The new standard of observability is here. Discover Olly, the industry’s first
The new standard of observability is here. Discover Olly, the industry’s first 

In the intricate web of modern software systems and full-stack observability, knowing how requests flow and interact across distributed components is paramount. Distributed tracing tools can help you.
To better understand how distributed tracing works and benefits, here’s our selection of top distributed tracing tools to choose from.
What is distributed tracing?
Tracing is the process of recording the sequence of activities and events within a software system. It involves capturing data points at each stage of execution to create a detailed log of what’s happening.
The detailed log is called a trace and usually contains the interactions, dependencies, and timings of various components as they process your request. For example, imagine you’re buying a product from an online store. Behind the scenes, your request goes through a series of different steps, including checking your info, making sure the item is available, paying, confirming your order, and shipping.
Distributed tracing is simply tracing applied to a distributed system, for instance a microservices application. Each microservice, when processing a request, generates a trace, which contains valuable information such as timestamps, unique identifiers, and metadata about the request and its associated interactions. These traces are then propagated across the system and collected centrally, usually by a tracing tool or platform.
Why is distributed tracing important?
Distributed tracing offers a range of valuable benefits that enhance development, monitoring, troubleshooting, and overall microservices performance. Here are some key advantages:
- End-to-end visibility: Tracing provides a detailed and visual representation of how requests flow through a system’s various components. This visibility allows developers and operations teams to understand the complete journey of data, from its origin to its destination.
- Performance optimization: By tracking the timing and interactions of requests within a distributed system, tracing helps identify performance bottlenecks, latency issues, and areas for optimization. This information empowers teams to make informed decisions on how to enhance system efficiency.
