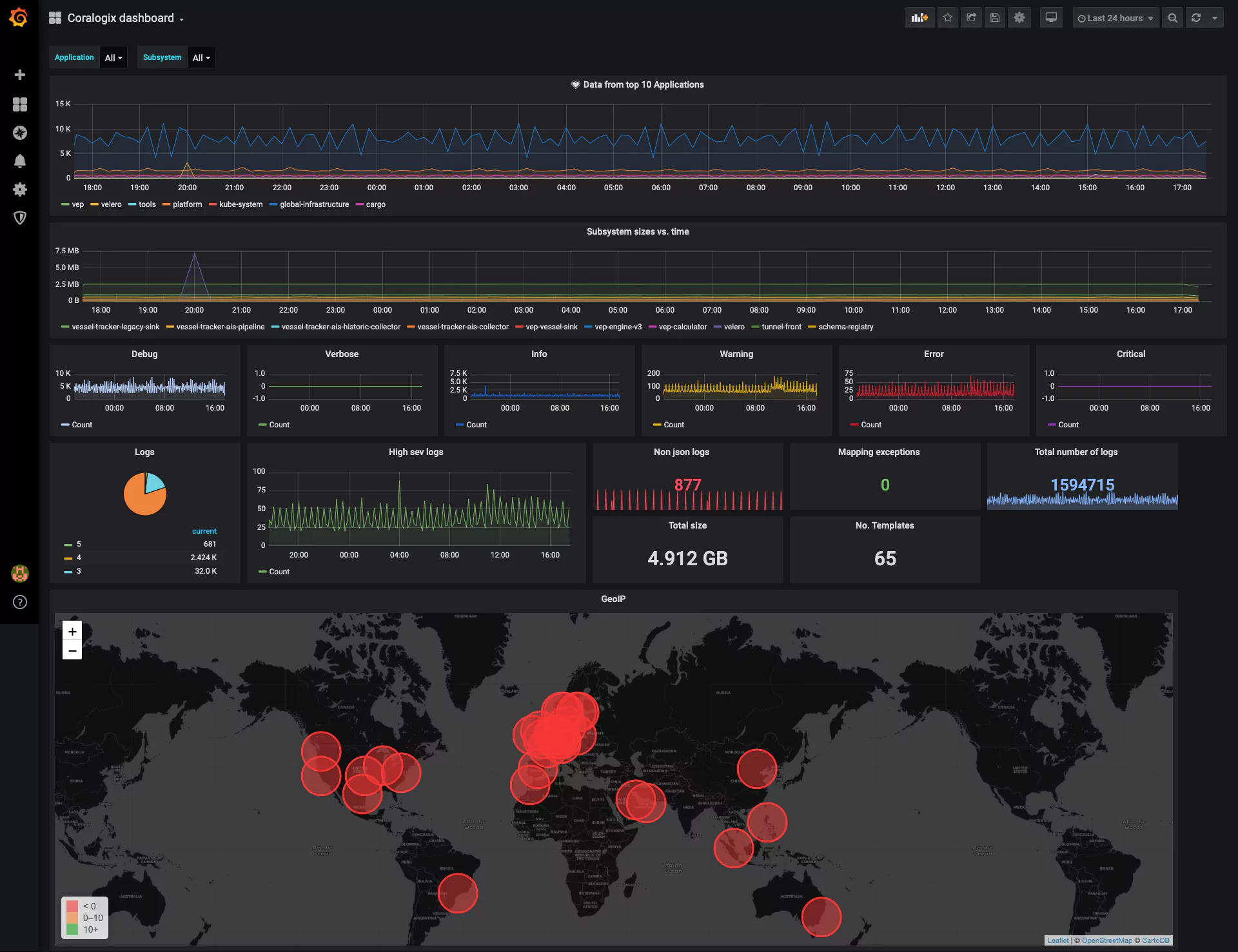
For example, you might seek to use the Security Traffic Analyzer (STA) to collect data from the load balancers within AWS. This data can provide you with a full readout on the security posture of your organization’s AWS usage.
