
Monitoring of Event-Driven System Architecture


Event-driven architecture is an efficient and effective way to process random, high-volume events in software. Real-time data observability and monitoring of event-driven system architecture has become increasingly important as more and more applications and services move toward this architecture.
Here, we will explore the challenges involved in monitoring event-driven systems, the key metrics that should be monitored, and the tools and techniques that can be used to implement real-time monitoring, including Coralogix’s full-stack observability platform–letting you monitor and analyze data with no limitations.
We will also discuss best practices for designing event-driven systems that are easy to monitor, debug, and maintain.
What is event-driven architecture?
Event-driven architecture is a software architecture pattern emphasizing event production, detection, and consumption. Events are characterized as a change in the system or actions taken by an external actor. Events can be triggered by anything from a user logging into your website to an IoT device pushing data to your platform. Events are generally unpredictable by nature, so reacting to them with traditional polling architecture can be computationally heavy.
In an event-driven architecture, components within the system communicate by publishing events to a central event bus or message broker, which then notifies other components that have subscribed to those events. These components can then appropriately react to the event for their role in the system. The nature of this architecture lends well to microservice architectures.
The advantages of event-driven architecture include improved scalability, loose coupling, and greater flexibility, and it is handy for systems that need to handle large volumes of data and respond quickly to changing conditions. When you have loosely coupled applications, your teams can have better cross-team collaboration and can work more independently and quickly.
When should you use event-driven architecture?
Event-driven architecture is most efficient when you have a system that must respond quickly and efficiently to changing conditions, handle large volumes of data, and scale horizontally.
Real-time processing can be done in a very efficient and effective manner using event-driven architecture. These architectures can quickly handle large volumes of data, making them ideal for real-time processing in a production environment working at scale. Processing can be used to:
- Analyze user behaviors on a webpage
- Detect security threats
- Record input data events such as sales
- Act upon IoT sensor data
AWS tools to support event-driven architecture
Amazon Web Services (AWS) provides several services and tools that support event-driven architecture and enable developers to build scalable, flexible, and responsive applications. Here, we will focus on AWS Pipes, AWS EventBridge, and AWS Kinesis. These services do not need to be used together, but complement each other for an effective event-driven architecture design.
AWS EventBridge Pipes
Pipes is a service on AWS, becoming generally available with the full feature set for AWS users in December 2022. The pipes service allows you to create connections between services by creating streams between services without needing to create integration code.
Pipes use managed polling infrastructure to fetch and send events to configured consumers. Events maintain source event order while allowing developers to customize the stream’s batch size, starting position, and concurrency. Pipes also have configurable filtering and enrichment steps, so data flowing through the pipe can be blocked if it is not relevant, and can be enriched with more data before reaching target consumers. The enrichment step can fetch enrichment data using AWS Lambda, AWS API Gateway, or other AWS services.
AWS EventBridge
EventBridge is a service linking multiple AWS producers and consumers together while allowing data filtering for only relevant data. EventBridge provides fast access to events produced by over 200 other AWS services and your client applications via API. Once in EventBridge, events can be filtered by developer-defined rules. Each rule can route data to multiple targets that are appropriate for that data. Rules can also customize event data before sending it to targets.
EventBridge was built for scale applications and can process hundreds of thousands of events per second. Higher throughputs are also available by request. EventBridge also recently added a replay feature to rehydrate archived events to help developers debug and recover from errors.
AWS Kinesis
Kinesis is a managed, real-time, scale streaming service provided by AWS. Kinesis can take streaming data at high volumes and has controls in place that help data processing work effectively. Partition keys allow you to ensure similar data are processed together, and sent to the same Lambda instance. Back pressure features ensure Kinesis does not overrun sink points with limited resources or that are throttled. Kinesis can also replay events up to 24 hours in the past if necessary to avoid data loss or corruption.
Kinesis, however, does not support routing. All data in a stream is sent to all configured trigger points. Producers (data sources) and consumers (data endpoints) are inherently tied together. Depending on the consumer, there may be wasted data where a consumer does not need to process certain data so it is dropped on the floor. When every millisecond of processing costs, this is less than ideal. There are also limits to the number of consumers available per Kinesis stream. While users can configure multiple, every new consumer increases the likelihood of throttling in the stream, increasing latency.