- Issue detection and debugging: When an issue occurs, tracing allows developers to trace back the path of a request, helping identify the root cause of errors, bugs, and unexpected behaviors. Tracing accelerates debugging, reduces mean time to resolution (MTTR), and minimizes downtime.
- Microservices: In microservices architectures, understanding how services interact is essential. Tracing provides insights into the intricate interactions between microservices, aiding in managing the complexities of distributed systems.
- Resource allocation: With tracing data, developers can determine resource utilization at different stages of request processing. The information helps in optimizing resource allocation, avoiding contention, and ensuring smooth operation.
- Capacity planning: Tracing assists in identifying peak load times and potential stress points in the system. The information is critical for effective capacity planning and scaling resources as needed.
- Change impact assessment: Before making changes to a system, tracing can simulate the effects of those changes on requests. This allows teams to assess potential impacts and make adjustments if necessary.
- Proactive monitoring: Real-time tracing allows for proactive monitoring of the system’s health. Teams can set alerts for unusual behavior, enabling prompt response to anomalies before they escalate.
Top 10 distributed tracing tools
To help you find the right distributed tracing tools, here are some questions to consider. Are you focused on performance optimization, troubleshooting, or both? Are you dealing with a few microservices or a large, complex architecture? Do you want real-time monitoring and/or historical analysis? What kind of tech stack and budget do you have?
Once you’ve answered the above, check out these 10 best distributed tracing tools you can choose from.
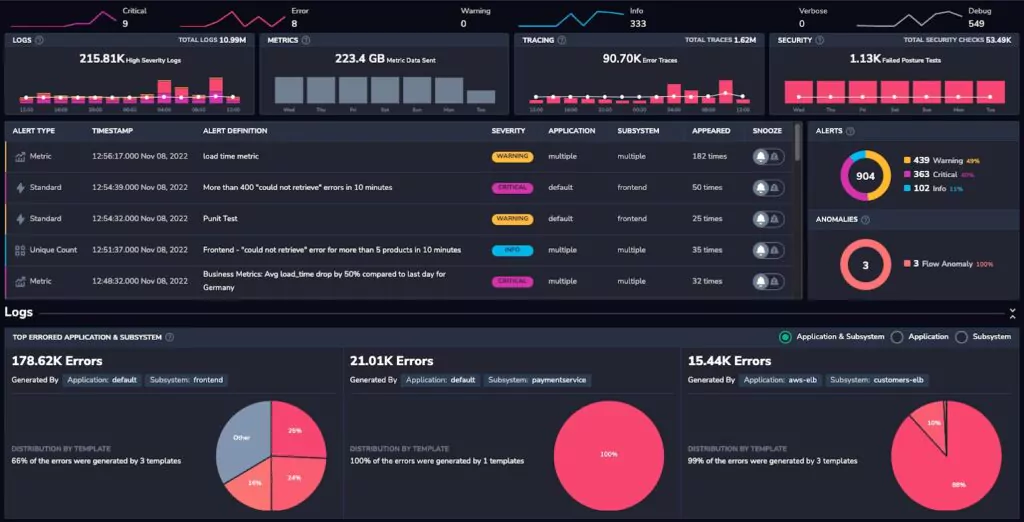
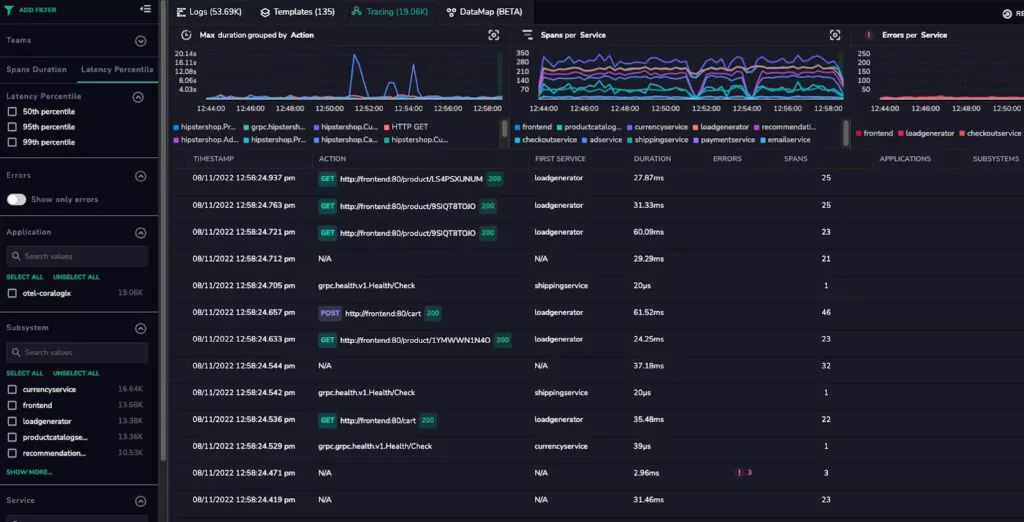
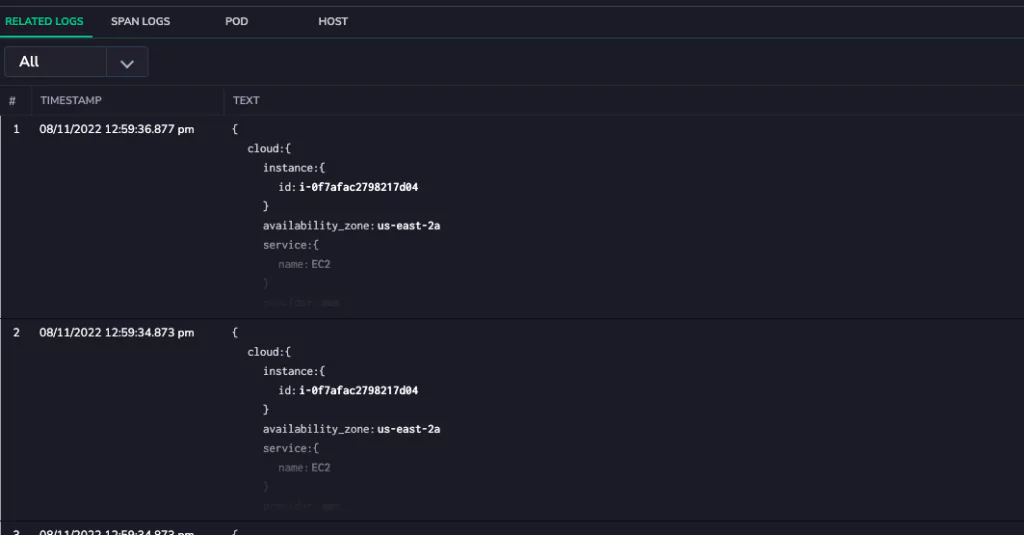
1. Coralogix
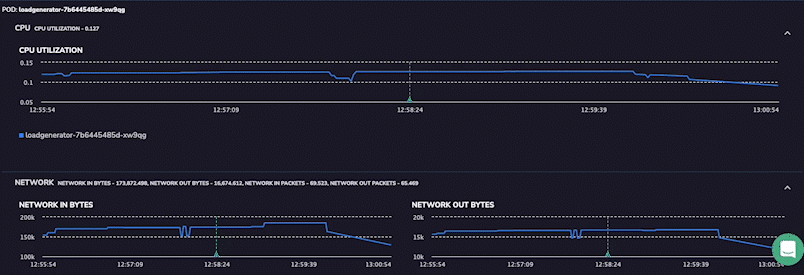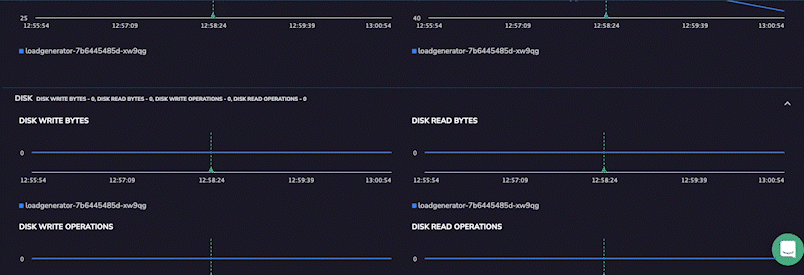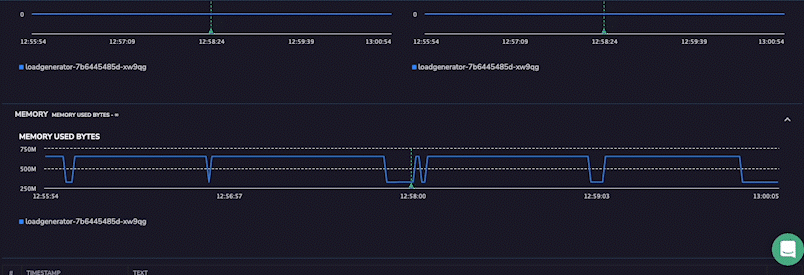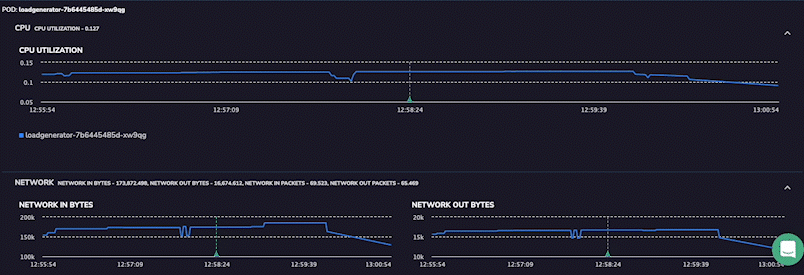
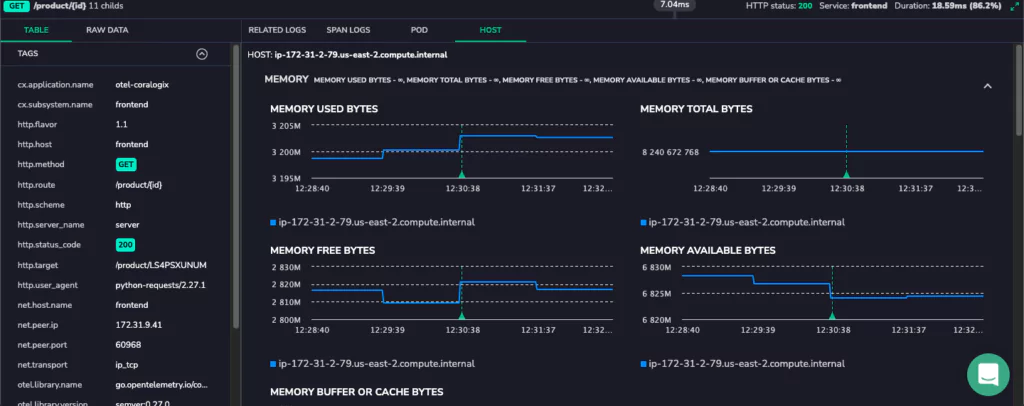
Coralogix is suitable for organizations that require end-to-end visibility into the interactions and performance of their microservices-based applications. The platform lets you optimize system performance, identify bottlenecks, troubleshoot issues, and more.
Coralogix tracing features include high scalability, real-time observability, and intelligent alerting. It’s designed to handle large-scale systems and provides instant insights into system behavior.