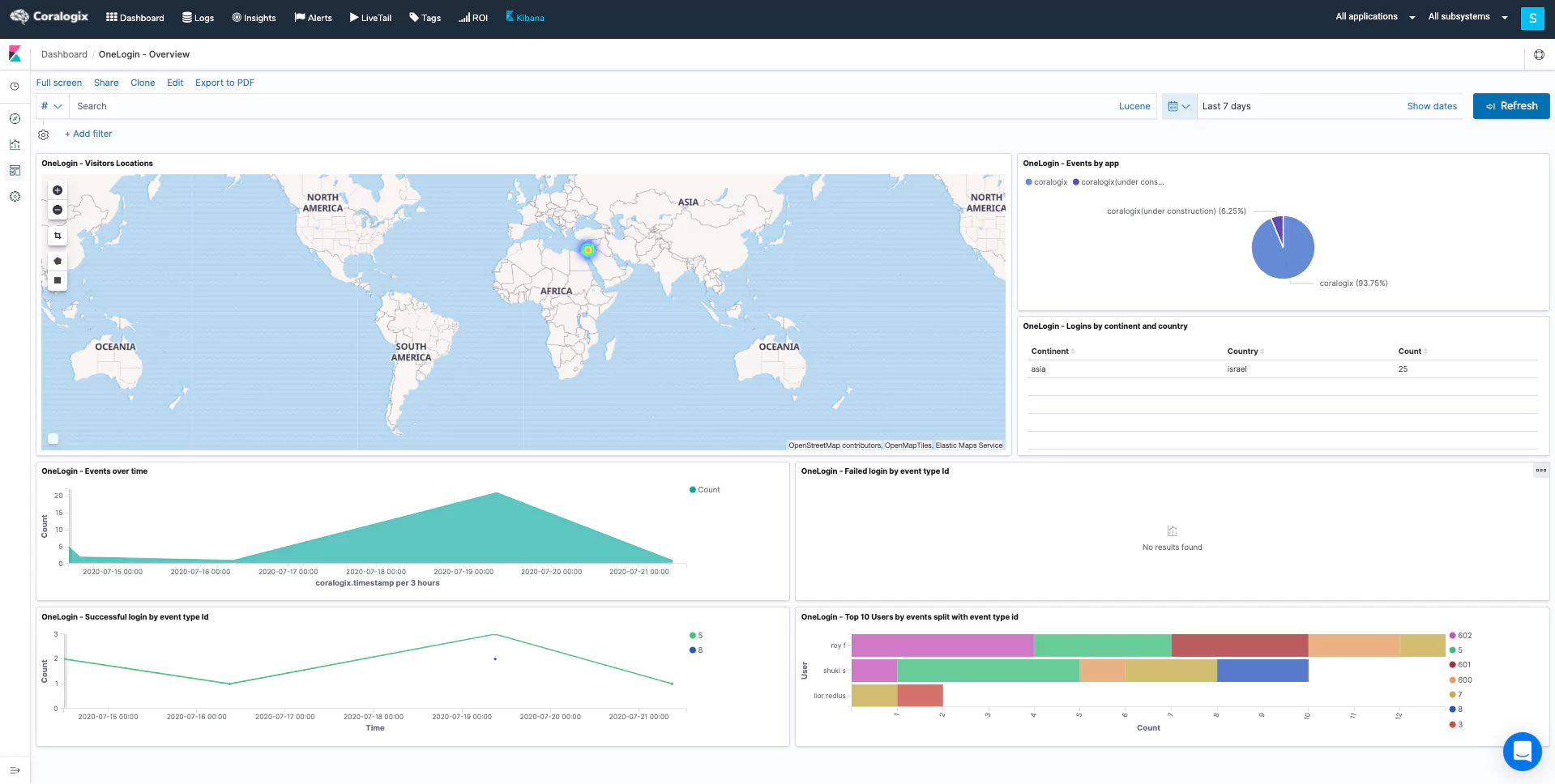
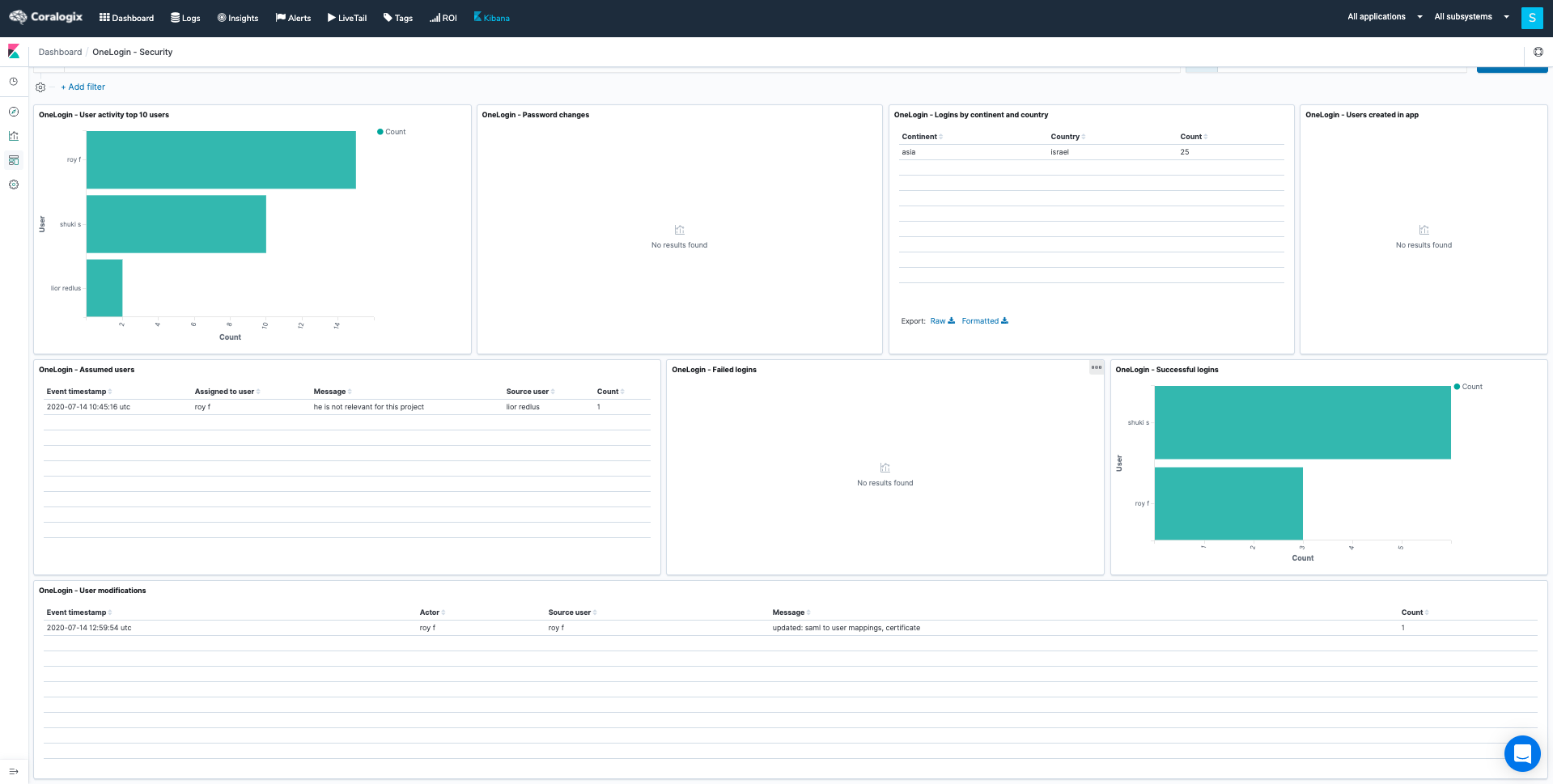
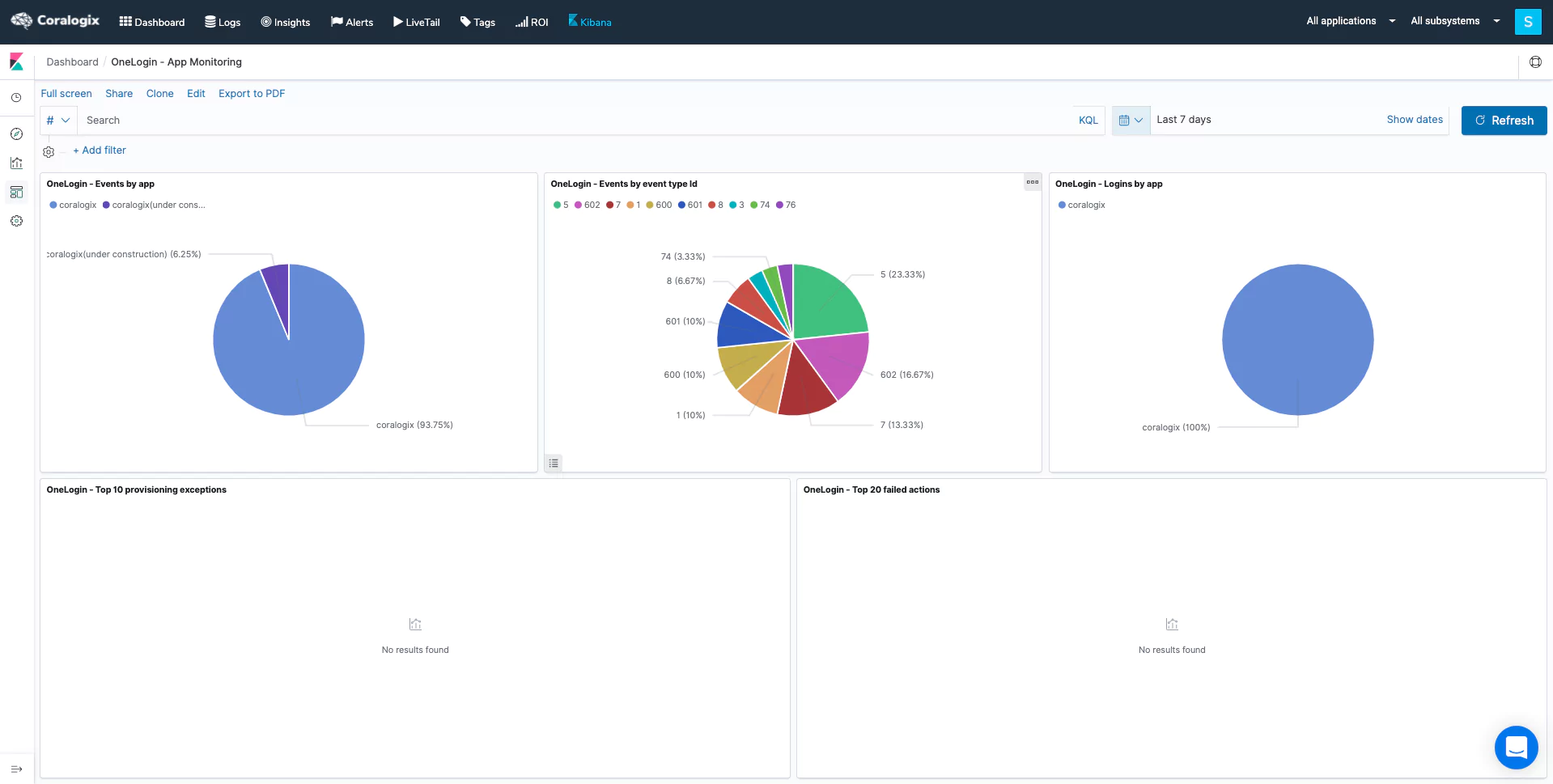
The combination of STA and Cloudflare data in the Coralogix dashboard gets to the heart of why observability is powerful for cyber resiliency. The ability to cross-analyze these metrics in a visualization tool gives you real-time insights into threats like DDoS attacks, allowing you to react effectively.