A sample event-driven architecture
The high-level architecture for an event-driven platform could resemble the setup below. In this architecture, an API Gateway is used to collect events. They directly flow through SQS, EventBridge Pipes, and EventBridge rules before reaching processing that involves developer code. Along this flow, data could be transformed if needed before storage in either OpenSearch or S3. Lambdas can be triggered by Kinesis DataStreams or directly by EventBridge rules for further processing.
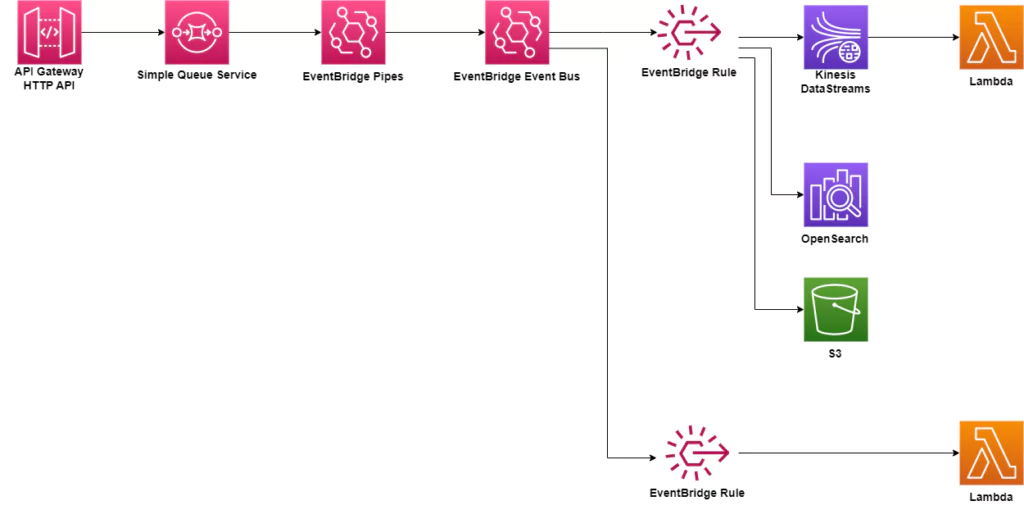
Observability in distributed, event-driven architecture
Distributed systems are notoriously difficult to troubleshoot since each service acts individually. The system depicted above uses several discrete services which operate independently, and each can provide a point of failure. DevOps teams need to track data as it flows through these different software systems to effectively troubleshoot and fix errors. By tracing data, teams can detect where data is bottlenecked and where failures are occurring. Logs and metrics will show how services function individually and in response to one another. The more quickly teams visualize issues, the more quickly they can be fixed. Reduction of downtime and errors is the end goal of every software team.
Observability methods must be integrated to complete the building of an event-driven architecture. Various tools exist within AWS and with external, full-stack observability platforms like Coralogix. Software must be integrated with the ability to generate observability data (logs, metrics, and traces). This data can be utilized within AWS and exported to observability tools for further analysis. With a distributed system such as the event-driven architecture shown, trace data is especially important, and often overlooked, to ensure analysis can be done effectively to track data as it moves through the system.
While AWS provides observability features such as CloudWatch and CloudTrail, they require manual setup to enable features like alarms. For software running at scale in production environments, external tools are required to ensure your event-driven software runs effectively with minimal downtime when errors occur. For the most effective results, data should be sent to a full-stack observability platform that can offer managed machine learning algorithms and visualization tools so troubleshooting your architecture becomes efficient and effective.
Summary
This article highlighted how an event-driven architecture can be implemented in AWS. Using the available services, minimal coding is required to stream data from external sources like API Gateway to efficient processing and storage endpoints. Data that is not required for processing can be filtered out in this process, requiring less computing time in your software.
Implementing effective observability tooling while building distributed systems is critical to reducing application downtime and lost data. AWS CloudWatch and CloudTrail can be used for monitoring an AWS software system. Coralogix’s full-stack observability platform enhances AWS’s monitoring by providing analysis on logs, traces, and metrics and providing insights and visualizations only available with machine learning.