2. Jaeger
The platform offers detailed trace visualization, service dependency graphs, and integration with popular observability platforms. However, Jaeger might require more configuration and setup effort compared to hosted solutions and might not be the best fit for organizations seeking a fully managed tracing solution.
3. Zipkin
The platform offers distributed tracing solution and is known for its simplicity. That being said, Zipkin lacks some advanced features found in more robust tracing tools, thus not the best choice for large-scale systems with complex requirements.
4. OpenTelemetry
The platform offers a standardized and vendor-neutral approach to instrumenting and collecting tracing data across various languages and frameworks. It provides an API and instrumentation for different programming languages. However, it might not offer all features found in specialized tracing solutions.
5. Datadog
The platform offers integration between traces, metrics, and logs, but at a cost. Datadog has a steeper pricing curve compared to standalone tracing tools, making it less suitable for smaller budgets or simpler use cases.
6. New Relic
The platform provides end-to-end visibility with APM and distributed tracing integrated. Although it’s not the best choice for organizations focused on distributed tracing without the need for comprehensive APM capabilities.
7. Instana
The platform employs automatic instrumentation and AI-powered root cause analysis. However, Instana’s focus on comprehensive observability might be overkill for organizations seeking a lightweight or simpler tracing solution.
8. LightStep
The platform is to designed to handle high-cardinality data with precision, and more. That being said, the tool is a steeper learning curve due to certain features for applications that require basic tracing functionality.
9. Honeycomb
The platform handles high-cardinality data, providing interactive trace visualizations. At the same time, organizations looking for a more traditional, metrics-focused observability approach, could find it less suitable for their needs.
10. Dynatrace
The platform offers automatic discovery and instrumentation of services. But it could create a challenge for simpler applications that primarily need standalone distributed tracing capabilities, without the comprehensive features of an observability platform.