Observability for Cyber Resiliency – the AI advantage
As discussed earlier in this article, hackers can exist in your system undetected for months at a time. One of the aspects of the NIST Cyber Security Framework’s ‘detect’ pillar is to “establish baseline behaviors for users, data, devices, and applications.” This is because, in order to identify nefarious activity, you need to know what normal looks like.
The problem with a loosely coupled multi-component microservices architecture is that there are a huge number of parts, devices (in the case of IoT), applications, platforms, users, and networks that are all generating data. Manually, it would be nearly impossible to compile this data and establish a baseline intelligent enough to deal with various fluctuations.
Coralogix and AI as-a-Service
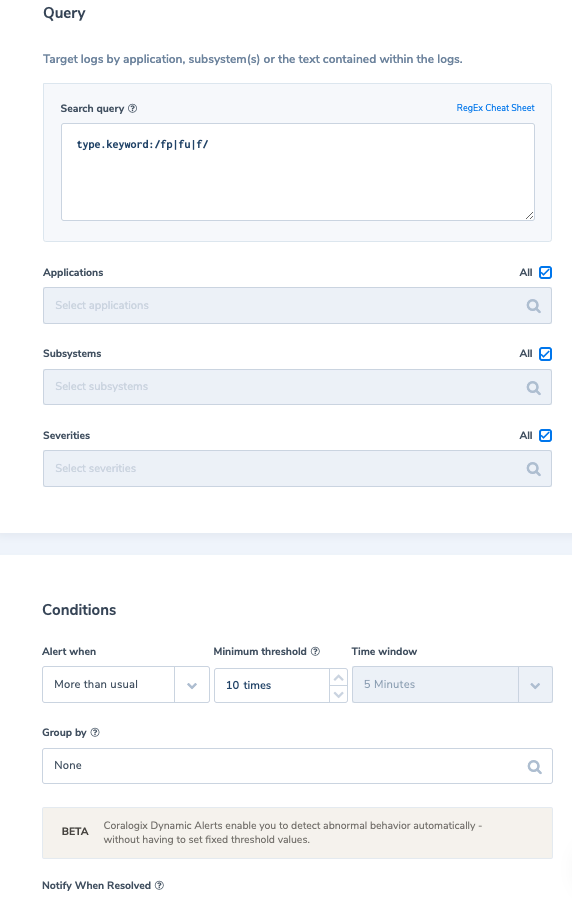
As part of the Coralogix platform, you can benefit from state-of-the-art AI tooling to help with anomaly detection in monitoring data. Error Volume Detection creates a baseline of all errors and bad API responses across all components in a system and correlates those metrics in relation to time.
Flow Anomaly analyzes the typical flow of logs as they are returned and alerts the user if that ratio or pattern is broken. Again, this AI-powered insight tool creates an intelligent and flexible baseline automatically, ensuring that if things are amiss you’re alerted immediately.
Both of these tools, inherent in Coralogix, give you AI-powered insights into what is normal in even the most complex of systems. This level of baselining is critical for cyber resiliency and harnesses all of the benefits of observability to get you there.
Summary
In this article, we’ve talked about how you need to handle monitoring data (in particular logs) to be more cyber resilient. Logs are going to be your best friend when you’re hunting for an attacker or diagnosing a security breach. That’s why they should be handled with the same care and caution as production data (although they rarely are). Organizations that identify cyber-attacks in under 30 days save on average $1 million, and it’s your logs (stored unfettered) that are going to propel you toward that outcome.
We’ve also looked at how you can harness monitoring data to empower your organization’s cyber resiliency. By monitoring everything, not just firewalls and security components, then you can get a real insight into when things might be awry in your system. This is one of the fundamental principles of observability.
Observability, when done right, gives you the ability to analyze disparate components and their performance within your system. This is invaluable for cyber resiliency, such as in the instance of a DDoS attack.
Additionally, observability platforms like Coralogix have built-in AI technology that baselines your system’s “normal” and highlights when something deviates from the norm. Manual approaches simply cannot carry out that level of analysis or detection on so many sources of data, especially not in real-time.